[논문리뷰] LLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model
링크: 논문 PDF로 바로 열기
저자: Tiwei Bie, Haoxing Chen, Tieyuan Chen, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- dLLM (Diffusion Large Language Model): 전통적인 autoregressive 언어 모델과 달리 diffusion 기반의 mask prediction 방식을 통해 텍스트와 시각 데이터를 생성 및 이해하는 모델 아키텍처입니다.
- SigLIP-VQ: 시각적 연속 입력을 이산적인(discrete) 의미론적 토큰으로 변환하는 토크나이저로, 기존 VQ-VAE와 달리 의미론적 정보를 보존하여 multimodal 이해 성능을 극대화합니다.
- BDLM (Block Diffusion Language Model): 개별 토큰이 아닌 블록 단위로 마스킹된 영역을 예측하는 학습 목표로, 효율적인 병렬 디코딩과 긴 시퀀스 처리를 가능하게 합니다.
- SPRINT: Sparse Prefix Retention과 Non-uniform Token Unmasking을 결합하여, 성능 손실을 최소화하면서 추론 효율을 가속화하는 학습 없는 추론 프레임워크입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 통합된 multimodal 이해와 생성을 위해 독립적인 아키텍처 대신 dLLM 기반의 단일 프레임워크를 구축하는 것을 목표로 합니다. 기존 unified 모델들은 주로 autoregressive (AR) 방식에 의존하여 병렬 디코딩의 이점을 충분히 활용하지 못하거나, VQ 기반의 낮은 토큰 품질로 인해 이해와 생성 성능 간의 trade-off가 발생한다는 한계가 있었습니다. 특히 기존 masked diffusion 모델들은 reconstruction 중심의 VQ 토크나이저를 사용하여 semantic 정보를 상실하거나 고정된 길이의 출력으로 인해 범용적인 응용에 제한이 있었습니다. 저자들은 이러한 한계를 극복하기 위해 SigLIP-VQ와 통합된 dLLM 아키텍처인 LLaDA2.0-Uni를 제안합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 모델은 fully semantic한 SigLIP-VQ 토크나이저, 16B 파라미터 규모의 MoE dLLM 백본, 그리고 고품질 이미지를 재구성하는 Diffusion Decoder로 구성됩니다. 저자들은 BDLM 학습 목표를 통해 텍스트와 이미지를 단일 토큰 공간에서 block-wise mask prediction 방식으로 처리하며, 이를 통해 interleaved 생성과 추론 능력을 통합하였습니다. 또한 SPRINT 최적화 기법을 도입하여 추론 시 prefix KV 캐시를 효율적으로 관리하고 confidence-adaptive하게 토큰을 생성함으로써 기존 대비 최대 1.6배의 가속을 달성하였습니다. 실험 결과, LLaDA2.0-Uni는 MMStar 벤치마크에서 64.1점을 기록하여 전문 VLM인 Qwen2.5-VL-7B(63.9점)를 상회하는 등 우수한 이해 성능을 보였습니다. 또한, GenEval 벤치마크에서 Overall 0.89를 기록하며 unified 모델 중 최고 수준의 compositional 생성 능력을 증명하였습니다 [Table 2]. 아울러 Diffusion Decoder Turbo를 적용하여 50단계에서 8단계로 생성 과정을 단축했음에도 동일한 성능을 유지하였습니다 [Table 14].
