[논문리뷰] Exploring Spatial Intelligence from a Generative Perspective
링크: 논문 PDF로 바로 열기
메타데이터
저자: Muzhi Zhu, Shunyao Jiang, Huanyi Zheng, Zekai Luo, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- GSI (Generative Spatial Intelligence): 모델이 이미지 생성 시 3D 공간적 제약 조건을 능동적으로 준수하고 조작할 수 있는 능력을 지칭합니다.
- GSI-Bench: 본 논문에서 제안하는 생성적 공간 지능을 측정하기 위한 벤치마크로, 실제 환경(
GSI-Real)과 합성 환경(GSI-Syn) 데이터셋으로 구성됩니다. - Unified Multimodal Models: 이미지 이해(understanding)와 생성(generation)을 단일 모델 구조 내에서 공동으로 수행하는 모델 아키텍처입니다.
- Instruction Compliance (IC): 생성된 결과물이 주어진 공간적 지시(spatial instruction)를 얼마나 정확하게 만족하는지 평가하는 지표입니다.
- Edit Locality (EL): 이미지 편집 시, 편집 대상이 아닌 영역이 원래의 정보와 일관성을 얼마나 잘 유지하는지를 평가하는 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 MLLM의 공간 지능이 주로 Understanding 관점에서만 연구되어 왔다는 한계점에 주목합니다. 저자들은 현대의 Unified Multimodal Model들이 이미지 생성 과정에서도 3D 공간적 제약을 다룰 수 있는 Generative Spatial Intelligence를 갖추었는지, 그리고 이를 측정하고 향상시킬 수 있는지에 대한 근본적인 의문을 제기합니다. 기존 연구들은 주로 정적인 인식이나 QA 위주의 평가에 치중되어 있어, 생성 모델의 공간적 제약 준수 능력을 정량적으로 평가하기 어려운 실정입니다 [Figure 1]. 따라서 본 연구는 생성적 관점에서의 공간 지능을 정량화하고, 이를 통해 모델의 전반적인 공간 추론 능력을 강화할 수 있는 방안을 모색하고자 합니다.
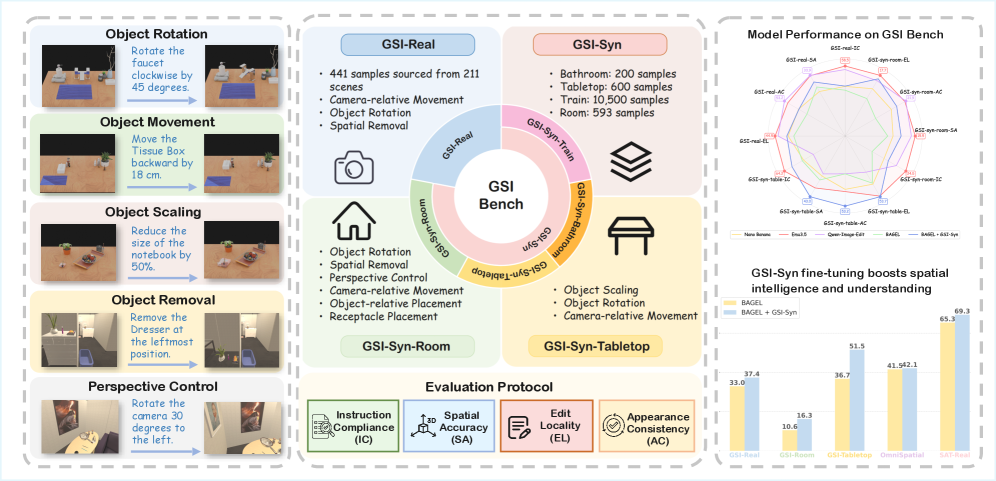
Figure 1 — GSI-Bench 개념도
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 GSI-Bench를 통해 7가지 범주의 공간적 조작(camera-relative move, object-relative place 등)에 대한 정량적 평가 프레임워크를 수립하고, 이를 자동화된 데이터 생성 및 검증 파이프라인으로 구축합니다 [Table 1], [Figure 2]. 저자들은 이 파이프라인을 통해 합성 데이터셋인 GSI-Syn을 대규모로 생성하여 Unified Multimodal Model인 BAGEL을 Fine-tuning 하였습니다. 실험 결과, GSI-Syn으로 학습된 모델은 GSI-Real 및 GSI-Syn 테스트셋에서 각각 +7.83% 및 +22.15%의 평균 성능 향상(Average Gain)을 기록했습니다 [Table 2]. 특히 Instruction Compliance (IC)와 Edit Locality (EL) 측면에서 유의미한 개선이 확인되었으며, 이는 정교한 공간적 조작이 가능해졌음을 의미합니다 [Figure 3]. 더불어, 생성적 공간 지능을 위한 학습이 downstream task인 공간 이해(spatial understanding) 성능까지 향상시킨다는 점을 확인하였으며, 이는 OmniSpatial 벤치마크에서의 전반적인 향상으로 증명되었습니다 [Table 3].
