[논문리뷰] Accent Vector: Controllable Accent Manipulation for Multilingual TTS Without Accented Data
링크: 논문 PDF로 바로 열기
저자: Thanathai Lertpetchpun, Thanapat Trachu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Accent Vector : 사전 훈련된 모델 내에서 악센트 특정(accent-specific) 특성을 인코딩하는 조절 가능한 파라미터 시프트로, 다른 언어의 원어민(native) 발화에 대해 TTS 시스템을 Fine-tuning하여 도출됩니다. 이는 악센트 강도의 명시적인 조절과 여러 악센트의 선형적(linear) 조합을 가능하게 합니다.
- Task Vectors : 사전 훈련된 모델 내에서 Task-specific 파라미터 변화를 나타내는 표현으로, 특정 Task에 대해 Fine-tuning된 모델의 파라미터와 해당 사전 훈련된 모델의 파라미터 간의 차이로 정의됩니다.
- XTTS (Zero-Shot Text-to-Speech) : 다국어(multilingual) Zero-Shot Text-to-Speech 모델로, 17개 언어를 지원하며 언어 ID(Language ID), 텍스트 스크립트(text transcript), 참조 발화(reference speech)에 기반하여 발화 생성을 가능하게 하는 이 연구의 백본(backbone) 모델입니다.
- Low-Rank Adaptation (LoRA) : Fine-tuning 기술 중 하나로, 훈련 가능한 파라미터 수를 줄이고 과적합(overfitting) 및 파국적 망각(catastrophic forgetting)을 완화하는 데 사용됩니다.
- UTMOS : 발화의 자연스러움(naturalness)을 측정하는 자동 측정 지표로, 점수는 1(가장 부자연스러움)에서 5(인간 수준의 자연스러움)까지 범위입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
대부분의 영어 사용자가 비원어민(L2) 화자 임에도 불구하고, 현재의 Text-To-Speech (TTS) 시스템은 악센트 데이터 부족으로 인해 주로 미국식 영어 악센트(American-accented English) 를 모델링합니다. 이러한 데이터 불균형은 주류 악센트에 대한 높은 합성 품질과 달리, 소수 악센트에 대한 낮은 합성 품질로 이어집니다. 기존의 악센트 생성 접근 방식들은 대규모 악센트 발화 데이터셋 없이도 악센트 특성을 유도하지만, 악센트 강도에 대한 제어력이 제한적이며 발음 매핑(pronunciation mapping)이나 지속 시간 모델링(duration modeling)과 같은 특정 언어적 측면에 초점을 맞춥니다. 이로 인해 악센트 변화에 대한 확장 가능하고 Fine-grained한 제어가 여전히 미해결 과제로 남아 있습니다. 저자들은 악센트 특정 훈련 데이터 없이 다국어 TTS에서 조절 가능한 악센트 조작 을 가능하게 하는 프레임워크의 필요성을 해결하고자 합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
제안된 방법론은 Accent Vector 를 도입하며, 이는 XTTS2 다국어 Zero-Shot TTS 모델과 LoRA Fine-tuning 기술을 기반으로 합니다. Accent Vector 는 타겟 언어의 원어민 발화(native speech)에 대해 영어 언어 ID 및 스크립트를 사용하여 XTTS2를 Fine-tuning하여 얻은 모델 파라미터와 사전 훈련된 모델 파라미터 간의 차이로 계산됩니다 `
![Figure 1: Accent Vector Framework. The top panel illustrates the fine-tuning procedure, and the bottom panel shows the inference process for generating accented speech. During inference, a language ID token (e.g., [en]) is concatenated with the transcript and provided as input to the model.](/paper-images/2026-03-13/2603.07534/figure_1.png) Figure 1: Accent Vector Framework. The top panel illustrates the fine-tuning procedure, and the bottom panel shows the inference process for generating accented speech. During inference, a language ID token (e.g., [en]) is concatenated with the transcript and provided as input to the model.
Figure 1: Accent Vector Framework. The top panel illustrates the fine-tuning procedure, and the bottom panel shows the inference process for generating accented speech. During inference, a language ID token (e.g., [en]) is concatenated with the transcript and provided as input to the model.
