[논문리뷰] Insight-V++: Towards Advanced Long-Chain Visual Reasoning with Multimodal Large Language Models
링크: 논문 PDF로 바로 열기
저자: Yuhao Dong, Zuyan Liu, Shulin Tian, Yongming Rao, Ziwei Liu et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- MLLMs (Multimodal Large Language Models) : 텍스트와 이미지/비디오와 같은 다양한 양식의 데이터를 이해하고 처리할 수 있는 Large Language Models.
- Long-Chain Visual Reasoning : 여러 단계의 추론 과정을 거쳐 시각 정보를 분석하고 복잡한 질문에 답하는 능력.
- ST-GRPO (Spatial-Temporal Group Relative Policy Optimization) : Reasoning Agent의 공간-시간 추론 능력을 강화하기 위해 고안된 강화 학습 알고리즘.
- J-GRPO (Judge Group Relative Policy Optimization) : Summary Agent의 평가 강건성(evaluative robustness)을 향상시키기 위한 강화 학습 알고리즘.
- Self-Evolving System : 에이전트 간의 반복적인 피드백 루프를 통해 자체적으로 추론 능력을 지속적으로 개선하고 데이터 품질을 향상시키는 시스템.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Large Language Models (LLMs)는 Chain-of-Thought prompting과 같은 확장된 추론을 통해 상당한 발전을 이루었지만, 이를 Multi-modal Large Language Models (MLLMs)로 확장하는 것은 여전히 큰 도전 과제입니다. 핵심적인 문제는 고품질의 Long-Chain Visual Reasoning data 가 부족하고, 이러한 복잡한 데이터를 MLLMs에 효과적으로 학습시킬 최적화된 training pipelines 이 부재하다는 점입니다. 기존 MLLMs는 시각적 단서를 활용하여 단계별 문제 해결을 정밀하게 수행하는 데 한계가 있으며, 특히 정적 이미지(static images)를 넘어 동적인 비디오 환경에서의 추론(video reasoning)으로 확장할 때 복잡성이 더욱 증가합니다. 기존의 데이터 생성 파이프라인과 훈련 전략은 이러한 동적 미묘함을 포착하기에 부적절하며, 고정된(static), 비적응적인(non-adaptive) 훈련 패러다임은 일반화된 추론 능력의 상한선을 제한합니다. 이에 저자들은 MLLMs가 스스로 추론 능력을 지속적으로 개선하고 확장할 수 있는 효과적인 훈련 절차의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Insight-V++ 라는 이름의 고급 Long-Chain Visual Reasoning 을 위한 통합 Multi-Agent Visual Reasoning Framework 를 제안합니다. 이 프레임워크는 이미지(image)와 비디오(video) 도메인 모두에서 구조화되고 복잡한 추론 궤적을 자율적으로 합성하는 확장 가능하고 점진적인 데이터 생성 파이프라인으로 시작합니다. 특히, 비디오 데이터의 경우 in-context examples 를 활용한 고급 데이터 스코어링 전략을 도입하여 고품질 비디오 추론 데이터 생성을 개선합니다
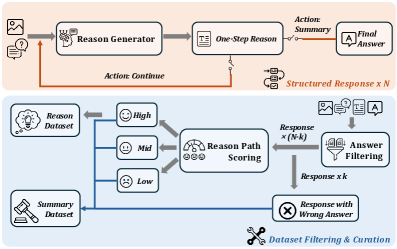
Insight-V 프레임워크는 추론(reasoning)과 요약(summarization)을 분리하는 이중 에이전트 아키텍처를 채택합니다. Reasoning Agent 는 상세한 추론 과정을 생성하고, Summary Agent 는 최종 결과를 비판적으로 평가하고 요약합니다. 초기 Insight-V는 iterative Direct Preference Optimization (DPO) 알고리즘을 사용하여 생성을 안정화했지만, DPO 의 off-policy 특성이 강화 학습(RL) 잠재력을 제한했습니다.