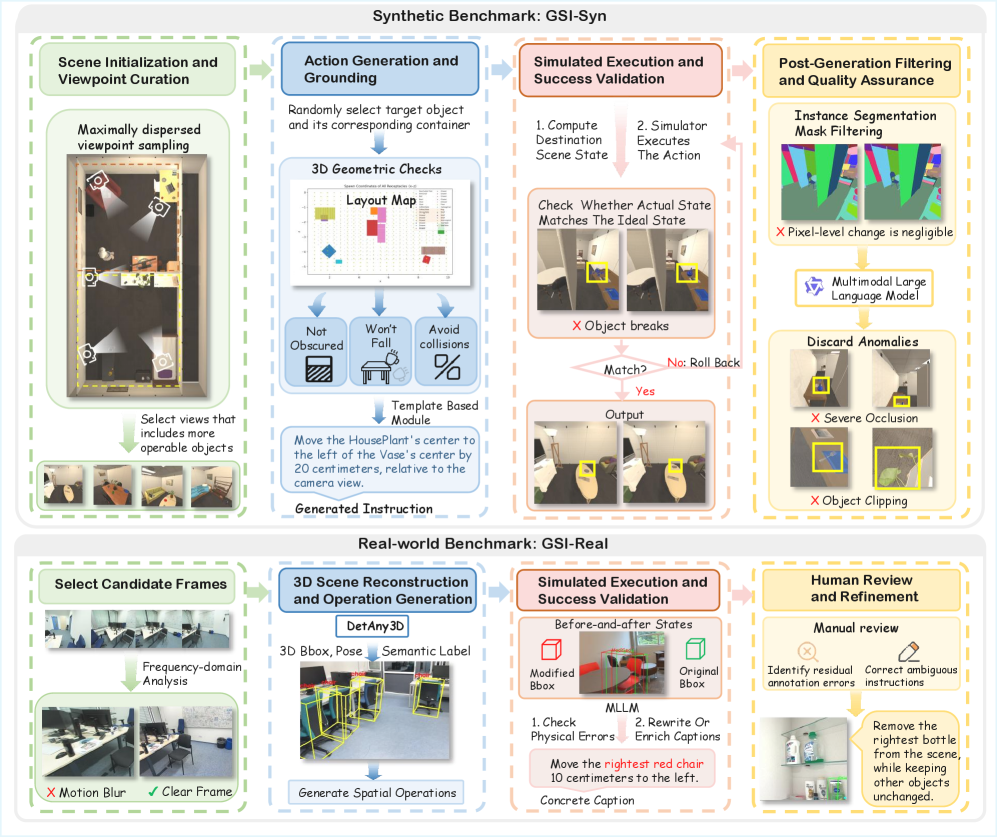
Figure 2 — 데이터 구축 파이프라인

Figure 3 — 공간 편집 결과 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 생성적 공간 지능이라는 새로운 관점을 제시하며, 이를 정량화할 수 있는 GSI-Bench를 구축하여 MLLM 연구의 새로운 방향성을 제시합니다. 특히 시뮬레이션 기반의 생성적 학습(generative training)이 복잡한 3D 공간 추론 능력을 강화하고 실제 환경으로 전이(Sim-to-Real Transfer)될 수 있음을 증명했습니다. 본 연구의 결과는 향후 embodied AI나 정밀한 이미지 편집이 필요한 도메인에서 모델의 공간적 신뢰성을 확보하는 데 중요한 기술적 토대가 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Edit-Compass & EditReward-Compass: A Unified Benchmark for Image Editing and Reward Modeling
- [논문리뷰] Is This Edit Correct? A Multi-Dimensional Benchmark for Reasoning-Aware Image Editing
- [논문리뷰] PaintBench: Deterministic Evaluation of Precise Visual Editing
- [논문리뷰] Benchmarking Visual State Tracking in Multimodal Video Understanding
- [논문리뷰] Omni-DuplexEval: Evaluating Real-time Duplex Omni-modal Interaction
Review 의 다른글
- 이전글 [논문리뷰] Diverse Dictionary Learning
- 현재글 : [논문리뷰] Exploring Spatial Intelligence from a Generative Perspective
- 다음글 [논문리뷰] LLaDA2.0-Uni: Unifying Multimodal Understanding and Generation with Diffusion Large Language Model
댓글