. L2 악센트(예: 스페인 악센트 영어)의 경우, 모델은 원어민 스페인어 발화로 Fine-tuning되며 언어 ID는 영어로 설정됩니다. 추론 시, Accent Vector는 악센트 강도를 제어하기 위해 계수 α로 스케일링됩니다(θ_accent = θ_pre + α ⋅ T_accent). 여러 Accent Vector는 혼합 악센트 생성을 위해 선형적으로 결합될 수 있습니다(T_interpolated = Σ α_i ⋅ T_accent(i))
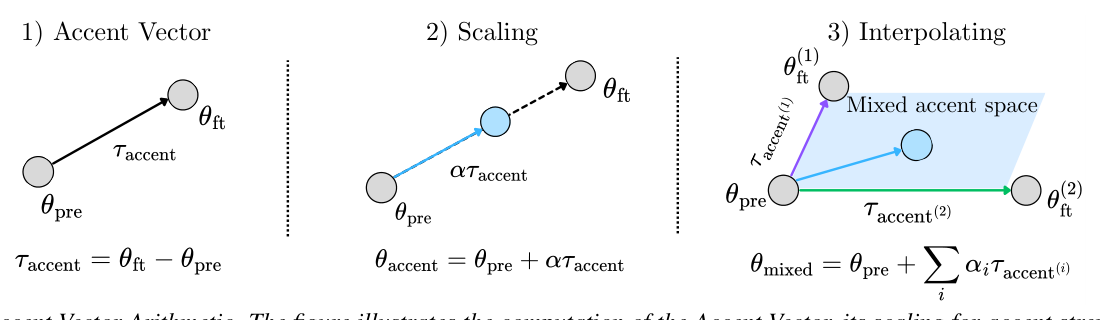 Figure 2: Accent Vector Arithmetic. The figure illustrates the computation of the Accent Vector, its scaling for accent strength control, and the interpolation of multiple Accent Vectors for mixed-accent synthesis.
Figure 2: Accent Vector Arithmetic. The figure illustrates the computation of the Accent Vector, its scaling for accent strength control, and the interpolation of multiple Accent Vectors for mixed-accent synthesis.
`.
주요 객관적 평가 결과는 다음과 같습니다:
- 악센트 변화 효과 : 영국 악센트(British Accent) 의 경우, 타겟 악센트 확률이 사전 훈련 시 23.3% 에서 Fine-tuning 후 56.7% 로 +143.83% 증가했습니다. 스페인 악센트 영어 의 경우, 15.5% 에서 39.7% 로 +156.37% 증가했으며, 힌디어 가 2.2% 에서 24.2% 로 가장 큰 증가율( +1021.29% )을 보였습니다 `
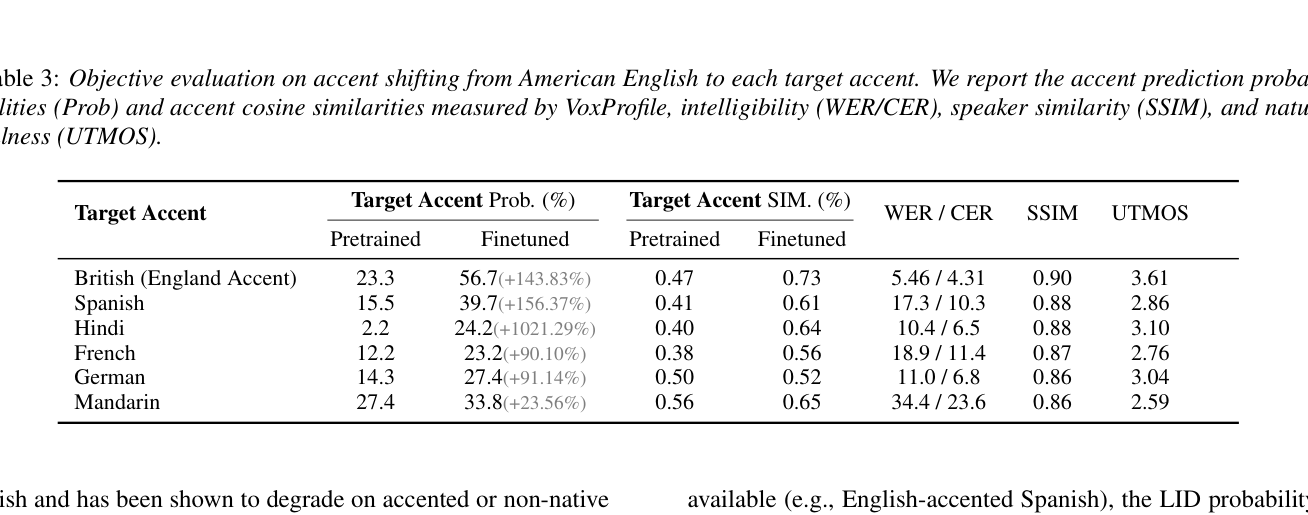 Table 3: Objective evaluation on accent shifting from American English to each target accent. We report the accent prediction probabilities (Prob) and accent cosine similarities measured by VoxProfile, intelligibility (WER/CER), speaker similarity (SSIM), and naturalness (UTMOS).
