[논문리뷰] SAMA: Factorized Semantic Anchoring and Motion Alignment for Instruction-Guided Video Editing
링크: 논문 PDF로 바로 열기
저자: Xinyao Zhang, Wenkai Dong, Yuxin Song, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Semantic Anchoring (SA) : 논문에서
semantic tokens과video latents를sparse anchor frames에서 공동으로 예측하여instruction-aware structural planning을 가능하게 하는 기법입니다. 이는instruction-consistent semantic anchoring을 촉진하고diffusion backbone과의 공유를 통해 효율성을 높입니다. - Motion Alignment (MA) :
motion-centric video restoration pretext tasks(예:Cube Inpainting,Speed Perturbation,Tube Shuffle)를 통해diffusion backbone이temporal dynamics를 원본 영상으로부터 직접 내재화하도록pre-training하는 과정입니다. 이는temporal stability를 향상시키고semantic–motion conflicts를 완화합니다. - Factorized Pre-training :
instruction-guided video editing의 핵심 문제를semantic structure planning과motion modeling으로 분해하여,paired video-instruction editing data없이instruction-based image editing및 대규모text-to-video데이터를 혼합하여pre-train하는 초기 학습 단계입니다. - Flow Matching :
generative modeling을 위한video diffusion transformer framework에서 사용되는training objective입니다. 이 방법론은intermediate statext에서target videox1로 향하는vector field를vθ(xt, t)로 회귀하도록 학습하며, 이는diffusion process를 효율적으로 최적화합니다. - Type Embeddings :
source-video latent tokens,target-video latent tokens, 그리고Semantic Anchoring에 의해 도입된semantic tokens의 역할을 구분하기 위해 각 토큰에 추가되는 학습된embedding입니다. 이는shifted RoPE방식보다 빠르고 안정적인convergence를 유도하며,positional encoding과 토큰identity를 분리합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
현재 instruction-guided video editing models은 fine-grained semantic modifications와 faithful motion preservation 간의 균형을 맞추는 데 어려움을 겪고 있습니다. diffusion models의 발전으로 이미지 편집의 충실도와 제어 가능성은 크게 향상되었지만, 이를 영상으로 확장하는 것은 훨씬 더 복잡합니다. 기존 접근 방식들은 VLM-extracted semantic conditions나 structural signals (예: skeletons, depth maps)와 같은 explicit external priors 주입에 의존하여 이러한 문제를 완화하려 합니다. 그러나 저자들은 이러한 과도한 의존이 모델의 robustness와 generalization에 심각한 bottleneck을 야기하며, diffusion backbone이 inherent semantic-motion representations를 학습하는 데 방해가 된다고 주장합니다. 따라서 본 연구는 semantic structure planning과 motion modeling을 분리하는 factorization의 부족이 핵심적인 어려움이라고 보고, 이를 해결하기 위한 새로운 접근 방식을 제안합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 instruction-guided video editing을 위한 SAMA (factorized Semantic Anchoring and Motion Alignment) 프레임워크를 제안합니다. SAMA는 semantic anchoring과 motion modeling으로 영상 편집을 분해하여 학습합니다
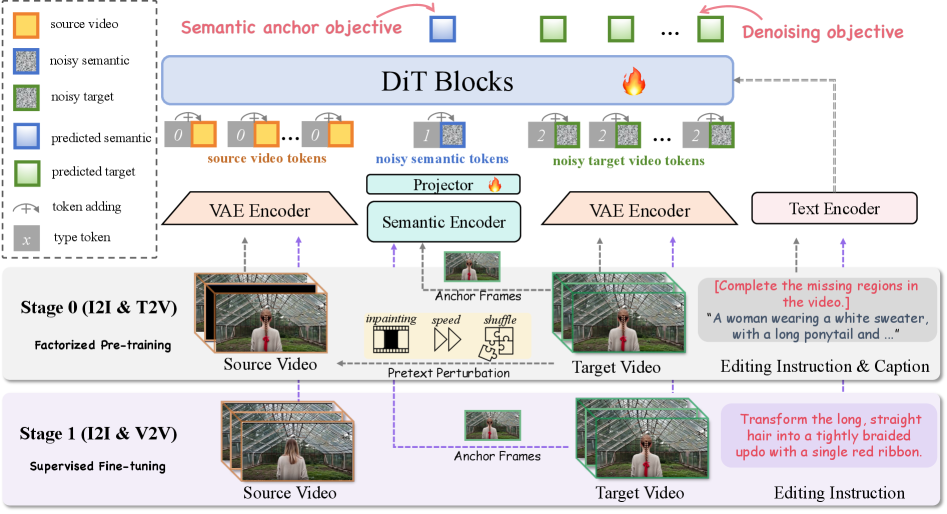
첫째, Semantic Anchoring (SA) 은 sparse anchor frames에서 semantic tokens과 video latents를 동시에 예측하여 instruction-aware structural planning을 가능하게 함으로써 신뢰할 수 있는 visual anchor를 설정합니다. 이 semantic tokens는 SigLIP image encoder로 추출된 patch-level semantic features를 pooling하여 생성되며, ℓ1 loss를 통해 semantic prediction을 supervise합니다.
둘째, Motion Alignment (MA) 는 동일한 backbone을 motion-centric video restoration pretext tasks (예: Cube Inpainting, Speed Perturbation, Tube Shuffle)에 대해 pre-train하여 raw videos로부터 temporal dynamics를 직접 내재화하도록 합니다 [Figure 3]. 이러한 pretext tasks는 prompting을 통해 instruction-conditioned editing formulation과 호환되도록 설계되었습니다.
