[논문리뷰] VTC-Bench: Evaluating Agentic Multimodal Models via Compositional Visual Tool Chaining
링크: 논문 PDF로 바로 열기
The user wants me to summarize the paper "VTC-Bench: Evaluating Agentic Multimodal Models via Compositional Visual Tool Chaining".
I will now go through the content and extract the information needed for each section and identify the figures.
Part 1: Summary Body
Metadata:
- Authors : Zhipeng Wu, Yang Shi, Rundong Wang, Yuhao Dong, Xuanyu Zhu, Yinlun Peng, YiFan Zhang, Yihang Lou, Yuanxing Zhang, Ziwei Liu, Yan Bai, Yuan Zhou. (I will use the first few and et al.)
- Keywords : Will identify 5-8 from the abstract and introduction. Likely
Multimodal Large Language Models (MLLMs),Visual Tool Chaining,Agentic Models,Benchmark,OpenCV,Compositional Reasoning,Tool-use Evaluation,Visual Operations.
Sections:
## 1. Key Terms & Definitions
MLLMs (Multimodal Large Language Models): Standard visual question answering를 넘어 external tools를 활용하여 advanced visual tasks를 수행하는 모델.Visual Tool Chaining: Complex visual tasks를 해결하기 위해 여러 visual operations를 순차적으로 연결하여 사용하는 프로세스.Agentic Models: External tools를 전략적으로 활용하여 복잡한 visual workflows를 능동적으로 실행하는 MLLMs.VTC-Bench (VisualToolChain-Bench): MLLMs의 tool-use proficiency를 평가하기 위해 고안된 종합적인 벤치마크.OpenCV: VTC-Bench의 기반이 되는 32가지 visual operations를 제공하는 라이브러리.
## 2. Motivation & Problem Statement
- Problem : Current MLLMs struggle with precisely executing and effectively composing diverse tools for complex visual tasks.
- Limitations of Existing Benchmarks : Sparse tool-sets and simple tool-use trajectories fail to capture complex and diverse tool interactions required for real-world conditions. They do not adequately assess multi-tool composition and long-horizon, multi-step plan execution.
- Need for New Approach : A comprehensive benchmark is needed to rigorously evaluate advanced tool-use proficiency, tool diversity, and the complexity of multi-step tool composition.
## 3. Method & Key Results
- Methodology :
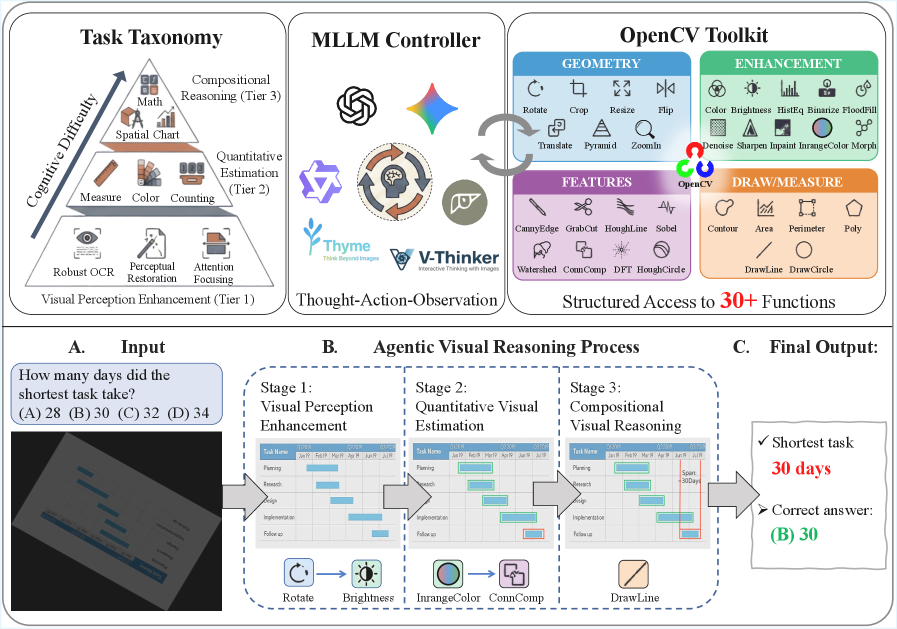
- VTC-Bench Framework : A comprehensive benchmark integrating 32 diverse OpenCV-based visual operations. These operations are categorized into Geometry, Enhancement, Feature Extraction, and Drawing modules.
