[논문리뷰] Visual Reasoning through Tool-supervised Reinforcement Learning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Qihua Dong, Gozde Sahin, Pei Wang, Zhaowei Cai, Robik Shrestha, Hao Yang, Davide Modolo
1. Key Terms & Definitions (핵심 용어 및 정의)
- ToolsRL: 저자들이 제안하는 Tool-supervised Reinforcement Learning 프레임워크로, 도구 사용에 대한 명시적 감독(Tool supervision)을 통해 MLLM의 시각적 추론 능력을 강화하는 방법론입니다.
- Tool supervision: 단순한 최종 정답 보상(Task accuracy reward) 대신, 특정 도구 호출의 적절성을 평가하기 위해 사전에 구축된 도구별 보상 신호를 의미합니다.
- Two-Stage Curriculum: 도구 조작 능력을 먼저 학습하는 제1단계(Tool-supervision)와, 해당 도구를 활용하여 최종 정답 정확도를 극대화하는 제2단계(Task Accuracy)로 구성된 훈련 방식입니다.
- Native Visual Tools: Zoom-in, Rotate, Flip, Draw(point/line) 등 모델이 외부 의존성 없이 내부적으로 직접 호출하여 사용할 수 있는 시각적 조작 도구 집합입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 MLLM의 복잡한 시각적 추론을 위해 도구 사용 능력을 효과적으로 습득시키는 문제를 해결하고자 합니다. 기존의 Supervised Fine-Tuning(SFT) 방식은 고품질의 전문가 도구 사용 궤적을 구축하는 데 막대한 비용과 인력이 필요하다는 확장성 한계가 존재합니다. 또한, 기존 RL 기반 방법론들은 보상이 최종 과제 성과에만 집중되어 있거나 도구 호출에 대한 구체적인 가이드가 부족하여, 비효율적인 훈련 결과와 낮은 도구 호출 빈도를 초래합니다. 결과적으로 모델이 다단계 추론 체인을 형성하지 못하고 텍스트 기반 추론에 의존하는 문제가 발생하며, 저자들은 이를 해결하기 위해 도구 호출 자체에 명시적 피드백을 제공하는 새로운 RL 프레임워크가 필요함을 강조합니다 [Figure 1].

Figure 1 — ToolsRL을 통한 시각적 추론 예시
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Tool-supervision과 Task-accuracy 보상 간의 최적화 충돌을 방지하기 위해 2단계 커리큘럼 기반의 ToolsRL을 제안합니다 [Figure 2]. 제1단계에서는 Zoom-in, Rotate/Flip, Draw 작업에 대해 정의된 도구별 보상을 통해 도구 조작 패턴을 학습하고, 제2단계에서는 이러한 조작 능력을 유지한 채 최종 정답 정확도를 목표로 학습합니다. 특히 Zoom-in을 위해 재해석된 F1-style 보상인 ModF1과, 포인트/라인 드로잉을 위한 연속적인 마진 기반 보상(Continuous, margin-based reward)을 설계하여 학습 안정성을 확보했습니다. 실험 결과, ToolsRL은 DocVQA-RF 77.3%, InfoVQA-RF 61.4%의 성능을 기록하며 기존 SOTA 모델들을 큰 격차로 상회하였습니다. 또한 기존 방식이 평균 1회 미만의 도구 호출을 보인 반면, ToolsRL은 도구 사용 빈도를 평균 3.4회로 끌어올리며, 실제 복잡한 시각적 작업에서 다단계 도구 호출을 성공적으로 수행함을 증명하였습니다 [Table 1], [Table 4].
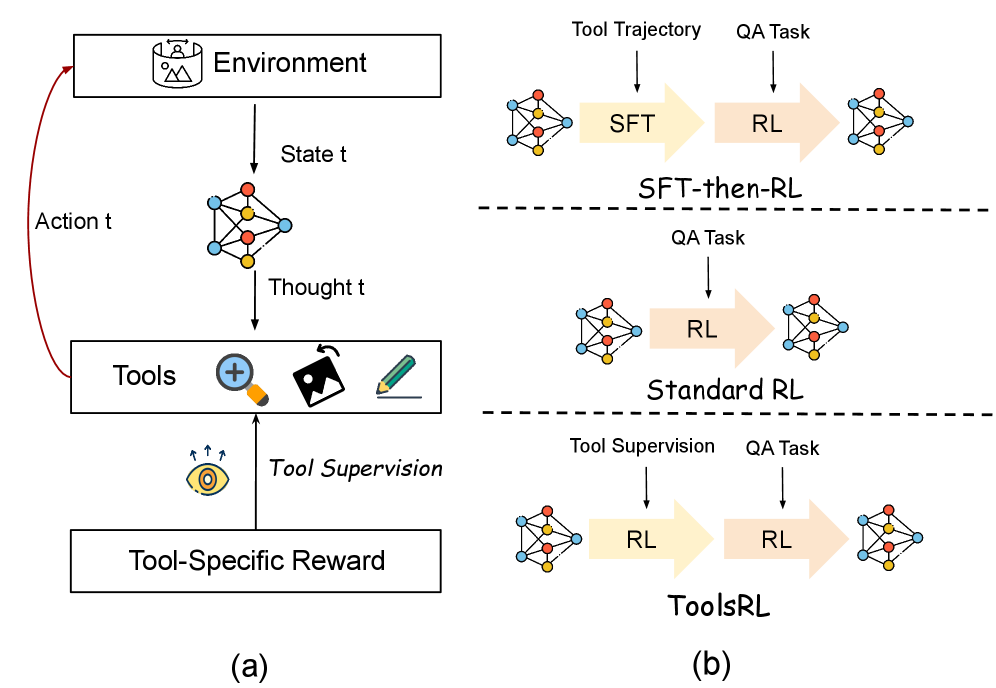
Figure 2 — ToolsRL 프레임워크 개요
4. Conclusion & Impact (결론 및 시사점)
본 연구는 도구 사용 능력 습득과 과제 해결이라는 이질적인 목표를 2단계 훈련 커리큘럼으로 분리함으로써 효율적이고 강력한 시각적 추론 모델 학습 방식을 제시하였습니다. 도구별 정밀한 보상 신호를 통한 학습은 전문가 궤적 구축 없이도 모델이 복잡한 시각적 문제를 해결하는 능력을 갖추게 합니다. 이러한 방법론은 단순한 시각적 도구 사용을 넘어 코드 생성이나 자율 에이전트 등 다양한 분야의 복합적 작업 수행 모델 구축에 있어 중요한 시사점을 제공합니다.

Figure 3 — ToolsRL 케이스 스터디
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] TRON: Targeted Rule-Verifiable Online Environments for Visual Reasoning RL
- [논문리뷰] Eliciting Complex Spatial Reasoning in MLLMs through Wide-Baseline Matching
- [논문리뷰] Edit-Compass & EditReward-Compass: A Unified Benchmark for Image Editing and Reward Modeling
- [논문리뷰] OpenVLThinkerV2: A Generalist Multimodal Reasoning Model for Multi-domain Visual Tasks
- [논문리뷰] Visual Para-Thinker++: A Single-Policy Multi-Agent Framework for Visual Reasoning
Review 의 다른글
- 이전글 [논문리뷰] Tadabur: A Large-Scale Quran Audio Dataset
- 현재글 : [논문리뷰] Visual Reasoning through Tool-supervised Reinforcement Learning
- 다음글 [논문리뷰] WavAlign: Enhancing Intelligence and Expressiveness in Spoken Dialogue Models via Adaptive Hybrid Post-Training
댓글