SAMA는 두 단계 pipeline으로 최적화됩니다 [Figure 2]. Stage 0 (Factorized Pre-training) 에서는 paired video-instruction editing data 없이 image editing 및 text-to-video 데이터를 혼합하여 inherent semantic-motion representations를 학습합니다. 이 단계에서 SA는 모든 샘플에, MA는 영상 스트림에 적용됩니다. Stage 1 (Supervised Fine-tuning, SFT) 에서는 paired video editing datasets를 사용하여 editing performance를 강화하며, SA를 계속 활성화하여 안정적인 semantic anchoring을 유지합니다.
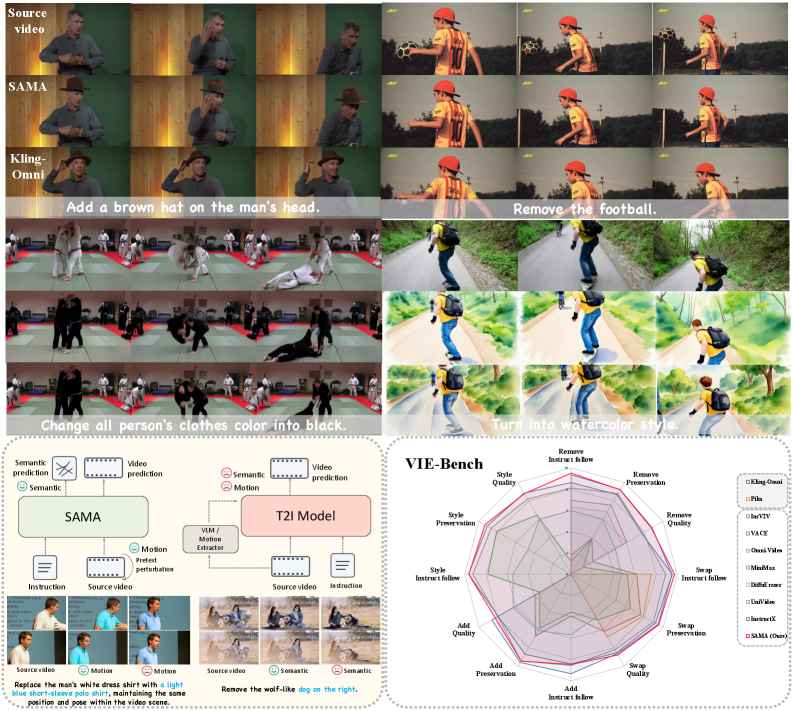
SAMA는 VIE-Bench, OpenVE-Bench, ReCo-Bench 등 다양한 벤치마크에서 state-of-the-art performance를 달성했으며, Kling-Omni와 같은 상업 시스템과도 경쟁력 있는 결과를 보였습니다 [Table 2, 3, 4]. 특히 VIE-Bench의 Swap/Change task에서 9.340 , Remove task에서 9.144 의 overall score를 기록하며 open-source models 중 최고 성능을 보여주었습니다. Ablation study 결과, SA를 포함하면 diffusion loss 감소가 가속화되어 DiT convergence가 빨라지고 loss variance가 줄어들어 training stability가 향상됨이 확인되었습니다 [Figure 6(a), 6(b)]. MA는 fast motion 상황에서 temporal consistency를 개선하고 motion blur를 완화하는 데 기여했습니다 [Figure 7]. 정량적으로, SA 추가 시 baseline 대비 overall score가 0.384 p 향상되었고, MA 추가 시 0.399 p 향상되었습니다. SA와 MA를 모두 적용한 SAMA는 baseline 대비 overall score를 0.783 p 높여, 두 구성 요소가 상호 보완적임을 입증했습니다. 또한, factorized pre-training만으로도 강력한 zero-shot video editing 능력을 보여주었습니다 [Figure 5].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 instruction-guided video editing에서 semantic anchoring과 motion alignment를 분리하는 factorized framework인 SAMA를 성공적으로 제시했습니다. SAMA는 anchor frames에서의 semantic-token prediction을 통한 explicit prior 도입과 motion-centric restoration pre-training을 통한 temporal coherence 강화를 통해 기존 모델의 한계를 극복했습니다. 광범위한 실험을 통해 SAMA는 open-source methods 중 state-of-the-art performance를 달성했으며, commercial systems과도 견줄 만한 경쟁력을 입증했습니다. 또한, SAMA의 강력한 zero-shot editing behavior는 disentangled semantic 및 motion representations 학습을 통해 robust instruction following이 자연스럽게 나타날 수 있음을 시사합니다. 이 연구는 explicit external priors에 대한 의존도를 줄이고 inherent semantic-motion representations 학습의 중요성을 강조함으로써 instruction-guided video editing 분야에 중요한 기여를 합니다. 향후 연구는 long-video editing, fast-motion scenarios, 그리고 stronger semantic tokenization을 통해 잔여 artifacts 및 temporal inconsistencies를 더욱 줄이는 데 초점을 맞출 것입니다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] DVD: Deterministic Video Depth Estimation with Generative Priors
- [논문리뷰] Enhancing Train-Free Infinite-Frame Generation for Consistent Long Videos
- [논문리뷰] DreamWorld: Unified World Modeling in Video Generation
- [논문리뷰] NOVA: Sparse Control, Dense Synthesis for Pair-Free Video Editing
- [논문리뷰] Context Forcing: Consistent Autoregressive Video Generation with Long Context
Review 의 다른글
- 이전글 [논문리뷰] Reasoning over mathematical objects: on-policy reward modeling and test time aggregation
- 현재글 : [논문리뷰] SAMA: Factorized Semantic Anchoring and Motion Alignment for Instruction-Guided Video Editing
- 다음글 [논문리뷰] VTC-Bench: Evaluating Agentic Multimodal Models via Compositional Visual Tool Chaining
댓글