[논문리뷰] RUBRIC-ARROW: Alternating Pointwise Rubric Reward Modeling for LLM Post-training in Non-verifiable Domains
링크: 논문 PDF로 바로 열기
저자: Haoxiang Jiang, Zihan Dong, Tianci Liu, Wanying Wang, Ran Xu, Tony Yu, Linjun Zhang, Haoyu Wang, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Rubric-ARROW: Rubric 기반의 evaluation을 수행하기 위해 rubric generator와 rubric-conditioned judge를 교차로 학습시키는 Alternating framework입니다.
- Pointwise Reward Modeling: 각 응답에 대해 독립적인 스칼라(scalar) 점수를 부여하여 효율적인 평가와 직접적인 policy optimization을 가능하게 하는 방식입니다.
- GRPO (Group Relative Policy Optimization): 환경과의 상호작용에서 생성된 여러 샘플 그룹 내에서 상대적인 보상을 사용하여 모델을 최적화하는 알고리즘입니다.
- Probability-based Scoring: Boolean 판정 대신 모델이 출력하는 "true" 및 "false" 토큰의 확률 마진(probability margin)을 사용하여 fine-grained한 점수를 산출하는 기법입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 비검증(non-verifiable) 도메인에서의 LLM 평가가 가진 주관성과 기존 rubric 기반 평가의 모델 의존성 문제를 해결하고자 합니다. 기존 방식은 frontier LLM에 과도하게 의존하거나, rubric criteria에 대한 Boolean aggregation 수행 시 점수가 경직되어 응답 간의 변별력을 상실하는 문제가 있습니다. [Table 1]에서 볼 수 있듯이, 기존 rubric-based 모델은 특정 벤치마크에서 한계가 명확하며, frontier LLM 기반 파이프라인은 높은 비용과 배포의 어려움을 겪습니다. 따라서 본 논문은 external 모델에 대한 의존성을 제거하고, 오직 pairwise preference 데이터만으로 학습 가능한 standalone pointwise 평가 프레임워크를 목표로 합니다.
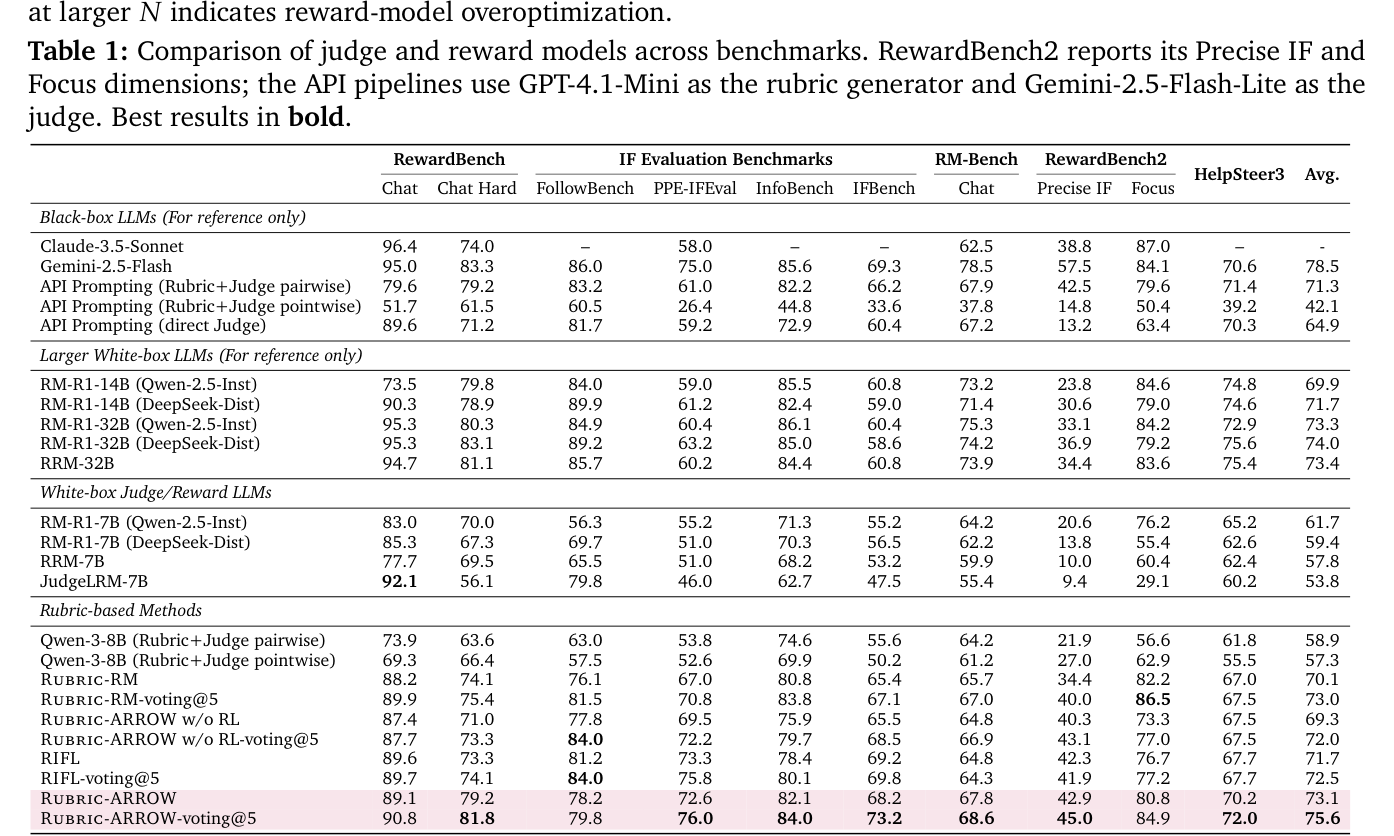
Table 1 — 다양한 벤치마크에서의 정량적 성능 비교 데이터
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 프레임워크는 rubric generator와 rubric-conditioned judge를 alternating 방식으로 jointly하게 학습시키는 단계적 RL 파이프라인을 제안합니다. [Figure 1]에서 확인되는 바와 같이, rubric generator는 conciseness와 uniqueness를 유지하는 평가 기준을 생성하며, judge는 probability-based scoring을 통해 세분화된 보상 신호를 제공합니다. RL 학습 과정에서는 phase-specific preference rewards를 통해 human preference ordering을 점진적으로 복구합니다. 실험 결과, Rubric-ARROW는 Rubric-RM 대비 평균 3.0% 이상의 성능 향상을 보였으며, 특히 WildBench와 같은 복합적인 instruction-following 벤치마크에서 정교한 oracle 평가 지표를 효과적으로 추종하였습니다. 또한, [Table 8]의 연산 효율성 분석 결과, 추론 비용 측면에서 reasoning-based 모델들보다 한 자릿수 이상 빠른 속도를 기록하여 실무적 deployability를 입증했습니다.
