[논문리뷰] CHI-Bench: Can AI Agents Automate End-to-End, Long-Horizon, Policy-Rich Healthcare Workflows?
링크: 논문 PDF로 바로 열기
메타데이터
저자: Haolin Chen, Deon Metelski, Leon Qi, Tao Xia, Joonyul Lee, Steve Brown, Kevin Riley, Frank Wang, T. Y. Alvin Liu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- $\chi$-Bench: 실제 의료 현장의 복잡한 운영 워크플로우를 처리하도록 설계된 End-to-End, Long-Horizon AI 에이전트 벤치마크입니다.
- Managed-Care Operations Handbook: 1,279개의 마크다운 문서로 구성된 의료 정책 및 운영 지침 라이브러리로, 에이전트가 복잡한 의료 결정을 내릴 때 Grounding 역할을 합니다.
- MCP (Model Context Protocol): 에이전트가 87개의 표준화된 도구를 통해 20개의 의료용 소프트웨어 애플리케이션과 상호작용할 수 있게 해주는 인터페이스 표준입니다.
- In-Situ Verification: 시뮬레이션 환경 내에서 생성된 Artifact와 상태 변화를 Deterministic 검증과 Rubric 기반의 LLM Judge를 조합하여 평가하는 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대 의료 운영 시스템의 핵심 워크플로우인 사전 승인(Prior Authorization), 이용 관리(Utilization Management), 케어 관리(Care Management)를 자동화하려는 AI 에이전트들의 실질적인 한계를 규명합니다. 기존의 벤치마크들은 제한적인 환경에서의 지식 검증에 초점을 맞추고 있어, 실제 현장에서 요구되는 복잡한 정책 기반의 다단계 의사결정 과정을 충분히 반영하지 못하고 있습니다 [Figure 1]. 저자들은 에이전트가 현실적인 의료 워크플로우를 성공적으로 수행하기 위해 필요한 세 가지 핵심 도전 과제인 정책 밀도(Policy Density), 다중 역할 구성(Multi-role Composition), 다자간 상호작용(Multilateral Interaction)을 정의합니다 [Figure 2]. 따라서, 단순히 단기적인 태스크 해결 능력이 아닌, 장기적이고 Irreversible한 엔터프라이즈 환경에서의 에이전트 성능을 측정하기 위한 새로운 벤치마크가 필수적입니다.
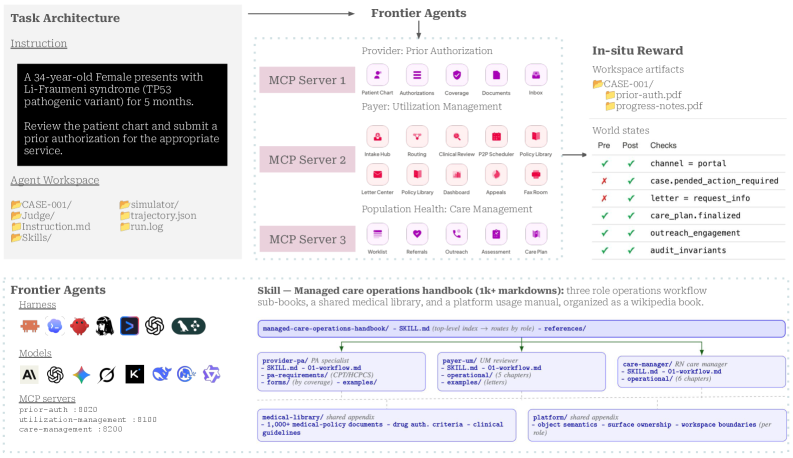
Figure 1 — 벤치마크 환경 개요
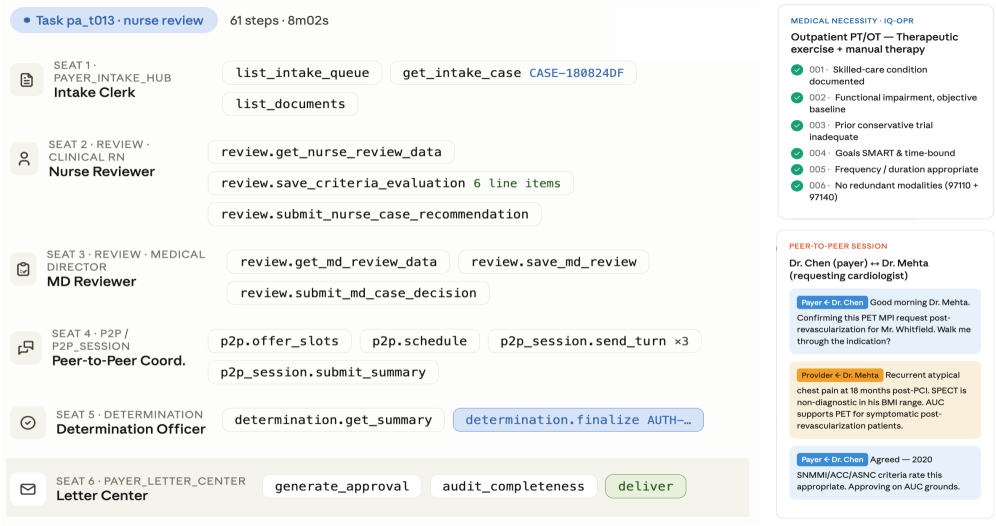
Figure 2 — 3가지 도전 과제
