[논문리뷰] Encoder-Free Human Motion Understanding via Structured Motion Descriptions
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yao Zhang, Zhuchenyang Liu, Thomas Ploetz, Yu Xiao
1. Key Terms & Definitions (핵심 용어 및 정의)
- SMD (Structured Motion Description): 조인트 위치 시퀀스를 생체역학적 규칙에 따라 자연어 텍스트로 변환한 표현 방식.
- Encoder-Free Paradigm: 학습된 Motion Encoder나 cross-modal alignment 모듈 없이, 텍스트로 변환된 SMD를 직접 LLM에 입력하는 방법론.
- LoRA (Low-Rank Adaptation): 사전 학습된 LLM의 파라미터를 고정한 채, 특정 하위 작업을 위해 일부 가중치만 미세 조정하는 효율적인 학습 기법.
- ISB (International Society of Biomechanics): 인간 관절 좌표계 정의 및 보고에 대한 국제 표준을 제공하는 기관.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 인간 모션 이해를 위한 기존의 Encoder-based paradigm이 가진 복잡성과 비효율성 문제를 해결한다. 기존 방법들은 모션 데이터를 LLM의 임베딩 공간으로 투영하기 위해 전용 모션 인코더와 복잡한 다단계 정렬 훈련이 필수적이며, 이로 인해 시스템이 특정 LLM 백본에 강하게 결합되는 한계를 가진다. 저자들은 모션 데이터를 기계적인 숫자 벡터가 아닌, LLM이 이미 이해하고 있는 신체 부위 및 동작 의미를 포함한 SMD 형태의 자연어로 표현함으로써 이러한 문제를 극복하고자 한다 [Figure 1].
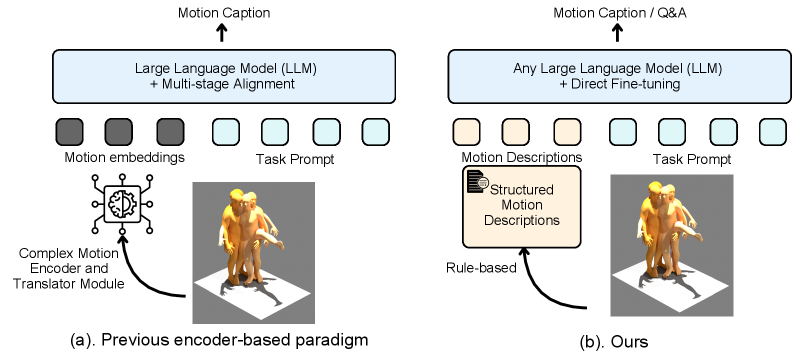
Figure 1 — Encoder-based vs. 제안 방식 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 모션을 구조화된 텍스트로 변환하는 결정론적 파이프라인과 이를 처리하는 LLM fine-tuning으로 구성된다. 제안된 SMD는 관절 각도 계산, 전역 궤적 설명, 그리고 이를 결합한 계층적 텍스트 생성 과정을 거치며, 모델이 별도의 인코더 없이 LLM의 사전 학습된 언어 지식을 활용하게 한다 [Figure 2]. 주요 실험 결과, SMD는 BABEL-QA에서 66.7%, HuMMan-QA에서 90.1%의 정확도를 기록하며 기존 state-of-the-art 모델들을 크게 상회하였다 [Table 1]. 또한, HumanML3D 캡셔닝 태스크에서 기존 방식 대비 CIDEr 점수를 40.65에서 53.16으로 약 31% 향상시켰으며, 8개 LLM 백본에서 일관된 성능을 보임으로써 뛰어난 범용성을 증명하였다.
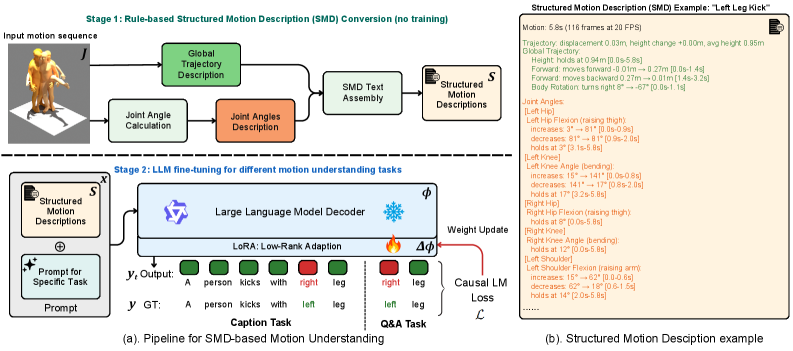
Figure 2 — 제안 모델 SMD 아키텍처
4. Conclusion & Impact (결론 및 시사점)
본 연구는 모션 이해를 위한 Encoder-Free 접근 방식을 통해 모션 데이터를 효율적으로 언어 모델에 연결하는 혁신적인 프레임워크를 제시하였다. SMD는 학습 비용을 현저히 낮추고 다양한 LLM으로의 이식성을 극대화하며, 인간이 이해 가능한 텍스트 기반 표현을 통해 모델의 추론 과정에 대한 해석 가능성(interpretability)을 제공한다는 점에서 큰 의의가 있다 [Figure 5]. 이 연구는 향후 모션 데이터 기반의 멀티모달 추론 태스크에서 모델 경량화 및 해석 가능성 연구의 중요한 토대가 될 것으로 기대된다.

Figure 5 — SMD 기반 어텐션 히트맵
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Training Large Language Models to Predict Clinical Events
- [논문리뷰] The Path Not Taken: RLVR Provably Learns Off the Principals
- [논문리뷰] Omni-AVSR: Towards Unified Multimodal Speech Recognition with Large Language Models
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] SG-OPD: Sign-Gated On-Policy Distillation via Sign-Consistency Gating and Phased Teacher Sampling
Review 의 다른글
- 이전글 [논문리뷰] EditCrafter: Tuning-free High-Resolution Image Editing via Pretrained Diffusion Model
- 현재글 : [논문리뷰] Encoder-Free Human Motion Understanding via Structured Motion Descriptions
- 다음글 [논문리뷰] Explainable Disentangled Representation Learning for Generalizable Authorship Attribution in the Era of Generative AI
댓글