[논문리뷰] A Subgoal-driven Framework for Improving Long-Horizon LLM Agents
링크: 논문 PDF로 바로 열기
Do not chat.## Part 1: 요약 본문
저자: Taiyi Wang, Sian Gooding, Florian Hartmann, Oriana Riva, Edward Grefenstette et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Long-Horizon LLM Agents : 복잡하고 긴 일련의 상호작용이 필요한 디지털 환경(예: 웹 브라우저, 운영 체제)에서 자율적으로 작업을 수행하는 대규모 언어 모델 기반 에이전트. 기존 에이전트들은 장기적인 계획(long-horizon planning) 능력에서 한계를 보였다.
- Subgoal Decomposition : 최종 목표(final goal)를 달성하기 위해 중간 단계의 작고 명확한 목표(subgoals)들로 task를 분해하는 전략. 이는 에이전트의 계획 능력을 향상시키고 dense feedback을 제공하는 데 활용된다.
- MiRA (Milestoning your Reinforcement Learning Enhanced Agent) : Milestone-based reward signals을 사용하여 sparse and delayed rewards 문제를 해결하고 RL fine-tuning을 향상시키는 프레임워크. Potential-Based Reward Shaping (PBRS) 개념을 활용한다.
- Potential-Based Reward Shaping (PBRS) : 에이전트의 보상 함수에 potential function을 추가하여 학습 초기 단계에서 dense feedback을 제공하는 기법. 이는 optimal policy를 보존하면서 credit assignment를 용이하게 한다.
- WebArena-Lite : LLM 기반 웹 에이전트의 성능을 평가하기 위해 엄선된 웹 환경 벤치마크. 실제 웹 상호작용 시나리오를 시뮬레이션하며, 쇼핑, 지도, Gitlab 등 다양한 도메인을 포함한다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Large language model (LLM)-based agents는 디지털 환경에서 강력한 자율 제어기로 부상했지만, 특히 웹 내비게이션과 같이 동적인 콘텐츠와 긴 액션 시퀀스를 요구하는 복잡한 task에서 long-horizon planning 능력의 약점을 드러낸다. 기존 에이전트들은 온라인 실행 시 새로운 정보가 유입되면 목표를 추적하는 데 어려움을 겪고, RL fine-tuning 과정에서는 sparse and delayed rewards로 인해 성공으로 이어지는 액션을 식별하기 어렵다는 한계가 있다.
연구자들은 WebArena-Lite 벤치마크에서 Gemini-2.5-Pro 와 같은 proprietary 모델조차 평가 trajectory의 약 50% 에서 "mid-task stuck" (중간에 멈춤) 현상을 보이는 것을 정량적으로 분석하여 이러한 문제점을 지적한다. 이는 에이전트가 비생산적인 액션 루프에 빠지거나 suboptimal goal path를 따르게 되어 다음 논리적인 milestone을 식별하지 못하는 데서 기인한다. 이러한 실패 모드는 모델 규모나 fine-tuning 방식과 무관하게 나타나며, 기존 연구들이 제시한 interleaved reasoning traces, static decomposition strategies, tree-based search 등도 이러한 한계를 완전히 해결하지 못했다. 따라서, 명시적인 milestones 또는 subgoals를 도입하여 에이전트의 진행 상황을 안내하는 새로운 접근 방식이 필요하다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 long-horizon LLM agents의 성능 향상을 위해 subgoal-driven framework 를 제안하며, 이는 온라인 추론 시 subgoal decomposition 기반 계획과 오프라인 RL fine-tuning 시 milestone-based reward signals (MiRA)을 통합한다
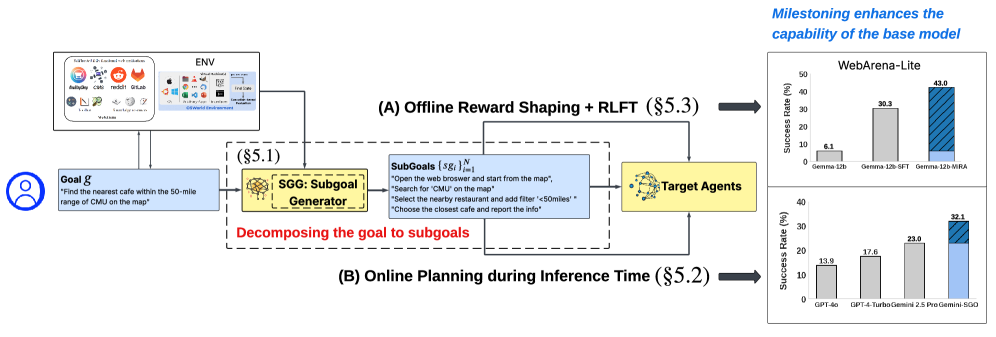
먼저, Gemini-2.5-Pro teacher model을 활용하여 high-level task description과 현재 웹 상태로부터 subgoals를 생성한다. 이 subgoal들은 AUROC 0.84 , Kendall’s $\tau$ 0.4585 (p<0.001)의 높은 discriminative power 와 monotonicity 를 보이며, 에이전트의 진행 상황을 신뢰할 수 있는 continuous progress indicator로 작동함이 검증되었다 [Figure 4].
