[논문리뷰] Targeted Neuron Modulation via Contrastive Pair Search
링크: 논문 PDF로 바로 열기
저자: Sam Herring, Jake Naviasky, Karan Malhotra et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Contrastive Neuron Attribution (CNA): LLM의 특정 행동(예: 유해성 거부)을 가장 잘 구분하는 MLP 뉴런의 희소한 하위 집합을 식별하는 방법론으로, 그라디언트나 보조 학습 없이 오직 순방향 패스만을 요구한다.
- Residual Stream: Transformer 모델에서 레이어 간에 전달되는 누적 신호로, 기존 Steering 방법론들이 개입하는 대상이다.
- MLP Neurons: Multi-Layer Perceptron (MLP) 레이어 내의 개별 뉴런으로, 본 논문에서는 이들의 활성화(activations)를 직접 조작하여 모델의 행동을 Steering한다.
- Ablation: 특정 뉴런의 활성화를 0으로 설정하여 해당 뉴런의 기능을 제거하거나 비활성화하는 기법이다.
- Generation Quality (Coherence): 생성된 텍스트의 반복되는 n-gram 비율의 보완(complement)으로 측정되는 지표로, 출력의 일관성과 비퇴화성을 평가한다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
LLM이 유해한 요청을 거부하도록 Instruction-tuning되지만, 이러한 Safety behavior의 Mechanistic basis는 여전히 불분명하다. 기존의 Residual-stream 기반 Steering 방법론(예: Contrastive Activation Addition, CAA)은 높은 개입 강도에서 출력의 Coherence를 저하시켜 실용적 적용에 한계가 있었다. 또한, Sparse autoencoders는 잡음에 민감하고 비싼 훈련 비용을 요구했다. 저자들은 Alignment robustness 개선 및 Safety behavior 우회 진단에 중요한 Refusal 메커니즘을 심층적으로 이해하고, 기존 방법론의 한계를 극복하기 위해 Neuron-level 개입 방식의 필요성을 제기한다. 기존 연구들은 Instruct 모델의 Late layers에서 Safety-related signals을 식별했지만, 이러한 신호가 Fine-tuning의 결과인지, 얼마나 Steering 가능한지는 명확하지 않았다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Contrastive Neuron Attribution (CNA)을 제안하며, 이는 Contrastive Discovery, Universal Neuron Filtering, Targeted Ablation for Causal Verification의 세 단계로 구성된다. Contrastive Discovery는 Positive 및 Negative 프롬프트 세트를 통해 MLP activations를 기록하고, 각 뉴런의 평균 활성화 차이를 계산하여 상위 0.1%의 뉴런을 Refusal circuit으로 선정한다. Universal Neuron Filtering을 통해 프롬프트 내용과 무관하게 항상 활성화되는 뉴런을 제거하며, Targeted Ablation을 통해 이 Refusal circuit의 activations에 스칼라 승수 m을 적용하여 인과 관계를 검증한다.
실험 결과, CNA는 Residual-stream Steering 방식인 CAA와 비교하여 현저히 우수한 성능을 보였다. CNA는 모든 Steering strength에서 Refusal rate를 단조적으로 감소시키면서도, 0.97 이상의 높은 Generation quality를 유지했다 [Figure 1, cite: 1]. 반면 CAA는 Steering strength 0.5 이상에서 Generation quality가 급격히 저하되었으며, 일부 모델에서는 degenerate한 출력을 생성했다 [Figure 1, cite: 1]. MMLU accuracy 측정에서도 CNA는 모든 Steering strength에서 Baseline 대비 1점 이내의 정확도를 유지했으나, CAA는 최대 개입 시 거의 0에 가까운 정확도로 떨어졌다 [Figure 2, cite: 1]. 특히, JBB-Behaviors 벤치마크에서 전체 MLP activations 중 단 0.1%만을 Ablating하는 것만으로 Instruct 모델의 Refusal rates를 대부분의 경우 50% 이상 감소시켰으며, 일부 모델에서는 97.7%까지 감소시키는 결과를 보였다 [Table 3, cite: 1]. 이러한 Ablation은 Coherent하고 Useful한 응답을 생성하며, Refusal circuit이 Otherwise capable model 위에 Overlay된 Refusal gate로 기능함을 확인했다. Base 모델에서는 동일한 Steering에도 Refusal 행동 변화가 없었으며, Fine-tuning이 Late-layer discrimination structure를 Sparse하고 Targeting 가능한 Refusal gate로 변환함을 시사한다 [Table 4, cite: 1].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Contrastive Neuron Attribution (CNA)을 통해 Alignment fine-tuning이 기존의 Late-layer discrimination structure를 기능적인 Refusal mechanism으로 변환시킨다는 것을 밝혔다. Base 모델에서는 동일한 구조가 Content shifts만을 유발하는 반면, Instruct 모델에서는 Behavioral change를 이끌어낸다. 단 0.1% 미만의 MLP activations에 개입함으로써, Tested architecture에서 50% 이상의 Refusal rates 감소를 달성하면서도 Coherent output을 보존했다. 이는 기존 Residual-stream Steering 방법론의 Generation degradation 문제를 해결하며, Neuron-level intervention이 LLM의 Safety behavior를 정밀하게 Steering할 수 있음을 입증한다. 이 연구는 LLM의 Alignment 메커니즘을 심층적으로 이해하는 데 기여하며, 향후 더욱 Robust한 Alignment methods 개발의 토대가 될 수 있다.
