[논문리뷰] WavAlign: Enhancing Intelligence and Expressiveness in Spoken Dialogue Models via Adaptive Hybrid Post-Training
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yifu Chen, Shengpeng Ji, Qian Chen, Tianle Liang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- End-to-End Spoken Dialogue Model: 텍스트와 음성 처리를 별도의 모듈이 아닌 하나의 모델 내부에서 통합적으로 수행하여 상위 수준의 추론과 하위 수준의 음성 표현을 동시에 모델링하는 시스템.
- GRPO (Group Relative Policy Optimization): 여러 개의 rollout 샘플을 그룹화하여 그룹 내 상대적인 보상(advantage)을 기반으로 정책을 최적화하는 기법으로, 이 논문에서는 특히 텍스트 기반의 의미론적 개선을 위해 활용됨.
- Modality-aware Hybrid Post-Training: 음성과 텍스트의 특성에 따라 최적화 방식을 달리하는 방법론. 텍스트는
Preference Optimization으로 의미론적 정교화를 수행하고, 음성은SFT를 사용하여 안정적인 표현을 유지하도록 설계함. - Dynamic Gating Mechanism: 학습 과정에서 rollout의 신뢰도와 판별력(discriminability)을 실시간으로 평가하여
Preference Optimization업데이트 비율(λt)을 동적으로 조절하는 제어기.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 통합적인 End-to-End Spoken Dialogue Model의 의미론적 지능(Intelligence, IQ)과 음성 표현력(Expressiveness, EQ)을 동시에 향상시키는 문제를 해결하고자 한다. 기존의 통합적인 RL/PO(Preference Optimization) 접근 방식은 의미론적 품질 향상 시 음성 분포의 붕괴(Acoustic drift)를 초래하거나, 희소한 음성 보상 신호로 인해 신뢰할 수 없는 최적화가 진행되는 문제에 직면해 있다 [Figure 1]. 저자들은 의미론적 보상 신호가 음성에 비해 상대적으로 더 명확하고, 음성 토큰은 dense한 supervise가 필요하다는 점을 관찰하여, 모달리티 간의 서로 다른 최적화 전략이 필수적임을 제기한다.
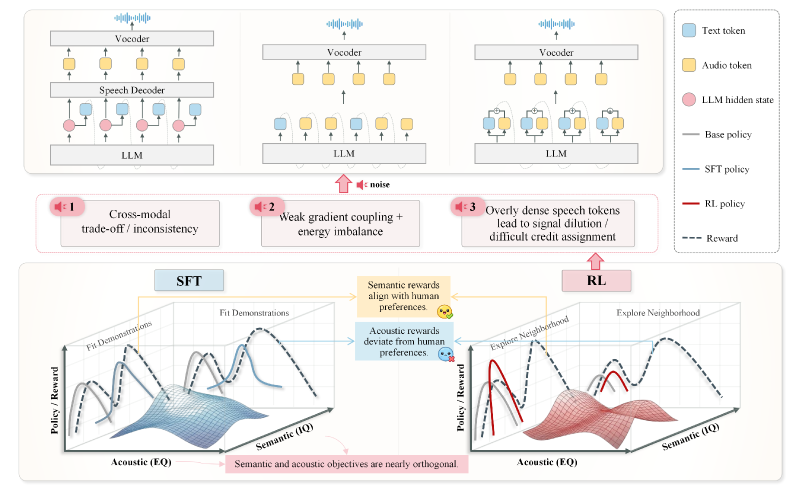
Figure 1 — 통합 RL의 한계와 동기
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 텍스트 토큰에만 Preference Optimization을 적용하고, 음성 토큰은 SFT를 통해 고정(anchor)함으로써 학습 안정성을 확보하는 Single-stage Adaptive Hybrid Post-Training을 제안한다 [Figure 6]. 핵심 기법인 Dynamic Gating Mechanism은 rollout의 보상 분산과 최상위 샘플의 질을 평가하여 λt를 조절하며, 이를 통해 신뢰도 높은 업데이트만 선택적으로 수행한다. 주요 실험 결과, 제안 방법론은 VITA 및 KimiAudio 아키텍처 모두에서 Full-Token PO baseline 대비 IQ와 EQ의 Pareto 효율성을 유의미하게 개선하였다. 구체적으로, VoiceBench 및 OpenAudioBench를 포함한 18개 서브태스크에서 SFT 및 기존 Unified RL 방식 대비 우수한 성능을 달성하였다 [Table 1]. 또한, 인간 주관 평가 결과에서 Helpfulness 및 Naturalness 차원 모두에서 높은 승률(Win-to-Loss ratio 약 4:1)을 기록하며 정성적인 우위도 입증하였다 [Table 4].