온라인 추론(online inference) 시에는 Dynamic Milestoning Framework
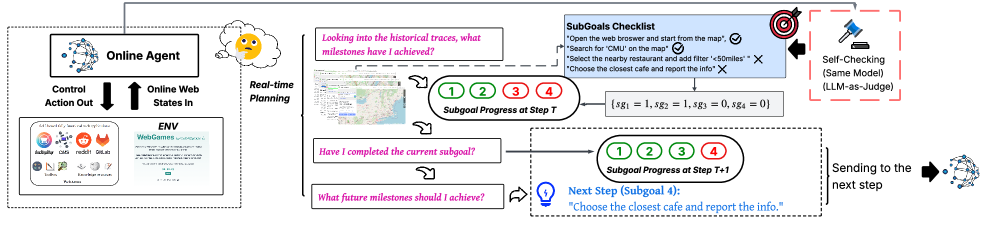
를 통해 생성된 subgoals를 동적 체크포인트로 활용하여 에이전트가 행동하기 전에 "사고"하도록 유도한다. 에이전트는 과거 상호작용 기록을 자체적으로 성찰(retrospective reflection)하여 달성한 milestone을 확인하고, 이를 통해 에러 전파를 완화하며 다음 계획 단계를 지시한다. 그 결과, Gemini-SGO 는 Gemini-2.5-Pro 대비 평균 Success Rate (SR)를 약 10% (23.0% → 32.1% ) 향상시켰으며, Stuck Midway 에러를 48.41% 에서 39.87% 로 크게 감소시켰다 [Table 3, Table 4].
오프라인 RL fine-tuning 단계에서는 MiRA (Milestoning your Reinforcement Learning Enhanced Agent) 프레임워크
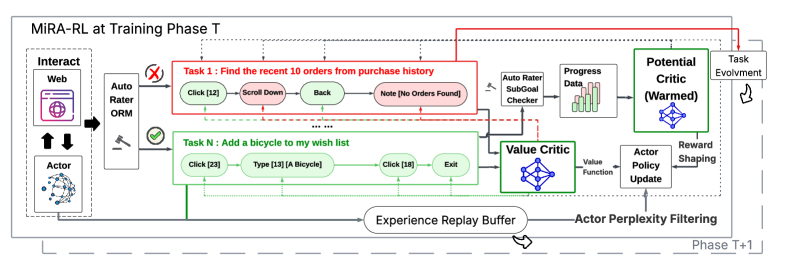
를 도입하여 subgoal-level feedback을 dense reward signal로 제공한다. MiRA는 Goal-conditioned value critic 과 Potential critic 의 이중 critic architecture를 사용한다. Potential critic은 linear interpolation을 통해 discrete subgoal completion signal을 continuous progress label로 변환하여 학습되며 [Figure 7], 이를 통해 dense shaping reward를 제공한다. Actor는 Relative Entropy Regularized Reinforcement Learning 의 프레임워크 내에서 MSE regression objective (Eq.)를 통해 최적화된다. Gemma3 + MiRA 는 WebArena-Lite 벤치마크에서 평균 SR 43.0% 를 달성하여, 기존의 SOTA 모델인 WebRL (35.1%)과 DigiRL (33.3%)을 능가했으며, 심지어 GPT-4-Turbo (17.6%)나 GPT-4o (13.9%)와 같은 proprietary 모델보다도 우수한 성능을 보였다 [Table 3]. 또한, MiRA의 ablation study 결과, Potential Critic , Doubly-Robust Advantage Estimation , MSE-based policy update 가 모두 성능 향상에 필수적인 요소임이 확인되었다 [Figure 11(b)].
## 4. Conclusion & Impact (결론 및 시사점)
본 연구는 동적 milestoning과 potential-based reinforcement learning을 통해 웹 에이전트의 long-horizon planning capabilities 를 향상시키는 포괄적인 프레임워크를 제시한다. 제안된 접근 방식은 명시적인 subgoal-driven planning 을 추론 단계에 통합하고, MiRA 를 통해 dense milestone-based reward signals로 RL fine-tuning을 수행함으로써, 기존 LLM 에이전트의 고질적인 long-horizon planning bottleneck 을 효과적으로 해결한다. 특히, 오픈소스 모델인 Gemma-3-12B 가 MiRA를 적용하여 43.0% 의 성공률을 달성, GPT-4-Turbo 나 GPT-4o 와 같은 훨씬 큰 proprietary 시스템을 능가하는 state-of-the-art 성능을 보여주었다.
이 연구는 학계 및 산업계에 다음과 같은 중요한 시사점을 제공한다. 첫째, automated process supervision 이 noisy하고 비정상적인 웹 환경에서 RL을 확장하는 실현 가능한 경로임을 입증했다. 둘째, planning-oriented failures를 지배적인 에러 모드로 식별하고 이를 dense subgoal feedback으로 해결함으로써, LLM 에이전트의 한계에 대한 명확한 과학적 통찰력을 제공한다. 마지막으로, 단일 모델(예: Gemini-2.5-pro )이 경로 계획, 행동 실행, 자기 진단, 실패 기반 커리큘럼 생성, 후속 모델 학습을 위한 shaping signals 생성 등 여러 역할을 수행하는 self-evolving autonomous agents 의 실현 가능성을 보여주며, 이는 미래의 자율 시스템 개발 방향에 중요한 이정표를 제시한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Tool-R0: Self-Evolving LLM Agents for Tool-Learning from Zero Data
- [논문리뷰] GenEnv: Difficulty-Aligned Co-Evolution Between LLM Agents and Environment Simulators
- [논문리뷰] Achieving Olympia-Level Geometry Large Language Model Agent via Complexity Boosting Reinforcement Learning
- [논문리뷰] Agent-R1: Training Powerful LLM Agents with End-to-End Reinforcement Learning
- [논문리뷰] Scaling Agent Learning via Experience Synthesis
Review 의 다른글
- 이전글 [논문리뷰] VTC-Bench: Evaluating Agentic Multimodal Models via Compositional Visual Tool Chaining
- 현재글 : [논문리뷰] A Subgoal-driven Framework for Improving Long-Horizon LLM Agents
- 다음글 [논문리뷰] AgentDS Technical Report: Benchmarking the Future of Human-AI Collaboration in Domain-Specific Data Science
댓글