- Task Design : 680 curated problems structured across a nine-category cognitive hierarchy (Visual Perception Enhancement, Quantitative Visual Estimation, Compositional Visual Reasoning). Each problem includes ground-truth execution trajectories.
- Evaluation Metrics : Average Pass Rate (APR) , Tool Call Rate (TCR) , Mean Absolute Error (MAE) for toolchain length, and Tool Usage Efficiency (Eff_tool) .
- Key Results :
- Current MLLMs face critical limitations in visual agentic capabilities. Overall performance is low, with the leading model Gemini-3.0-Pro achieving only 51.2% APR .
- Proprietary models (e.g., GPT-4o , GPT-5.2 , Gemini-3.0-Pro ) show substantial performance improvements with tool augmentation (e.g., GPT-4o +9.56% with interface, GPT-5.2 +8.53% with code). Open-source models exhibit minimal gains or performance degradation.
- Models struggle to adapt to diverse tool-sets and generalize to unseen operations.
- Multi-tool composition remains a persistent challenge; models heavily favor a narrow, suboptimal subset of familiar functions rather than selecting optimal tools. For example, GPT-5.2 recorded an MAE of 9.96 in attempted calls and an Eff_tool of 16.78%.
- Robust intrinsic perception is an indispensable prerequisite for advanced tool calling.
## 4. Conclusion & Impact
- Conclusion : VTC-Bench demonstrates that current MLLMs have significant deficiencies in multi-step tool composition and orchestration. They tend to over-rely on a limited set of tools and often fail to integrate intrinsic perception with active agentic reasoning.
- Impact : This benchmark establishes a rigorous baseline, highlighting the critical disconnect between foundational visual perception and active agentic reasoning, thus guiding the development of more generalized visual agentic models in both academia and industry.
Part 2: Important Figure Information
I will look for figures related to:
- Overall Architecture/Framework.
- Key Results (e.g., performance comparison, tool utilization distribution).
- Methodology illustration (e.g., cognitive hierarchy).
Based on the content scan, the following figures seem important:
- Figure 1 : Overview of VTC-Bench and the agentic reasoning workflow. This is likely the overall architecture.
- Figure 2 : Overview of VTC-Bench. This seems to detail the cognitive hierarchy and task taxonomy.
- Table 4 (not a figure, but critical result) : Comprehensive evaluation results. The prompt asks for Figure information, so I will stick to images.
- Figure 5 : Relationships among Tool Call Rate, Tool Call Efficiency, and APR. This shows key quantitative results.
- Figure 6 : Distribution of tool utilization across different models. This illustrates model behavior.
I will choose Figure 1 (overall framework), Figure 2 (task taxonomy/hierarchy), and Figure 5 (key results on tool efficiency).
Let's get the image URLs and short captions for these.
Figure 1: 2603.15030v2/x1.png -> https://arxiv.org/html/2603.15030v2/x1.png
Caption: VTC-Bench 개요 및 에이전트 워크플로우
Figure 2: 2603.15030v2/x2.png -> https://arxiv.org/html/2603.15030v2/x2.png
Caption: VTC-Bench의 계층적 태스크 분류
Figure 5: 2603.15030v2/x5.png -> https://arxiv.org/html/2603.15030v2/x5.png
Caption: 도구 호출 비율, 효율성 및 APR 관계
Now, I will construct the full response. 저자: Zhipeng Wu, Yang Shi, Rundong Wang, Yuhao Dong, Xuanyu Zhu, et al.
