[논문리뷰] Reasoning over mathematical objects: on-policy reward modeling and test time aggregation
링크: 논문 PDF로 바로 열기
저자: Pranjal Aggarwal, Marjan Ghazvininejad, et al.
키워: Mathematical Objects, On-Policy Reward Modeling, Test Time Aggregation, Principia Suite, RLLM, PARAGATOR, LM-as-RM
1. Key Terms & Definitions (핵심 용어 및 정의)
- Principia Suite : 언어 모델(LM)이 수학적 객체(mathematical objects)를 도출하는 능력을 평가하고 훈련하기 위한 데이터셋 및 벤치마크 세트.
PrincipiaBench(평가 벤치마크),Principia Collection(합성 훈련 데이터셋),Principia VerifyBench(검증기 메타-평가 벤치마크)로 구성됩니다. - RLLM (Reinforcement Learning with an LM as Reward Model) : 강력한 언어 모델(
LM-as-RM) 자체를 "사고(thinking)" Reward Model로 사용하여 generative reward를 제공하는 사후 훈련(post-training) 프레임워크로, 검증 가능(easy-to-verify), 검증하기 어려움(hard-to-verify), 비검증 가능(non-verifiable) 등 다양한 유형의 태스크를 통합합니다. - PARAGATOR : 기존 병렬 사고(parallel thinking) 방법론의 한계점(다양성 부족, 훈련/추론 불일치)을 해결하는 unified online training framework입니다. 병렬 생성 단계에서는
pass@koptimization을, aggregation 단계에서는pass@1optimization을 사용하여 end-to-end로 훈련합니다. - LM-as-RM (Language Model as Reward Model) : 정책 최적화를 위한 reward로써 명시적인 추론 트레이스(reasoning traces)를 생성하고 유연한 점수(pointwise, pairwise, listwise)를 할당하는 데 사용되는 대규모 언어 모델(LLM)입니다.
- Pass@k optimization : 모델이 생성한
k개의 샘플 중 최소 하나가 성공했을 때 보상하여 솔루션 다양성을 장려하는 최적화 방법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
