[논문리뷰] TOBench: A Task-Oriented Omni-Modal Benchmark for Real-World Tool-Using Agents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zhiqiang Liu, Wenhui Dong, Yilang Tan, Yuwen Qu, Haochen Yin, Chenyang Si
1. Key Terms & Definitions (핵심 용어 및 정의)
- MCP (Model Context Protocol): Agent가 다양한 외부 도구 및 서비스와 상호작용하기 위한 표준 인터페이스 프로토콜입니다.
- Closed-loop Multimodal Verification: Agent가 도구를 실행한 후, 생성된 결과물(Artifact)을 시각적으로 검사(Inspect)하고 필요 시 수정(Revise)하는 전체 루프를 의미합니다.
- Task-Oriented Omni-modal Benchmark: 텍스트, 이미지, 오디오, 비디오 등 다중 모달리티 입력을 처리하고 도구를 사용하여 실제 전문적인 워크플로우를 완수하는 능력을 평가하는 벤치마크입니다.
- Grounded Evaluator: 정적 정답 비교가 아닌, 실행 시점(Execution-time)에 코드 기반 검사, VLM(Vision-Language Model) 판정, 도구 로그 확인 등을 통해 작업 성공 여부를 결정하는 프로그램입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 실세계의 복잡한 전문 워크플로우를 수행하는 Agent의 능력과 이를 평가하는 기존 벤치마크 사이의 격차를 해소하고자 합니다. 