[논문리뷰] AtlasVA: Self-Evolving Visual Skill Memory for Teacher-Free VLM Agents
링크: 논문 PDF로 바로 열기
저자: Pan Wang, Yihao Hu, Xiujin Liu, Jingchu Yang, Hang Wang, Zhihao Wen, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- AtlasVA: 시각적 경험을 공간 히트맵, 시각적 예시, 기호적 텍스트 계층으로 구조화하여 VLM 에이전트의 메모리 증강을 수행하는 프레임워크입니다.
- Visual Skill Memory (VSM): 기존의 텍스트 기반 메모리 한계를 극복하기 위해, 환경의 기하학적 구조를 시각적 모달리티 내에서 직접 저장하고 발전시키는 3계층 구조의 메모리 시스템입니다.
- Teacher-Free Evolution: 외부 LLM 교사 모델의 지도 없이, 에이전트 스스로의 환경 상호작용 로그와 통계치를 사용하여 spatial atlas를 개선하는 자가 학습 메커니즘입니다.
- Dense Visual Reward Shaping: 고정된 sparse reward 환경에서 에이전트의 학습 효율을 높이기 위해, 시각적 아틀라스의 potential function을 활용하여 매 스텝마다 밀도 높은 정렬 피드백을 제공하는 기법입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 기존 VLM 에이전트가 긴 호흡의 공간적 과업(long-horizon spatial tasks)을 수행할 때 발생하는 '공간적 맹목(spatial blindness)'과 '모달리티 불일치(modality mismatch)' 문제를 해결합니다. 대다수의 memory-augmented RL 시스템은 복잡한 공간 정보를 텍스트로 압축하여 저장함으로써 기하학적 구조를 손실시키고, 외부 LLM에 의존하여 메모리를 요약하므로 계산 비용이 높고 자율적인 자기 개선이 어렵습니다. 또한, sparse reward 체계는 에이전트에게 충분한 학습 피드백을 주지 못해 credit assignment 문제를 악화시킵니다. 따라서 저자들은 시각적 정보를 텍스트로 변환하지 않고 시각적 모달리티 그대로 보존 및 활용하는 새로운 메모리 프레임워크를 제안합니다 [Figure 1].
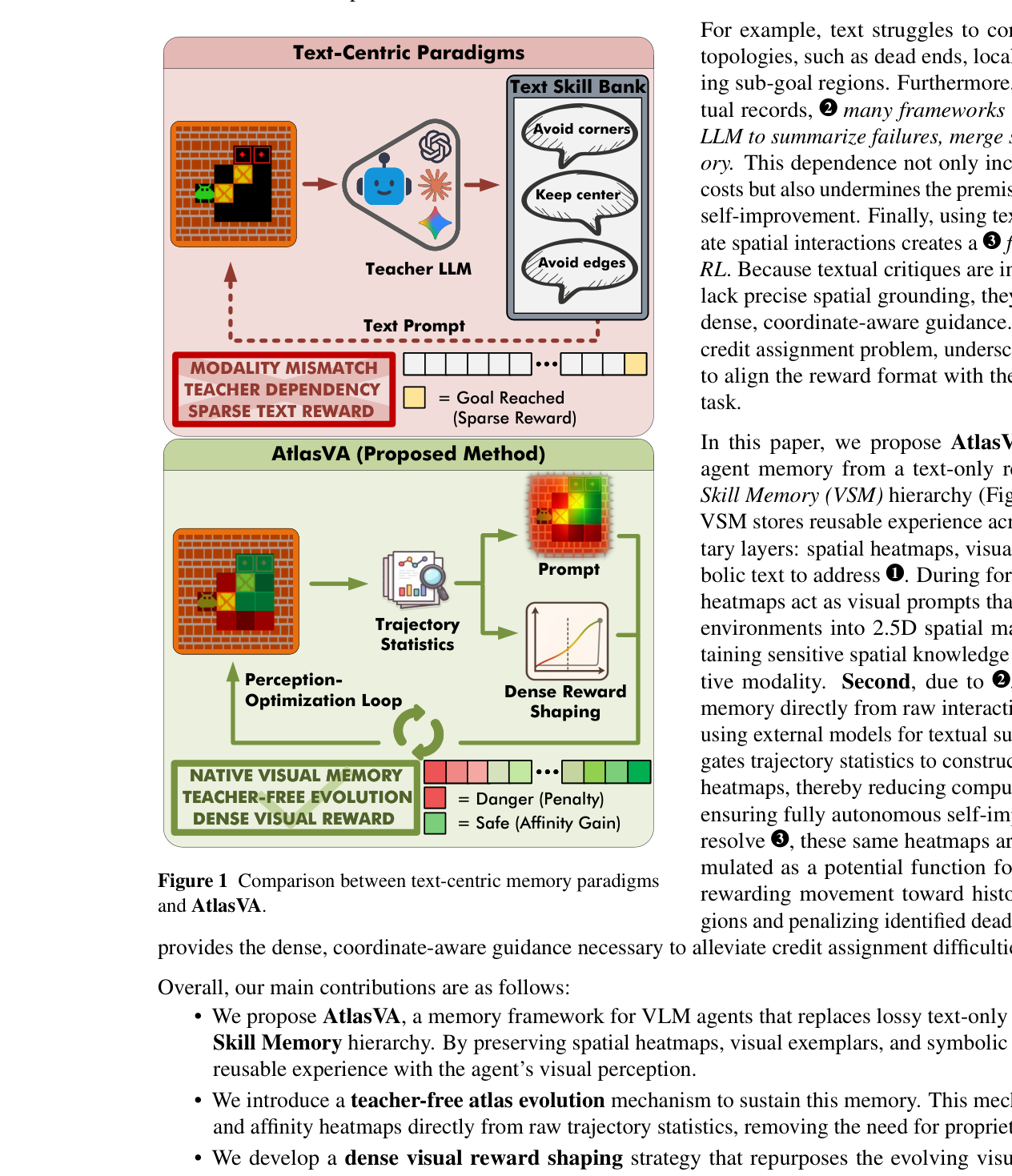
Figure 1 — 텍스트 중심 패러다임과 제안하는 AtlasVA 방식의 구조적 차이를 보여주는 핵심 비교 도표
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Visual Skill Memory(VSM) 계층과 self-evolving atlas를 통해 perceptional-optimization loop를 구축합니다. 에이전트는 trajectory 통계와 static heuristics를 EMA(Exponential Moving Average)로 결합하여 위험(Danger) 및 친화도(Affinity) 히트맵을 지속적으로 업데이트하며, 이를 potential function으로 변환하여 dense reward를 형성합니다 [Figure 2]. 주요 실험 결과, 3B 파라미터 기반의 AtlasVA는 Sokoban, FrozenLake, 3D Navigation, PrimitiveSkill 등 다양한 벤치마크에서 GPT-5나 o3와 같은 대형 독점 모델들을 크게 상회하는 성능을 보였습니다. 특히 3D 로봇 조작 과업에서 1.0의 완벽한 성공률을 기록했으며, VAGEN 등 기존 최신 오픈 소스 베이스라인 대비 압도적인 평균 성공률(0.93)을 달성하였습니다 [Table 2]. 이는 제안하는 기법이 공간적 제약이 심한 과업에서 텍스트 기반 방법론보다 월등히 우수함을 실증합니다.

