[논문리뷰] EditCrafter: Tuning-free High-Resolution Image Editing via Pretrained Diffusion Model
링크: 논문 PDF로 바로 열기
저자: Kunho Kim, Sumin Seo, Yongjun Cho, Hyungjin Chung
1. Key Terms & Definitions (핵심 용어 및 정의)
- Tiled DDIM Inversion: 고해상도 이미지를 사전 학습된 T2I diffusion model의 잠재 공간으로 정확하게 역전파(inversion)하기 위해 이미지를 개별 타일로 분할하여 처리하는 기법입니다.
- NDCFG++ (Manifold-constrained Noise-damped Classifier-free Guidance): 고해상도 샘플링 과정에서 dilated convolution 사용 시 발생하는 데이터 매니폴드 이탈을 방지하고, 구조적 일관성과 텍스트 정렬을 강화하기 위해 제안된 새로운 가이드 방식입니다.
- Kernel Re-dilation: 고정된 해상도로 학습된 U-Net의 수용장(receptive field)을 확장하여, 모델의 가중치 수정 없이 고해상도 이미지 생성을 지원하는 기술입니다.
- Tuning-free: 추가적인 학습이나 미세 조정(fine-tuning) 과정 없이 사전 학습된 모델의 가중치를 그대로 활용하여 편집을 수행하는 효율적인 프레임워크를 의미합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 T2I diffusion model이 가진 고정된 학습 해상도(512×512 또는 1024×1024) 한계를 극복하고, 고해상도 이미지 편집을 수행하는 것을 목표로 합니다. 기존의 patch-wise 편집 방식은 고해상도 입력 시 객체 반복(object repetition) 문제나 타일 간 경계에서의 부자연스러운 이음새(seam artifacts)를 유발하는 치명적인 단점이 있습니다. 이러한 제약으로 인해 실질적인 고해상도 콘텐츠 제작 환경에서 기존 모델을 적용하는 데 어려움이 있습니다. 본 연구는 이러한 구조적 한계를 해결하기 위해 별도의 파라미터 조정 없이도 고해상도 이미지의 세부 디테일을 유지하며 정교한 편집이 가능한 EDITCRAFTER를 제안합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
EDITCRAFTER는 고해상도 이미지의 identity를 보존하는 Tiled DDIM Inversion 모듈과, 고해상도 잠재 공간에서 텍스트 정렬을 최적화하는 NDCFG++ 샘플링 과정을 핵심으로 합니다. 먼저 입력 이미지를 타일 단위로 역전파하여 인버전 잠재 벡터를 생성하고, 이를 결합하여 전체 고해상도 정보를 초기화합니다. 이후 ScaleCrafter에서 도입한 Kernel Re-dilation 기법을 적용하여 네트워크의 수용장을 확장하고, **NDCFG++**를 통해 노이즈 추정 과정에서 발생하는 오류를 억제하여 고품질의 편집 결과를 얻습니다 [Figure 2].