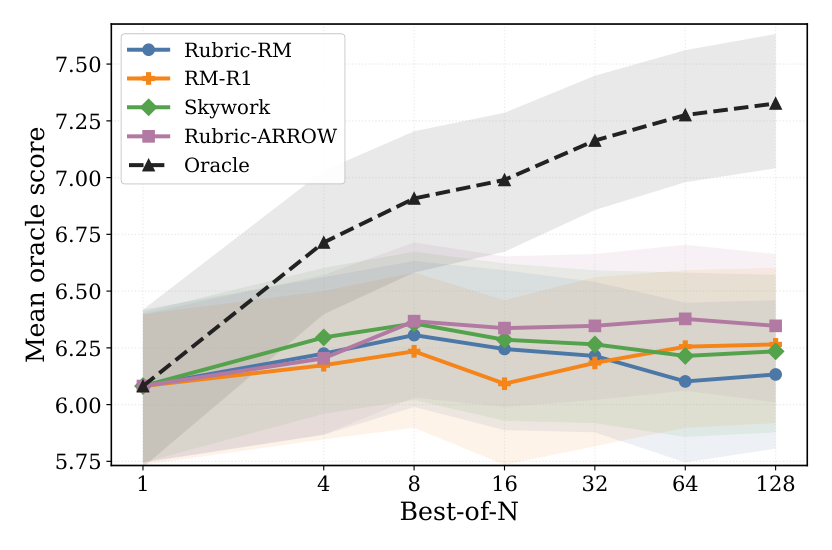
Figure 1 — 제안 모델과 기존 baseline들 간의 best-of-N 성능 비교 그래프
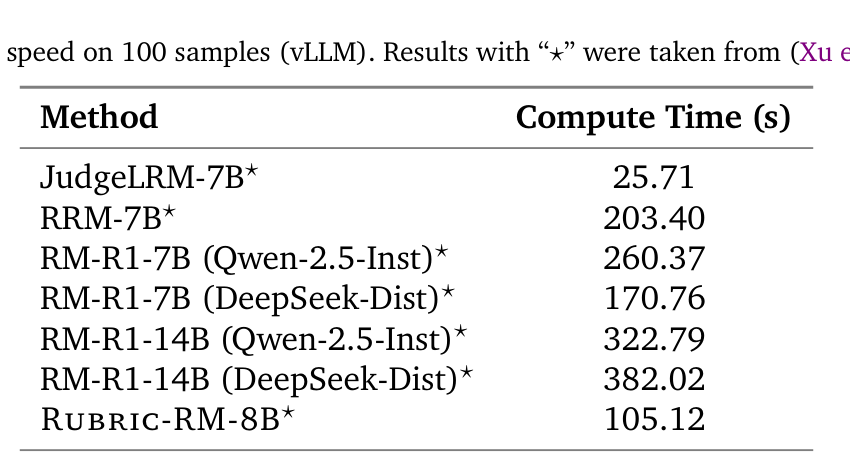
Table 8 — 추론 효율성 측면의 성능 분석 테이블
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 pairwise preference 데이터만으로 고성능 pointwise rubric reward model을 구축할 수 있는 효과적인 Alternating RL 프레임워크를 제시하였습니다. 이 연구는 평가의 정확도(accuracy)와 해석 가능성(interpretability)을 동시에 달성하면서도 frontier LLM에 대한 의존성을 획기적으로 낮추었습니다. 향후 오픈소스 LLM alignment 분야에서 rubric 기반의 신뢰할 수 있는 reward model을 구축하려는 연구자들에게 중요한 표준적인 방법론을 제공할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Reinforcement Learning with Metacognitive Feedback Elicits Faithful Uncertainty Expression in LLMs
- [논문리뷰] Skill-RM: Unifying Heterogeneous Evaluation Criteria via Agent Skill
- [논문리뷰] Stitched Value Model for Diffusion Alignment
- [논문리뷰] RewardHarness: Self-Evolving Agentic Post-Training
- [논문리뷰] Edit-Compass & EditReward-Compass: A Unified Benchmark for Image Editing and Reward Modeling
Review 의 다른글
- 이전글 [논문리뷰] Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
- 현재글 : [논문리뷰] RUBRIC-ARROW: Alternating Pointwise Rubric Reward Modeling for LLM Post-training in Non-verifiable Domains
- 다음글 [논문리뷰] Skill0.5: Joint Skill Internalization and Utilization for Out-of-Distribution Generalization in Agentic Reinforcement Learning
댓글