1. Key Terms & Definitions
- MLLMs (Multimodal Large Language Models) : 표준 Visual Question Answering를 넘어 외부 도구(external tools)를 활용하여 Advanced Visual Tasks를 수행하는 모델을 지칭합니다.
- Visual Tool Chaining : 복잡한 Visual Tasks를 해결하기 위해 여러 Visual Operations를 순차적으로 연결하여 사용하는 프로세스를 의미합니다.
- Agentic Models : 외부 Visual Tools를 전략적으로 활용하여 복잡한 Visual Workflows를 능동적으로 실행하고 Enhanced Image Comprehension을 달성하는 MLLMs을 뜻합니다.
- VTC-Bench (VisualToolChain-Bench) : MLLMs의 Advanced Tool-use Proficiency 및 Compositional Visual Reasoning 능력을 엄격하게 평가하기 위해 고안된 종합적인 벤치마크입니다.
- OpenCV : VTC-Bench가 통합하는 32가지 다양한 Visual Operations의 주요 소스로, 실세계 컴퓨터 비전 파이프라인(real-world computer vision pipelines)을 에뮬레이트하는 데 사용됩니다.
2. Motivation & Problem Statement
최근 MLLMs는 External Tools와의 통합을 통해 Agentic Problem Solvers로 발전하고 있으나, 복잡한 Visual Tasks를 위해 다양한 도구를 정확하게 실행하고 효과적으로 조합하는 데 지속적인 병목 현상(persistent bottleneck)을 겪고 있습니다. 기존 벤치마크(Existing Benchmarks)는 제한된 Tool-sets과 단순한 Tool-use Trajectories에 의존하여, 실제 환경에서 요구되는 복잡하고 다양한 도구 상호작용 및 Multi-tool Composition을 포착하는 데 실패하고 있습니다. 이러한 한계점은 현존하는 모델들의 실제 Operational Limits를 가리며, 더욱 신뢰성 있는 Visual Agents 개발을 위한 지침을 제공하기에 부적합합니다. 이러한 격차를 해소하고 MLLMs의 Advanced Tool-use Proficiency를 엄격하게 평가하기 위해 VTC-Bench 가 제안되었습니다.
3. Method & Key Results
저자들은 MLLMs의 Compositional Visual Tool Chaining 능력을 평가하기 위해 VTC-Bench 를 제안합니다. 이 벤치마크는 실제 컴퓨터 비전 파이프라인을 모방하기 위해 OpenCV 라이브러리에서 파생된 32가지 다양한 Visual Operations를 통합합니다. 이러한 도구들은 Geometry, Enhancement, Feature Extraction, Drawing의 네 가지 기능 모듈로 구성됩니다. 벤치마크는 9가지 범주의 Cognitive Hierarchy에 걸쳐 680개의 문제로 구성되며, 각 문제에는 Ground-truth Execution Trajectories가 제공되어 정밀한 평가를 가능하게 합니다 [Figure 1, 2].
평가는 Average Pass Rate (APR) 를 주요 지표로 사용하며, Tool-use Behavior 분석을 위해 Tool Call Rate (TCR) , Ground-truth Toolchains와의 길이 불일치를 측정하는 Mean Absolute Error (MAE) , 그리고 도구 호출 시퀀스의 정밀도와 간결성을 평가하는 Tool Usage Efficiency (Eff_tool) 를 추가로 사용합니다.