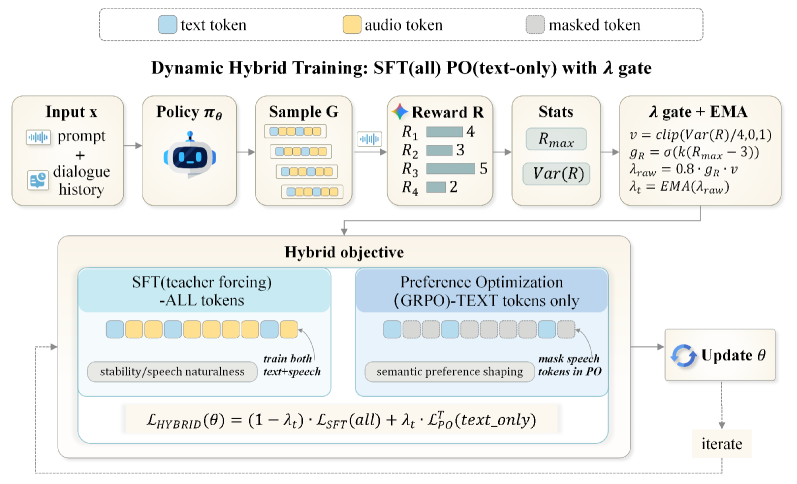
Figure 6 — 제안 모델의 전체 아키텍처
4. Conclusion & Impact (결론 및 시사점)
본 논문은 End-to-End 스피치 모델 학습 시 발생하는 cross-modal 최적화 불균형 문제를 이론적으로 규명하고, 이를 보정하는 동적 하이브리드 학습 프레임워크를 성공적으로 구축하였다. 이 연구는 단순히 지능과 표현력을 동시에 최적화하는 기술적 진전을 넘어, 모달리티 특성에 맞는 차별적 최적화가 스피치 기반 대화 모델의 성능 한계를 극복하는 핵심 동력임을 시사한다. 이는 향후 더 복잡한 멀티모달 생성 모델의 alignment 연구에 중요한 이론적 토대가 될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] RUBRIC-ARROW: Alternating Pointwise Rubric Reward Modeling for LLM Post-training in Non-verifiable Domains
- [논문리뷰] Watch Before You Answer: Learning from Visually Grounded Post-Training
- [논문리뷰] DARE: Diffusion Large Language Models Alignment and Reinforcement Executor
- [논문리뷰] SWE-Master: Unleashing the Potential of Software Engineering Agents via Post-Training
- [논문리뷰] Typhoon-S: Minimal Open Post-Training for Sovereign Large Language Models
Review 의 다른글
- 이전글 [논문리뷰] Visual Reasoning through Tool-supervised Reinforcement Learning
- 현재글 : [논문리뷰] WavAlign: Enhancing Intelligence and Expressiveness in Spoken Dialogue Models via Adaptive Hybrid Post-Training
- 다음글 [논문리뷰] Co-Evolving LLM Decision and Skill Bank Agents for Long-Horizon Tasks
댓글