기존 연구들은 Tool-use, Computer-use, Multimodal reasoning 능력을 개별적으로 평가하는 경향이 있어, 실무에서 요구되는 'perceive–act–inspect–revise'의 전 과정을 종합적으로 검증하지 못합니다 [Figure 1]. 이러한 불연속성은 Agent가 도구 사용 후 중간 결과물을 제대로 검증하지 않고 성급히 종료하거나, 잘못된 작업 결과를 생성하게 만드는 주요 원인이 됩니다. 따라서 본 연구는 이러한 closed-loop 프로세스를 평가할 수 있는 실행 가능한 벤치마크 프레임워크인 TOBench를 제안합니다.
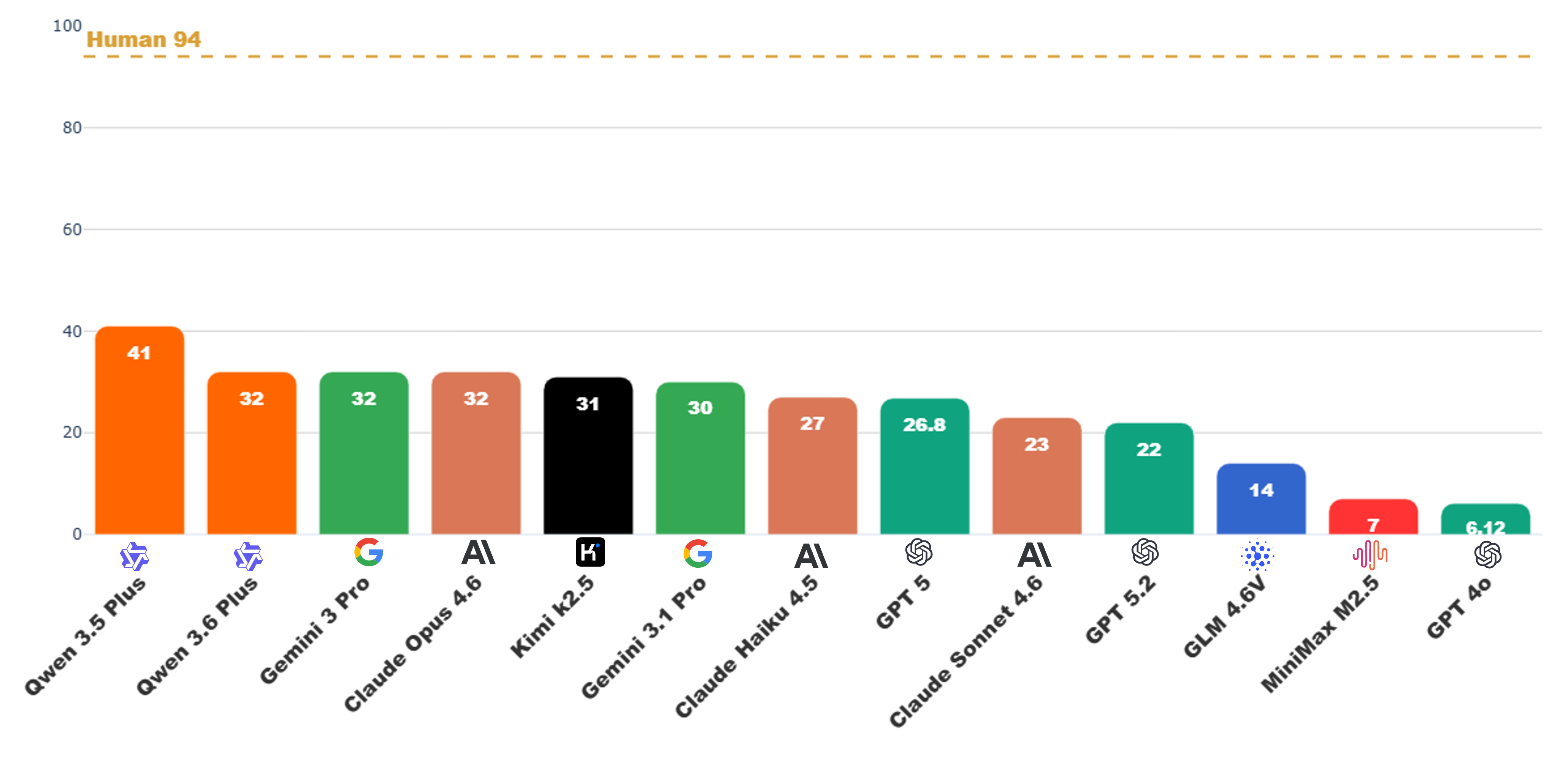
Figure 1 — 모델별 TOBench 성능
3. Method & Key Results (제안 방법론 및 핵심 결과)
TOBench는 Customer Service와 Intelligent Creation이라는 두 가지 매크로 태스크 패밀리 내에서 100개의 실행 가능한 과제를 설계하였습니다. 본 방법론은 27개의 MCP 서버와 324개의 도구를 통합하여, 문서 편집, 영상 제작, 검색 및 분석 등 실제 실무 환경을 재현합니다 [Figure 2]. 핵심적으로 각 과제는 작업별 Grounded Evaluator와 결합되어, Agent가 생성한 아티팩트를 중간에 검증하고 오류를 수정하는 능력을 정량적으로 측정합니다 [Figure 4]. 실험 결과, 최신 15개 모델 중 Qwen3.5-Plus가 가장 높은 41.0%의 성공률을 기록했으며, 강력한 코딩 모델로 평가받는 Claude-Opus-4.6조차 32.0%의 성공률에 그쳐 인간의 기준인 94.0%와 현격한 차이를 보였습니다 [Figure 1]. 오류 분석 결과, 성능 저하의 주요 요인은 도구 파라미터 지정 오류, 멀티모달 추론 능력 부족, 그리고 도구 실행 후 적절한 자기 검증(Self-verification) 미비로 확인되었습니다 [Figure 5].