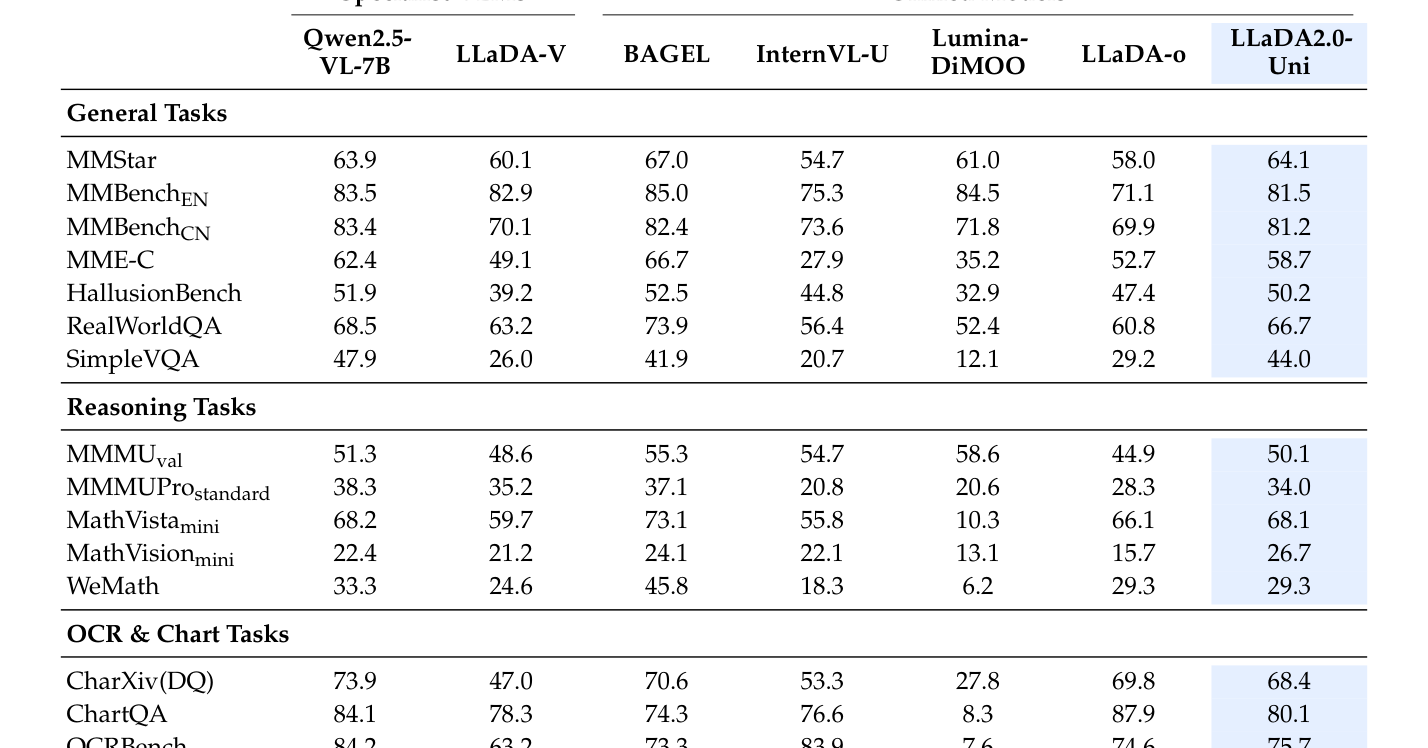
Table 2 — 주요 멀티모달 이해 벤치마크에서의 성능 비교 데이터

Table 14 — 추론 효율 최적화 기법(Turbo)의 성능 및 속도 향상 지표
4. Conclusion & Impact (결론 및 시사점)
본 논문은 통합된 dLLM 프레임워크를 통해 이해와 생성을 하나의 파이프라인에서 최적화할 수 있는 강력한 패러다임을 제시했습니다. LLaDA2.0-Uni는 우수한 벤치마크 성능과 효율적인 추론 기법을 결합하여 차세대 통합 파운데이션 모델로서의 확장 가능성을 입증했습니다. 이 연구는 multimodal 모델이 개별 모달리티의 제약을 넘어 상호 강화적(reinforcement)인 지능을 갖추는 방향을 제시하며, 향후 더 정밀한 상세 묘사(fine-grained detail)와 강화 학습 결합을 통한 추가 발전을 기대하게 합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Context Unrolling in Omni Models
- [논문리뷰] ERNIE 5.0 Technical Report
- [논문리뷰] HYDRA-X: Native Unified Multimodal Models with Holistic Visual Tokenizers
- [논문리뷰] ARM: An AutoRegressive Large Multimodal Model with Unified Discrete Representations
- [논문리뷰] UniGenDet: A Unified Generative-Discriminative Framework for Co-Evolutionary Image Generation and Generated Image Detection
Review 의 다른글
- 이전글 [논문리뷰] Exploring Spatial Intelligence from a Generative Perspective
- 현재글 : [논문리뷰] LLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model
- 다음글 [논문리뷰] MMCORE: MultiModal COnnection with Representation Aligned Latent Embeddings
댓글