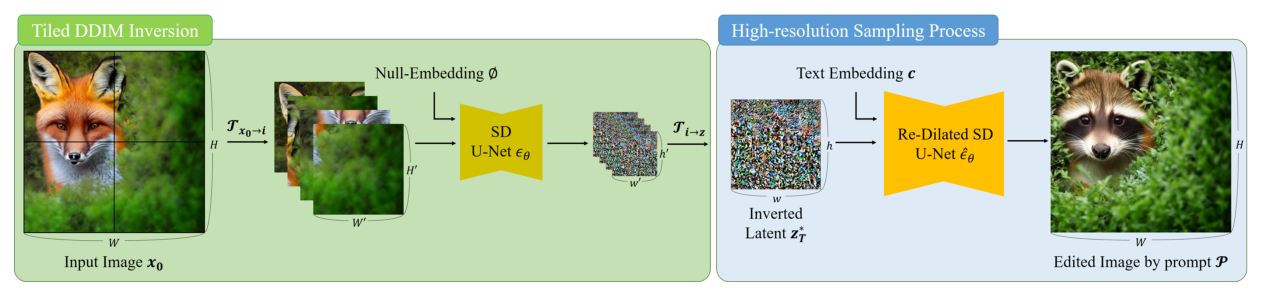
Figure 2 — 제안하는 EDITCRAFTER 파이프라인의 전반적인 구조 및 흐름을 보여주는 핵심 다이어그램
실험 결과, EDITCRAFTER는 기존 baseline인 CSD 대비 ImageReward, HPSv2, CLIPScore 등 모든 정량적 지표에서 우수한 성능을 보였습니다 [Table 1]. 특히, 4K에 달하는 초고해상도 환경에서도 객체의 형태를 효과적으로 수정하면서도 원본 이미지의 복잡한 텍스처와 세부 사항을 성공적으로 보존함을 확인하였습니다. 정성적 비교를 통해 본 방법론이 patch-wise 편집에서 자주 발생하는 객체 중복 현상 없이 정교하고 일관된 편집 결과를 도출함을 증명하였습니다 [Figure 4].

Figure 4 — 기존 방식인 CSD와의 편집 결과물 비교를 통한 성능 우위 증명
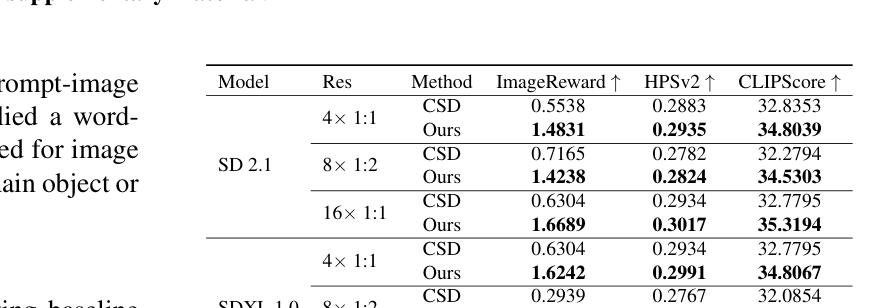
Table 1 — 다양한 해상도 설정에서의 정량적 성능 지표 비교 테이블
4. Conclusion & Impact (결론 및 시사점)
본 연구는 사전 학습된 대규모 T2I diffusion model을 활용하여 추가적인 학습 없이 고해상도 이미지 편집을 가능하게 하는 효율적인 파이프라인을 제시합니다. EDITCRAFTER는 기존 방식들의 고질적인 문제인 연산 효율성과 이미지 품질 저하 문제를 동시에 해결함으로써 산업 현장의 고해상도 콘텐츠 생성 수요에 부합하는 솔루션을 제공합니다. 이 연구는 모델의 가중치 변경 없이 구조적 유연성을 극대화했다는 점에서 향후 고해상도 생성 모델 연구에 중요한 이정표가 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Direct 3D-Aware Object Insertion via Decomposed Visual Proxies
- [논문리뷰] Learning A Unified Risk Map for Autonomous Driving in Partially Observable Environments
- [논문리뷰] Sensor2Sensor: Cross-Embodiment Sensor Conversion for Autonomous Driving
- [논문리뷰] PRISM: Prior Rectification and Uncertainty-Aware Structure Modeling for Diffusion-Based Text Image Super-Resolution
- [논문리뷰] MACE-Dance: Motion-Appearance Cascaded Experts for Music-Driven Dance Video Generation
Review 의 다른글
- 이전글 [논문리뷰] Context Unrolling in Omni Models
- 현재글 : [논문리뷰] EditCrafter: Tuning-free High-Resolution Image Editing via Pretrained Diffusion Model
- 다음글 [논문리뷰] Encoder-Free Human Motion Understanding via Structured Motion Descriptions
댓글