[논문리뷰] MMCORE: MultiModal COnnection with Representation Aligned Latent Embeddings
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yixuan Huang, Ye Wang, Jingxiang Sun, Yichun Shi, Zijie Li, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- MMCORE: 멀티모달 이미지 생성 및 편집을 위한 통합 프레임워크로, MLLM의 시맨틱 이해 능력을 확산 모델(Diffusion Model)의 시각적 생성 능력과 결합함.
- Visual Latent Embeddings: MLLM이 생성한 학습 가능한 쿼리 토큰으로, 시맨틱 정보를 압축하여 확산 모델의 조건부 입력(Conditioning signal)으로 활용됨.
- Dual-Pathway Conditioning: 고수준의 시맨틱 정보를 담은 Visual Latent Embeddings와 세밀한 지시 사항을 포함하는 Full-sequence Text Embeddings를 동시에 사용하는 조건부 입력 전략.
- Flow Matching: 본 논문에서 확산 모델을 학습시키기 위해 사용한 생성 방식의 이론적 기반임.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 MLLM의 강력한 시맨틱 추론 능력과 확산 모델의 고품질 이미지 생성 능력을 통합하면서도 학습 효율성을 극대화하는 것을 핵심 문제로 다룹니다. 기존 연구들인 Transfusion이나 BAGEL은 모델 내부에서 두 패러다임을 통합하려 시도했으나, 이미지 생성과 이해를 위한 최적화가 서로 달라 학습 효율이 저하되는 한계가 있었습니다. 특히, 고정된 쿼리 토큰만을 사용하는 MetaQueries 방식은 복잡한 프롬프트를 처리하기 위한 정보 전달 능력(Context Budget)이 제한적이고, 확산 손실 함수만으로는 MLLM과의 표현적 정렬(Alignment)이 부족하다는 문제점이 있었습니다 [Figure 5].
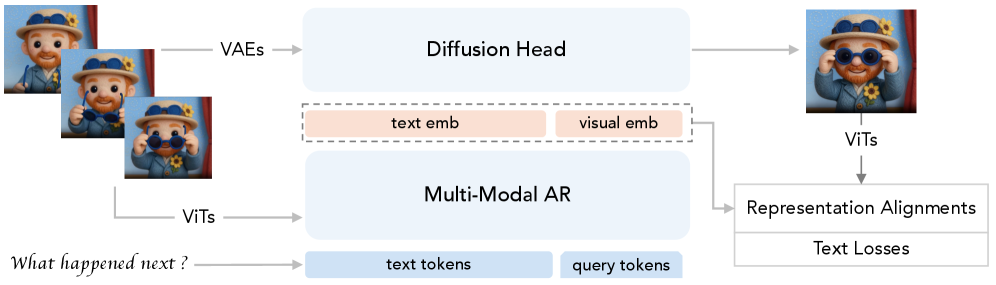
Figure 5 — MMCORE 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 MLLM을 완전하게 미세 조정(Full Fine-tuning)하고, frozen ViT 인코더의 시맨틱 임베딩을 이용한 증류(Distillation)를 통해 시각적 토큰을 정렬하는 MMCORE 프레임워크를 제안합니다. 제안된 방법론은 MLLM을 1단계에서 시맨틱 피처 예측용으로 최적화하고, 2단계에서 고정된 MLLM으로부터 받은 정보를 바탕으로 확산 모델을 학습시키는 효율적인 구조를 채택하였습니다. 정량적 실험 결과, MMCORE는 텍스트-이미지 생성 및 이미지 편집 벤치마크인 DreamBench에서 기존 Seedream 4.0 대비 우수한 프롬프트-이미지 일관성과 편집 제어력을 입증하였습니다 [Figure 2]. 특히, SFT(Supervised Fine-Tuning)를 적용했을 때 GPT-4o 기준 정렬 점수가 약 0.8585로 향상되어 기준치 대비 25.9% 이상의 성능 개선을 달성했습니다 [Table 1]. 또한, 제안 모델은 10개 이상의 참조 이미지를 처리하는 고도의 멀티 이미지 문맥 상황에서도 일관된 제어 성능을 보였습니다 [Figure 4].