19개 주요 MLLMs에 대한 광범위한 실험 결과, 현재 모델들의 Visual Agentic Capabilities에 심각한 한계가 드러났습니다. 최상위 모델인 Gemini-3.0-Pro 조차 51.2% 의 APR 에 그쳤으며, 대부분의 모델은 30%대 에 머물렀습니다. 특히 Proprietary Models는 Tool Augmentation 시 성능이 크게 향상되는 반면(예: GPT-4o 는 Interface 설정에서 +9.56% , GPT-5.2 는 Code 설정에서 +8.53% 향상), Open-source Models는 미미한 성능 향상 또는 저하를 보였습니다. 또한, 모델들은 다양한 Tool-sets에 적응하고 미확인 Operation에 일반화하는 데 어려움을 겪으며, Multi-tool Composition은 여전히 극복하기 어려운 과제였습니다. 모델들은 최적의 도구를 선택하기보다 익숙하고 Suboptimal한 기능 Subset에 크게 의존하는 경향을 보였습니다. 예를 들어, GPT-5.2 는 시도된 호출에서 9.96% 의 MAE 를, 16.78% 의 Eff_tool 을 기록했으며, GPT-o3 와 Gemini-3.0-Pro 역시 각각 17.20% 및 36.51% 의 낮은 효율성을 보였습니다
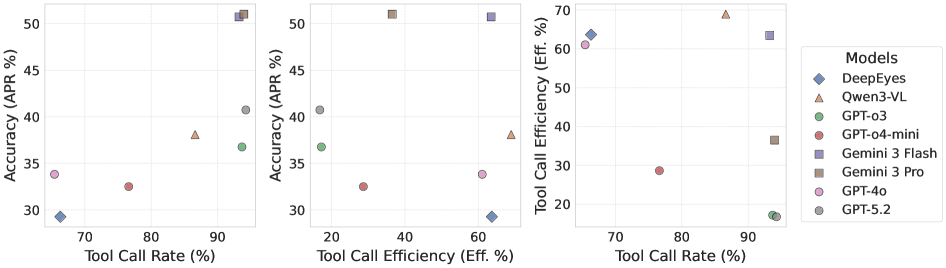
이러한 결과는 현재 모델들이 복잡한 Multi-step Tool Sequences를 조정하는 데 있어 Critical Deficit이 있음을 시사합니다.
4. Conclusion & Impact
본 논문에서 제안된 VTC-Bench 는 MLLMs의 Multi-step Tool Composition Capabilities를 평가하기 위한 정교한 벤치마크로 자리매김합니다. 이 벤치마크는 9가지 Real-world Categories에 걸쳐 32가지 다양한 도구를 통합함으로써 기존 평가를 크게 능가합니다. 19개 MLLMs에 대한 광범위한 실험은 현재 모델들의 도구 오케스트레이션(tool orchestration)에 있어 심각한 결함을 드러냈습니다. 모델들은 종종 제한된 도구 Subset에 집중하여 Suboptimal한 실행 효율성을 보였으며, 정밀한 도구 호출에 어려움을 겪거나 도구 출력에 과도하게 의존하여 내재된 지각 능력(intrinsic perceptual capabilities)을 간과하는 경향을 보였습니다. 이러한 연구 결과는 Foundational Visual Perception과 Active Agentic Reasoning 사이의 Critical Disconnect를 강조하며, 미래 MLLM 아키텍처 개발을 위한 명확한 연구 Frontier를 제시합니다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MuseBench: Benchmarking Intent-Level Audiovisual Arts Understanding in MLLMs
- [논문리뷰] Benchmarking Visual State Tracking in Multimodal Video Understanding
- [논문리뷰] Omni-DuplexEval: Evaluating Real-time Duplex Omni-modal Interaction
- [논문리뷰] Edit-Compass & EditReward-Compass: A Unified Benchmark for Image Editing and Reward Modeling
- [논문리뷰] Exploring Spatial Intelligence from a Generative Perspective
Review 의 다른글
- 이전글 [논문리뷰] SAMA: Factorized Semantic Anchoring and Motion Alignment for Instruction-Guided Video Editing
- 현재글 : [논문리뷰] VTC-Bench: Evaluating Agentic Multimodal Models via Compositional Visual Tool Chaining
- 다음글 [논문리뷰] A Subgoal-driven Framework for Improving Long-Horizon LLM Agents
댓글