현재 언어 모델(LM)의 수학 및 과학 추론 능력 평가는 주로 숫자 값이나 multiple-choice 질문과 같은 단순화된 답변 형식에 의존합니다. 이러한 방식은 모델의 실제 추론 능력을 과대평가할 수 있으며, 모델이 복잡한 수학적 객체를 *새롭게 유도(de novo derivation)*하기보다는 옵션 기반의 지름길을 활용하는 경향이 있습니다 [Figure 2, Figure 3]. 특히, 방정식, 부등식, 집합, 행렬, piecewise function과 같은 정형화된 수학적 표현을 직접 도출하도록 요구하는 벤치마크와 훈련 데이터가 현저히 부족한 실정입니다. 기존 사후 훈련 데이터셋은 주로 짧은 답변이나 단순한 수학적 객체로 구성되어 있으며, 문제 진술(problem statements) 또한 대학원 수준의 STEM 과정에서 요구되는 상세하고 구조화된 설명이 부족합니다 [Figure 4]. 이러한 격차는 복잡한 수학적 객체를 도출하는 LM의 능력을 정확하게 평가하고 향상시키기 위한 새로운 벤치마크와 훈련 데이터의 개발 필요성을 시사합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
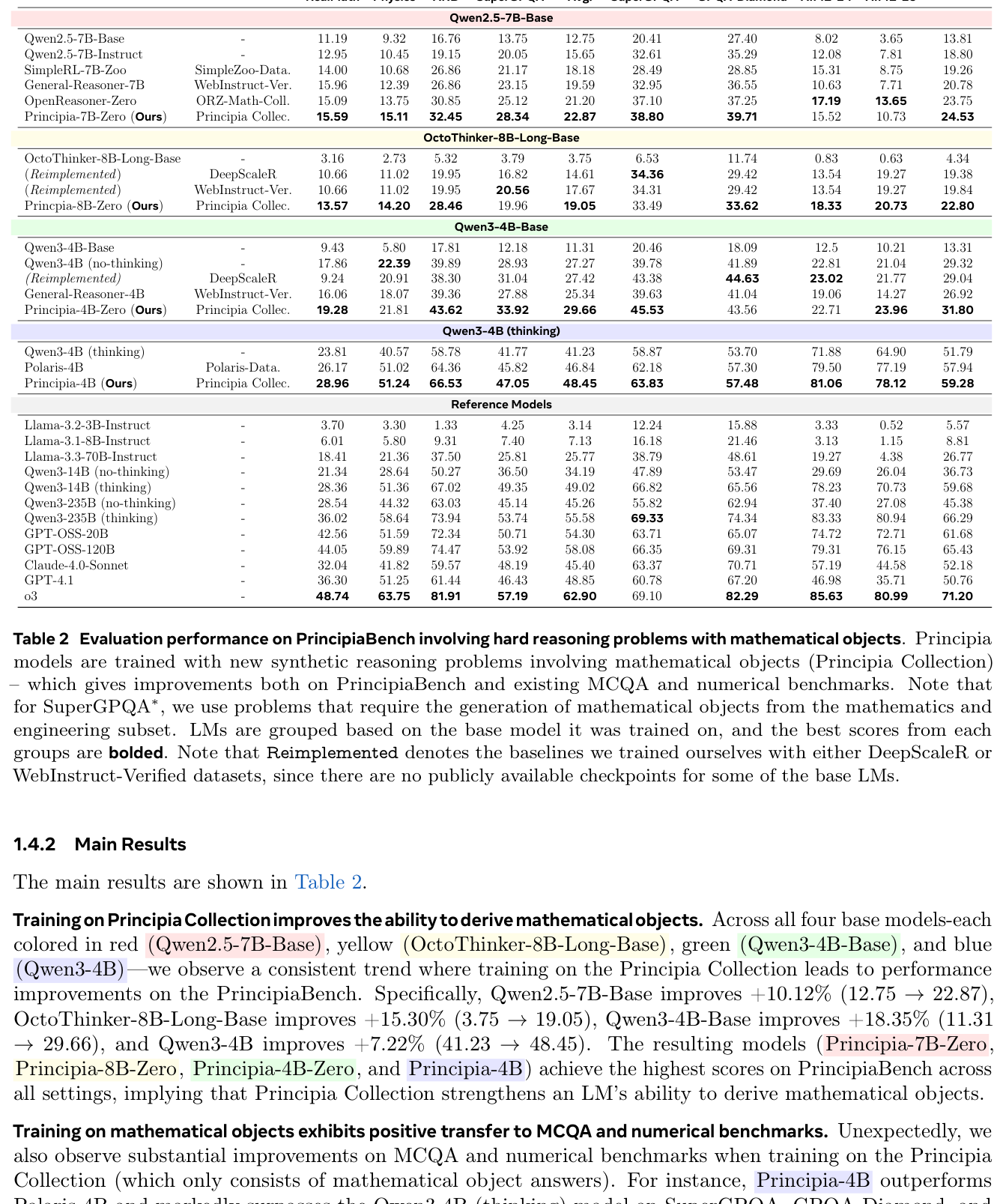
저자들은 이러한 데이터 및 평가 격차를 해소하기 위해 Principia Suite 를 제안합니다. PrincipiaBench 는 복잡한 수학적 객체 답변을 요구하는 2,558개의 문제로 구성된 새로운 평가 벤치마크로, Qwen3-235B (55.58%) 및 o3 (62.90%)와 같은 frontier LM들에게 AIME (83.33% 및 85.63%) 및 GPQA-Diamond (74.34% 및 82.29%) 벤치마크 대비 더 큰 도전 과제를 제시합니다. Principia Collection 은 MSC 2020 및 PhySH 분류 체계에 기반한 248,000개의 대학원 수준 문제 진술과 6가지 유형의 수학적 객체 답변으로 구성된 합성 훈련 데이터셋입니다. 핵심 요소는 모델 기반 검증기(model-based verifier)의 사용이며, o3 는 Principia VerifyBench 에서 인간 판단과의 일치율이 94.05%에 달하여 rule-based verifier (예: math-verify의 5.95%)보다 훨씬 우수한 성능을 보였습니다.
논문은 또한 on-policy로 훈련된 LM-as-RM 을 사용하는 통합 사후 훈련 프레임워크인 RLLM 을 제안합니다
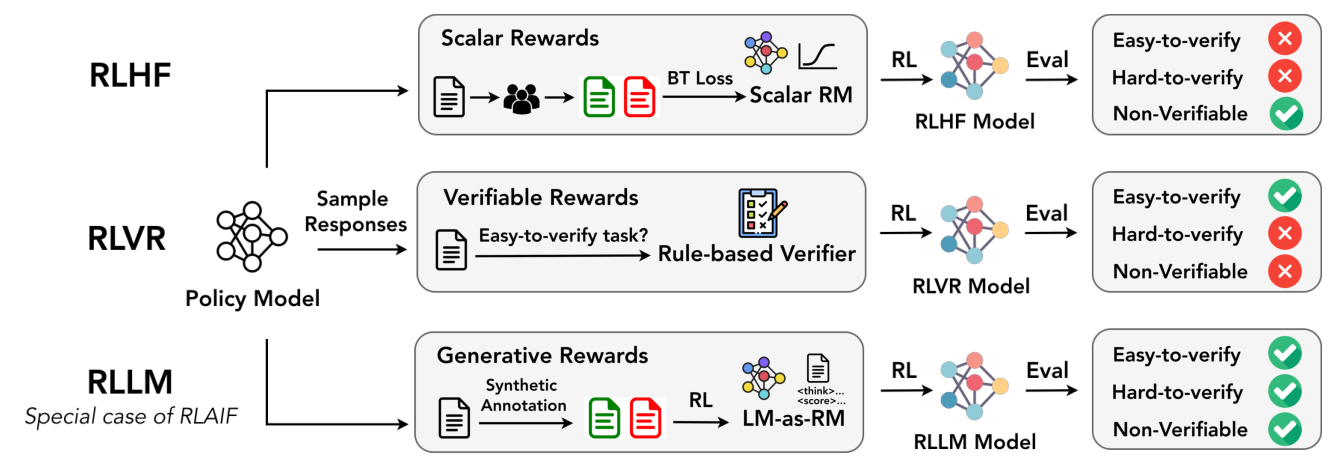
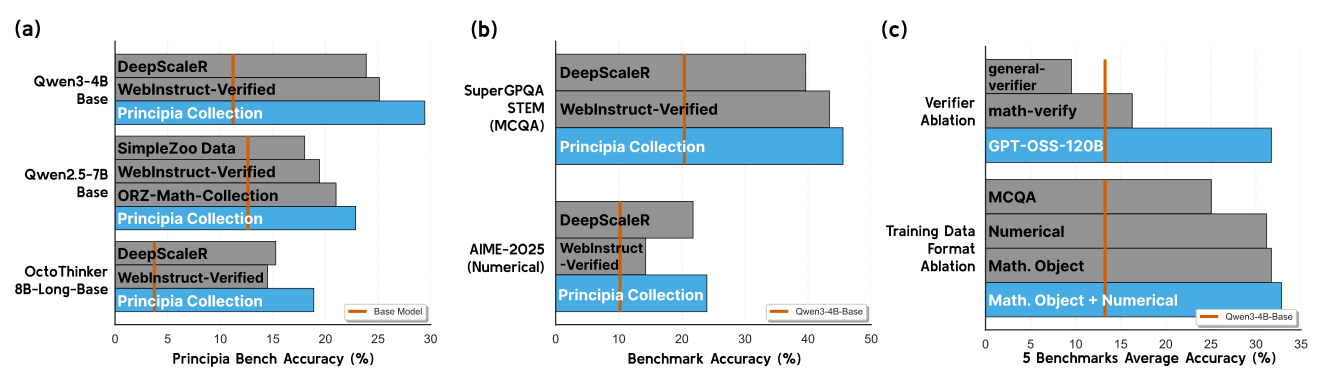
이 LM-as-RM 은 명시적인 추론 트레이스와 유연한 보상을 생성하며, 기존 RLHF (scalar RM) 및 RLVR (rule-based verifier)보다 easy-to-verify, hard-to-verify, non-verifiable 태스크 전반에서 우수한 성능을 보여줍니다. 예를 들어, J1-Qwen3-32B-RM 을 사용한 RLLM 은 Qwen3-1.7B Instruct 모델 대비 competition math 태스크에서 8% 절대 성능 향상 을 달성했습니다 (평균 43.41% 대 35.20%) [Table 6]. Principia Collection 을 통한 훈련은 다양한 base LLM에 걸쳐 PrincipiaBench 에서 평균 7.22%에서 18.35% 의 성능 향상을 가져왔으며, 기존 numerical (AIME 2024에서 7.5-17.5%) 및 MCQA (GPQA-Diamond에서 12.31-25.47%) 태스크에서도 결과를 개선했습니다 [Figure 1, Table 2].