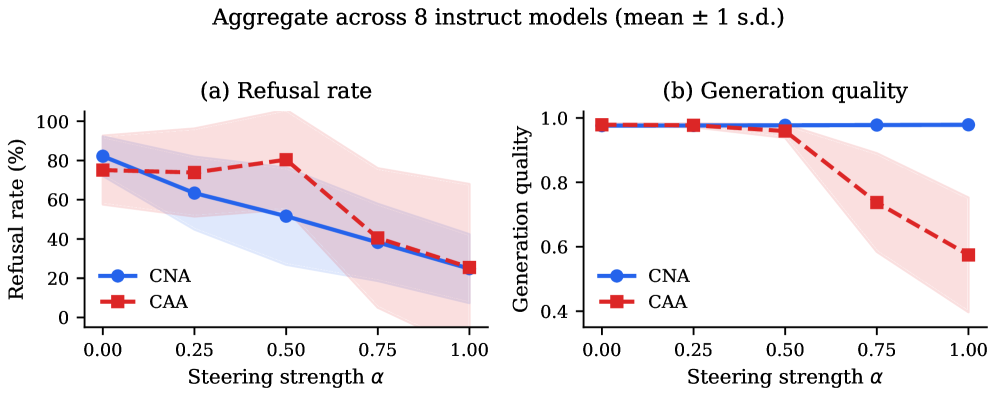
Figure 1 — 거부율 및 품질
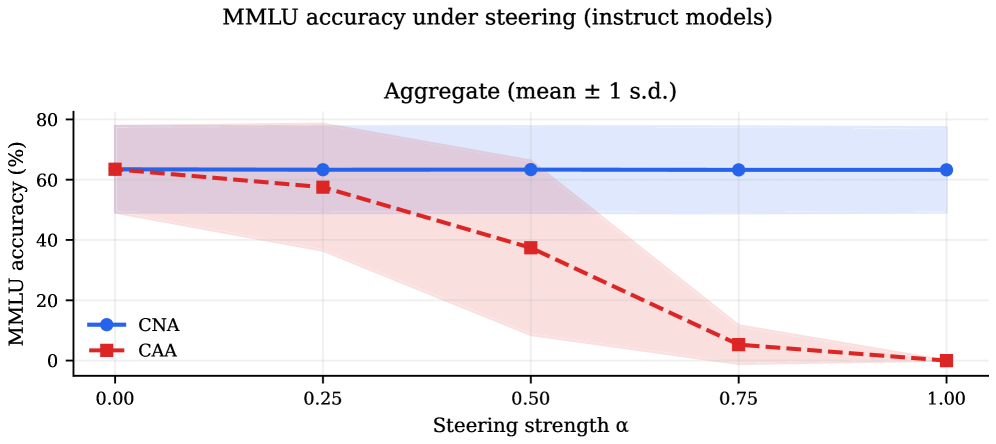
Figure 2 — MMLU 정확도 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Friends and Grandmothers in Silico: Localizing Entity Cells in Language Models
- [논문리뷰] MultAttnAttrib: Training-Free Multimodal Attribution in Long Document Question Answering
- [논문리뷰] Logit-Contribution Scoring Identifies Non-Literal Retrieval Heads
- [논문리뷰] Bag of Dims: Training-Free Mechanistic Interpretability via Dimension-Level Sign Patterns
- [논문리뷰] Unstable Features, Reproducible Subspaces: Understanding Seed Dependence in Sparse Autoencoders
Review 의 다른글
- 이전글 [논문리뷰] TOBench: A Task-Oriented Omni-Modal Benchmark for Real-World Tool-Using Agents
- 현재글 : [논문리뷰] Targeted Neuron Modulation via Contrastive Pair Search
- 다음글 [논문리뷰] VideoSeeker: Incentivizing Instance-level Video Understanding via Native Agentic Tool Invocation
댓글