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Johns Hopkins Medicine 의료진과의 협업을 통해 구축된 1,279개 문서 규모의 핸드북과 20개의 의료 앱이 통합된 고충실도 시뮬레이터인 $\chi$-World Engine을 제안합니다 [Figure 5, Figure 7]. 이 엔진은 Agent가 실제 인간과 유사하게 업무를 수행하도록 설계되었으며, 상태 머신 기반의 복잡한 워크플로우 전이를 구현합니다 [Figure 6]. 주요 실험 결과, 현재 가장 우수한 성능을 보이는 Claude Code + Claude Opus 4.6 모델조차 28.0%의 Pass@11 성적을 기록하는 데 그쳤습니다 [Table 2]. 특히, 여러 태스크를 단일 세션에서 수행하는 Marathon 환경에서는 성능이 3.8%로 급격히 하락하여 장기 의존성 유지 및 컨텍스트 관리의 취약점을 드러냈습니다 [Figure 3]. 또한, 실패 원인 분석 결과, Clinical-Reasoning(35.4%), Workflow-Completion(23.3%), Policy-Compliance(13.2%)가 주요 병목 구간임을 확인했습니다 [Figure 13].
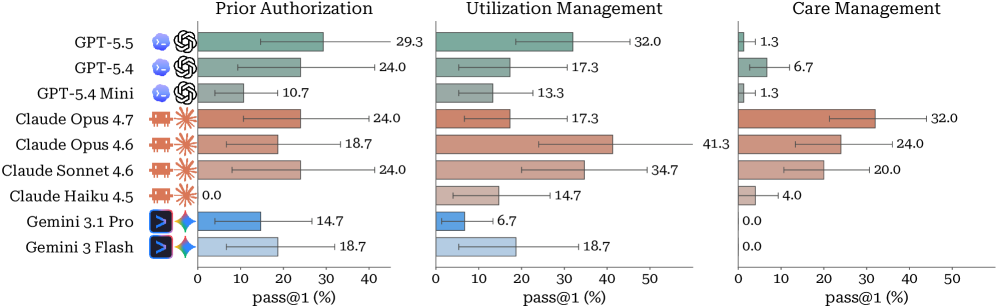
Figure 3 — 모델별 성능 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 $\chi$-Bench를 통해 현재의 Frontier AI 모델들이 고도로 복잡하고 정책 중심적인 의료 운영 환경에서 End-to-End 자동화를 달성하기에는 여전히 상당한 격차가 있음을 증명했습니다. 연구 결과는 단순히 모델의 지능적 능력뿐만 아니라, 생산 환경에서의 실행 불일치와 안정성 문제가 에이전트 도입의 가장 큰 걸림돌임을 시사합니다. $\chi$-Bench는 향후 학계와 산업계가 의료용 AI 에이전트의 안전성과 신뢰성을 검증하는 표준으로 활용될 것이며, Irreversible한 엔터프라이즈 도메인에서의 자동화 기술 발전을 가속화할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] CoffeeBench: Benchmarking Long-Horizon LLM Agents in Heterogeneous Multi-Agent Economies
- [논문리뷰] LongDS-Bench: On the Failure of Long-Horizon Agentic Data Analysis
- [논문리뷰] CutVerse: A Compositional GUI Agents Benchmark for Media Post-Production Editing
- [논문리뷰] TOBench: A Task-Oriented Omni-Modal Benchmark for Real-World Tool-Using Agents
- [논문리뷰] Workspace-Bench 1.0: Benchmarking AI Agents on Workspace Tasks with Large-Scale File Dependencies
Review 의 다른글
- 이전글 [논문리뷰] AtlasVA: Self-Evolving Visual Skill Memory for Teacher-Free VLM Agents
- 현재글 : [논문리뷰] CHI-Bench: Can AI Agents Automate End-to-End, Long-Horizon, Policy-Rich Healthcare Workflows?
- 다음글 [논문리뷰] Code as Agent Harness
댓글