Figure 2 — VSM, Teacher-Free Atlas Evolution, Reward Shaping으로 이어지는 전체 시스템 아키텍처
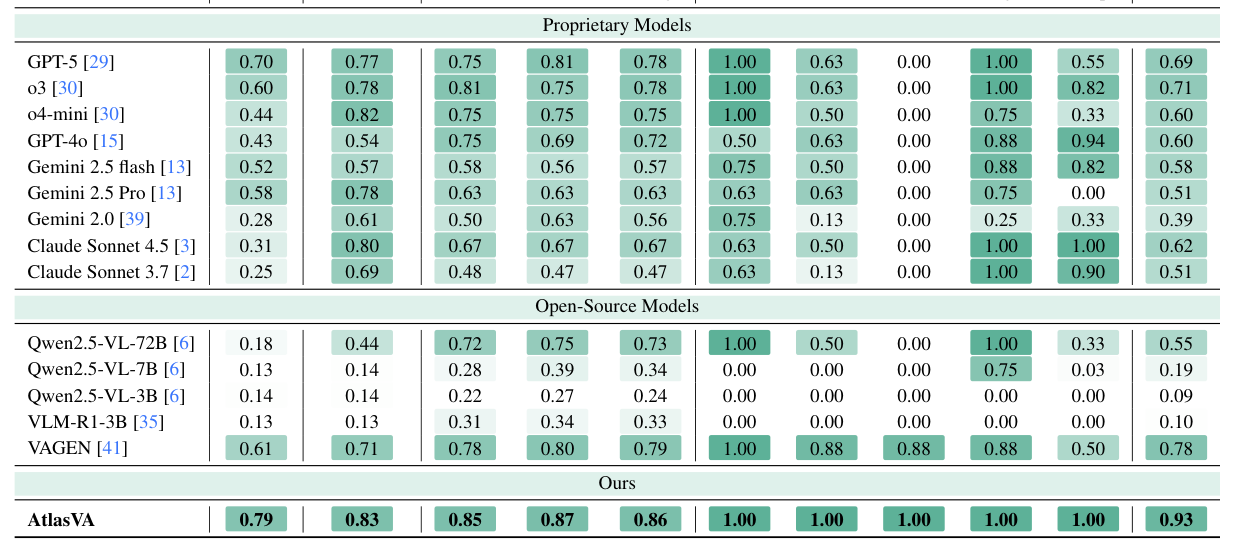
Table 2 — 다양한 벤치마크에서 AtlasVA와 기존 모델들의 성공률을 비교한 핵심 결과 테이블
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 Teacher-free 메커니즘을 통해 VLM 에이전트의 공간 추론 능력을 극대화하는 혁신적인 시각적 메모리 프레임워크를 제시합니다. 제안된 AtlasVA는 별도의 교사 모델 없이도 환경으로부터 기하학적 우선순위를 스스로 학습하고 이를 밀도 높은 보상 신호로 전환함으로써 RL 에이전트의 샘플 효율성을 획기적으로 개선하였습니다. 이 연구는 향후 복잡한 물리적 환경에서 자율적으로 적응하고 발전해야 하는 embodied AI 에이전트 설계에 중요한 이정표가 될 것이며, 모달리티 보존 메모리 아키텍처의 중요성을 입증했습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Think3D: Thinking with Space for Spatial Reasoning
- [논문리뷰] MentalThink: Shaping Thoughts in Mental SVG World
- [논문리뷰] Thinking with Visual Grounding
- [논문리뷰] AlloSpatial: Agentic Harness Framework for Spatial Reasoning in Foundation Models
- [논문리뷰] Thinking with Imagination: Agentic Visual Spatial Reasoning with World Simulators
Review 의 다른글
- 이전글 [논문리뷰] AgentKernelArena: Generalization-Aware Benchmarking of GPU Kernel Optimization Agents
- 현재글 : [논문리뷰] AtlasVA: Self-Evolving Visual Skill Memory for Teacher-Free VLM Agents
- 다음글 [논문리뷰] CHI-Bench: Can AI Agents Automate End-to-End, Long-Horizon, Policy-Rich Healthcare Workflows?
댓글