Table 3: Objective evaluation on accent shifting from American English to each target accent. We report the accent prediction probabilities (Prob) and accent cosine similarities measured by VoxProfile, intelligibility (WER/CER), speaker similarity (SSIM), and naturalness (UTMOS).
`. 모든 악센트에서 화자 유사성(speaker similarity)은 약 0.9 로 높게 유지되어 화자 정체성(speaker identity)이 보존됨을 나타냅니다.
- 비영어권 기본 언어로의 일반화 : 스페인어, 독일어, 만다린어 발화에 영국 악센트를 유도했을 때, 영어 악센트 확률(VoxProfile)과 영어 언어 확률(LID)이 상당히 증가 했습니다. 스페인어의 경우, 영어 악센트 확률이 1.20% 에서 44.69% 로, 영어 언어 확률이 0.04% 에서 38.1% 로 상승했습니다
[Table 4]. - 조절 가능한 악센트 강도 : Accent Vector 계수
α를 0에서 1 까지 스케일링했을 때, 힌디어 및 영국 악센트 영어 모두에서 악센트 확률이 단조롭게 증가 했습니다[Figure 3]. - 혼합 악센트 구성 : 스페인어와 영어 Accent Vector를 혼합할 때, 보간 계수를 변경하여 각 악센트의 상대적 강도를 연속적으로 제어 할 수 있음을 보여주었습니다
[Figure 4]. - 인간 평가 : 인간 청취자는 높은 악센트 식별 정확도(예: 미국 악센트 80% , 영국 악센트 78.46% , 힌디어 악센트 78.46% )를 달성했습니다
[Table 6]. 인지된 악센트 강도 점수(perceived accent strength scores)는 적절했고, 자연스러움 평가(naturalness ratings)는 (예: 영국 악센트 3.91 , 스페인 악센트 3.28 ) 허용 가능한 지각 품질을 나타냅니다.
4. Conclusion & Impact (결론 및 시사점)
Accent Vector 프레임워크는 악센트 특정 훈련 데이터셋 없이도 다국어 TTS 에서 조절 가능한 악센트 조작 을 위한 간단하고 실용적인 경로를 제공합니다. 다국어 백본(multilingual backbone)인 XTTS2에 LoRA 를 Fine-tuning하여 Task-space 파라미터 차이를 추출함으로써, 이 방법은 발화를 타겟 악센트로 효과적으로 전환하고, 화자 정체성을 보존하며, Fine-grained한 악센트 제어 와 유연한 악센트 혼합 을 가능하게 합니다. 이 연구는 TTS 분야에 상당한 영향을 미치며, 다양한 악센트에 대한 접근성을 넓히고, 포괄성(inclusivity)을 향상시키며, 특히 소수 악센트 영어와 Cross-lingual 악센트 조합과 같은 자원 제약적(resource-constrained) 시나리오에서 보다 미묘하고 언어적으로 정보에 기반한 발화 합성을 위한 기반을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] The Hidden Power of Scaling Factor in LoRA Optimization
- [논문리뷰] LatentSkill: From In-Context Textual Skills to In-Weight Latent Skills for LLM Agents
- [논문리뷰] SIA: Self Improving AI with Harness & Weight Updates
- [논문리뷰] LayerRoute: Input-Conditioned Adaptive Layer Skipping via LoRA Fine-Tuning for Agentic Language Models
- [논문리뷰] How Far Can Chord-Symbol Time-Series Adaptation Carry Genre Identity? Capabilities and Boundaries in Multi-Genre Chord-Symbol Modeling
Review 의 다른글
- 이전글 [논문리뷰] V_{0.5}: Generalist Value Model as a Prior for Sparse RL Rollouts
- 현재글 : [논문리뷰] Accent Vector: Controllable Accent Manipulation for Multilingual TTS Without Accented Data
- 다음글 [논문리뷰] Are Video Reasoning Models Ready to Go Outside?
댓글