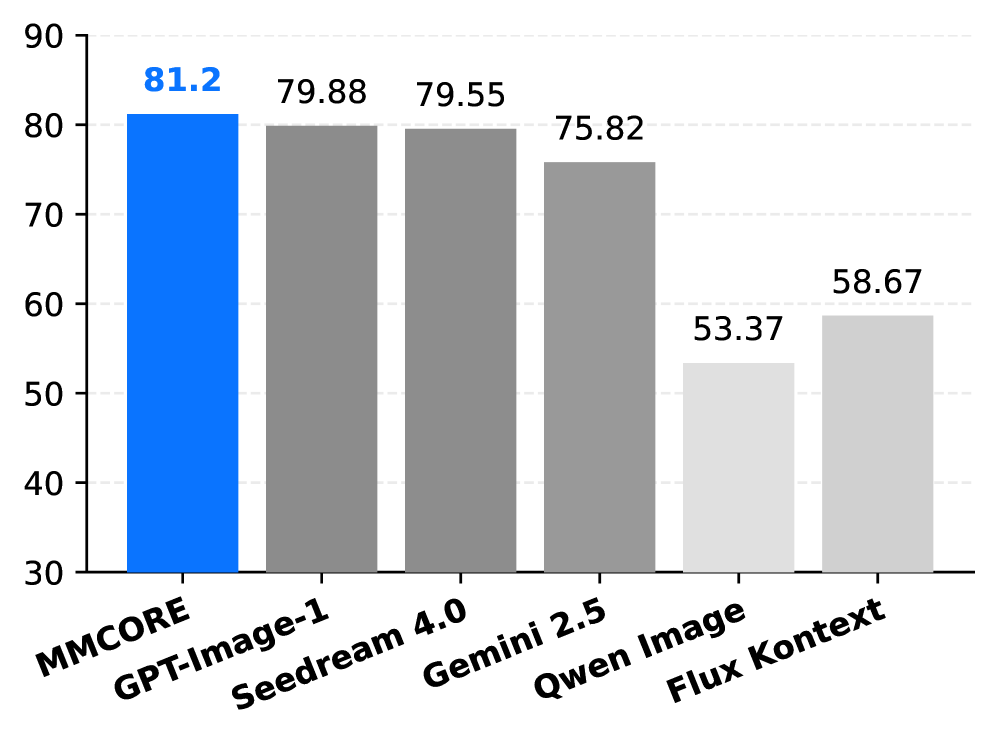
Figure 2 — DreamBench 자동 평가 결과

Figure 4 — MMCORE를 활용한 정밀 이미지 편집 예시
4. Conclusion & Impact (결론 및 시사점)
본 연구는 MLLM의 시맨틱 이해력과 확산 모델의 생성 능력을 표현 수준(Representation Level)에서 정렬함으로써, end-to-end 재학습 없이도 효율적이고 강력한 멀티모달 생성 환경을 구축하였습니다. 이 연구가 제안하는 Dual-Pathway Conditioning과 Visual Latent Alignment 전략은 향후 경량화된 통합 멀티모달 모델 설계에 중요한 이정표가 될 것으로 기대됩니다. 다만, 생성 모델로서의 정렬 과정이 MLLM의 본래 이해 능력에 미치는 영향을 최소화하고, 차후 이해와 생성을 완벽히 통합하는 'Omni-Tokenizer'로의 발전이 남은 과제로 제시되었습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Towards Open-Vocabulary Industrial Defect Understanding with a Large-Scale Multimodal Dataset
- [논문리뷰] MaskAlign: Token-Subset Representation Alignment for Efficient Diffusion Training
- [논문리뷰] Kwai Keye-VL-2.0 Technical Report
- [논문리뷰] WorldBench: A Challenging and Visually Diverse Multimodal Reasoning Benchmark
- [논문리뷰] Direct 3D-Aware Object Insertion via Decomposed Visual Proxies
Review 의 다른글
- 이전글 [논문리뷰] LLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model
- 현재글 : [논문리뷰] MMCORE: MultiModal COnnection with Representation Aligned Latent Embeddings
- 다음글 [논문리뷰] Near-Future Policy Optimization
댓글