더 나아가, 논문은 on-policy로 훈련된 병렬 aggregation을 통한 테스트 시간 스케일링을 위한 PARAGATOR 를 소개합니다. 이 방법은 다양한 병렬 생성을 위해 pass@k optimization을, 최적의 aggregation을 위해 pass@1 optimization을 사용합니다. PARAGATOR 는 competition math 및 scientific reasoning 벤치마크에서 초기 및 aggregation 라운드 모두에서 가장 높은 reward를 일관되게 달성했습니다 [Table 15, Table 16]. Qwen3-4B-Base 의 경우, PARAGATOR 는 post-aggregation PrincipiaBench 평균 33.77% 와 competition math 평균 23.72%로 최고의 성능을 기록했습니다 [Table 16].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 LM이 복잡한 수학적 객체를 정확하게 도출해야 하는 중요한 요구사항을 성공적으로 해결했습니다. PrincipiaBench , Principia Collection , Principia VerifyBench 를 도입함으로써, 저자들은 LM의 이와 같은 기본 추론 영역을 평가하고 훈련하기 위한 강력한 도구를 제공합니다. on-policy로 훈련된 LM-as-RM을 활용하는 RLLM 프레임워크와 end-to-end online aggregation을 위한 PARAGATOR 방법론은 추론 능력의 최신 기술 수준을 크게 향상시킵니다. 이러한 기여는 수학적 객체 도출 성능을 향상시킬 뿐만 아니라, 기존 numerical 및 multiple-choice 태스크로의 긍정적인 전이 학습(positive transfer)을 보여주며, 복잡한 구조화된 출력을 학습하는 것이 일반적인 추론 능력을 강화함을 입증합니다. 본 연구는 수학적 객체 도출을 핵심 역량으로 인식함으로써 LM을 보다 야심찬 과학적 발견 및 문제 해결 애플리케이션에 통합하는 길을 열어줍니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Prompt-Free Universal Region Proposal Network
- 현재글 : [논문리뷰] Reasoning over mathematical objects: on-policy reward modeling and test time aggregation
- 다음글 [논문리뷰] SAMA: Factorized Semantic Anchoring and Motion Alignment for Instruction-Guided Video Editing
댓글