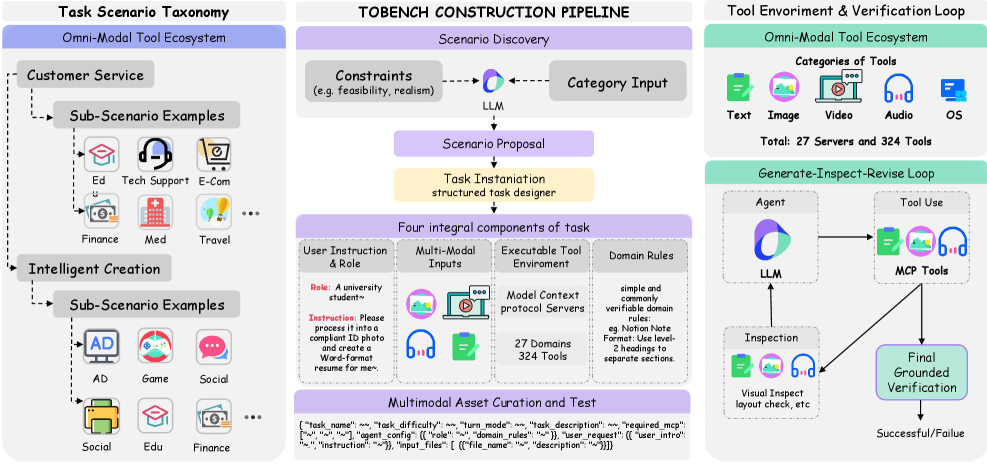
Figure 2 — TOBench 구축 파이프라인
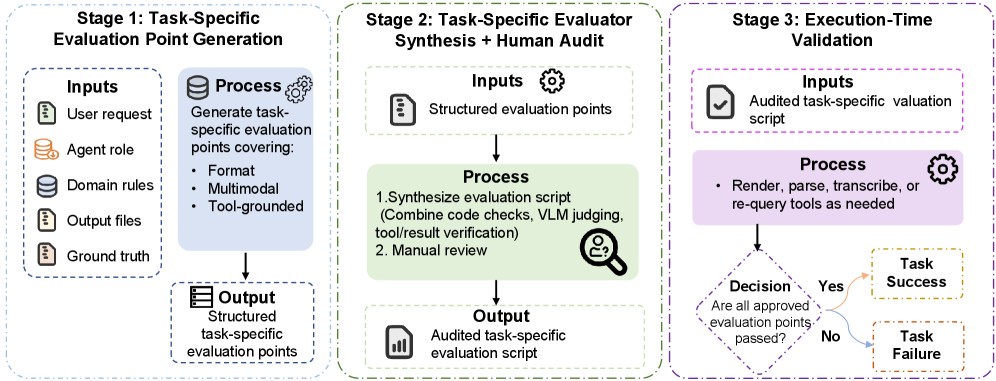
Figure 4 — 평가 프레임워크 개요
4. Conclusion & Impact (결론 및 시사점)
본 연구는 실제 전문적인 업무 환경에서 Agent의 능력을 엄격히 평가하기 위해 TOBench를 도입하였으며, 이는 현대 LLM 기반 Agent들이 실무 워크플로우를 완수하는 데 있어 근본적인 한계를 가지고 있음을 입증합니다. 특히 closed-loop multimodal verification의 중요성을 강조함으로써 향후 Agent 개발의 방향성을 제시하였습니다. 이 연구는 학계 및 산업계에서 보다 신뢰성 높고 자율적인 차세대 Omni-modal Agent를 설계하고 발전시키는 데 중요한 평가 기반(Testbed)이 될 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] AGORA: An Archive-Grounded Benchmark for Agentic Workplace Document Reasoning
- [논문리뷰] CHI-Bench: Can AI Agents Automate End-to-End, Long-Horizon, Policy-Rich Healthcare Workflows?
- [논문리뷰] EcoGym: Evaluating LLMs for Long-Horizon Plan-and-Execute in Interactive Economies
- [논문리뷰] ToolPRMBench: Evaluating and Advancing Process Reward Models for Tool-using Agents
- [논문리뷰] Watching, Reasoning, and Searching: A Video Deep Research Benchmark on Open Web for Agentic Video Reasoning
Review 의 다른글
- 이전글 [논문리뷰] Stop When Reasoning Converges: Semantic-Preserving Early Exit for Reasoning Models
- 현재글 : [논문리뷰] TOBench: A Task-Oriented Omni-Modal Benchmark for Real-World Tool-Using Agents
- 다음글 [논문리뷰] Targeted Neuron Modulation via Contrastive Pair Search
댓글