Insight-V++ 는 이러한 한계를 극복하기 위해 두 가지 새로운 강화 학습 알고리즘인 ST-GRPO 와 J-GRPO 를 도입합니다. ST-GRPO 는 Reasoning Agent 의 공간-시간(spatial-temporal) 추론 능력을 특별히 향상시키고, J-GRPO 는 Summary Agent 의 평가 강건성을 근본적으로 개선합니다
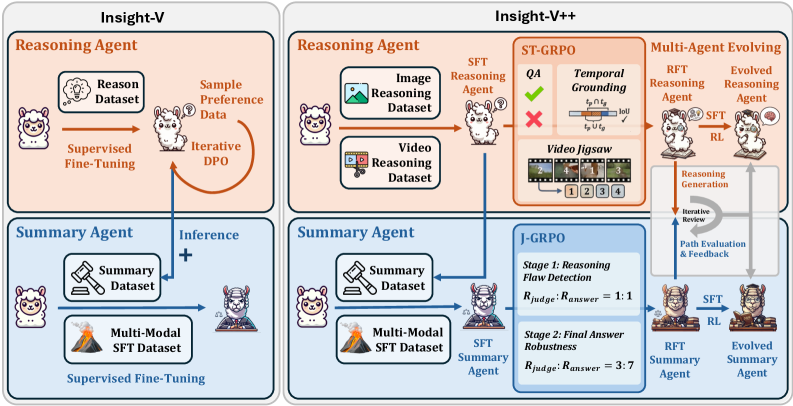
또한, Insight-V++ 의 핵심 혁신은 새로운 Self-Evolving Training Strategy 를 통해 모듈들을 더욱 긴밀하게 통합하는 데 있습니다. 잘 훈련된 Summary Agent 의 신뢰할 수 있는 피드백 신호를 활용하여 반복적인 추론 경로 생성 과정을 유도하고, 시스템이 자율적으로 우수하고 정제된 데이터를 생성하도록 합니다. 이 데이터는 전체 Multi-Agent System 을 지속적으로 재훈련하는 데 사용됩니다.
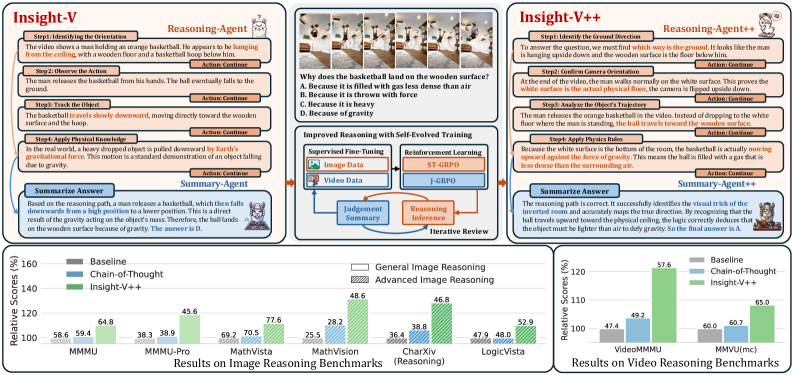
광범위한 실험 결과에 따르면, LLaVA-NeXT 기반의 Insight-V는 6개의 시각 추론 벤치마크에서 평균 8.1% 의 성능 향상을 달성했습니다. 더 강력한 Qwen2.5-VL 기반의 Insight-V++는 일반 이미지 추론 벤치마크에서 +4.8% 의 추가 개선을 보였고, 고복잡성 이미지 태스크에서 평균 53.9 점을 기록하여 이전 모델들을 크게 능가했습니다. 비디오 도메인에서는 6개 비디오 추론 벤치마크에서 평균 +6.9% 의 뛰어난 향상을 달성하며 기존 베이스라인을 크게 넘어섰습니다. [Table I, Table II, Table III]
4. Conclusion & Impact (결론 및 시사점)
저자들은 Insight-V 시리즈를 통해 MLLMs의 Long-Chain Visual Reasoning 능력을 크게 향상시키는 확장 가능하고 효율적인 Multi-Agent Training Framework 를 제안했습니다. 특히, Insight-V++ 는 GRPO-based Reinforcement Learning Strategy 와 비디오 추론 태스크로의 확장을 통해 시스템을 강화합니다. 핵심적으로 도입된 Self-Evolving Architecture 는 에이전트들이 협력하고 공동으로 발전(co-evolve)하도록 하여 지속적인 성능 개선을 이끌어냅니다. 이 연구는 다양한 벤치마크에서 제안된 접근 방식의 효과를 입증하며, 더 강력하고 일반화 가능한 추론 능력을 갖춘 MLLMs 개발의 길을 열었습니다. 이는 고품질 멀티모달 데이터 부족 문제를 자율적으로 극복하고, 강력한 On-Policy Reinforcement Learning 을 통해 장기적 추론을 안정화하여 차세대 범용 시각 추론 모델 개발에 확장 가능하며 주석 없는(annotation-free) 경로를 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OneThinker: All-in-one Reasoning Model for Image and Video
- [논문리뷰] Orchestra-o1: Omnimodal Agent Orchestration
- [논문리뷰] VideoKR: Towards Knowledge- and Reasoning-Intensive Video Understanding
- [논문리뷰] EvoDS: Self-Evolving Autonomous Data Science Agent with Skill Learning and Context Management
- [논문리뷰] TRON: Targeted Rule-Verifiable Online Environments for Visual Reasoning RL
Review 의 다른글
- 이전글 [논문리뷰] Group3D: MLLM-Driven Semantic Grouping for Open-Vocabulary 3D Object Detection
- 현재글 : [논문리뷰] Insight-V++: Towards Advanced Long-Chain Visual Reasoning with Multimodal Large Language Models
- 다음글 [논문리뷰] LongCat-Flash-Prover: Advancing Native Formal Reasoning via Agentic Tool-Integrated Reinforcement Learning
댓글