[논문리뷰] Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
링크: 논문 PDF로 바로 열기
저자: Qiuyue Wang, Mingsheng Li, Jian Guan, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Qwen-VLA: Qwen3.5-4B 비전-언어 백본에 DiT(Diffusion Transformer) 기반 flow-matching action decoder를 결합한 통합 embodied foundation model입니다.
- Embodiment-aware Prompt Conditioning: 로봇 플랫폼, arm configuration, control frequency, prediction horizon 등의 정보를 textual prompt로 전처리하여 하나의 모델이 다양한 로봇 구현체(embodiment)를 제어하게 하는 방식입니다.
- T2A (Text-to-action DiT pretraining): 시각 정보 없이 언어 명령과 embodiment prompt만을 사용하여 action decoder가 구조화된 action prior를 학습하도록 유도하는 사전 학습 단계입니다.
- Flow-matching: 고차원 연속 action 데이터를 생성하기 위해 ODE(Ordinary Differential Equation) 기반의 확률론적 경로를 학습하는 생성 모델링 프레임워크입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 embodied AI 모델들이 특정 작업이나 로봇 플랫폼에만 고도화되어 있어 발생하는 파편화(fragmentation) 문제를 해결하기 위해 통합 모델을 제안합니다. 현재의 방식은 데이터 활용도가 낮고 일반화 성능이 제한적이라는 한계가 있습니다. 이를 극복하고자 저자들은 다양한 로봇의 manipulation, navigation, egocentric demonstration 데이터를 통합적으로 학습할 수 있는 단일 Vision-Language-Action 프레임워크를 설계하였습니다. [Figure 1]에서 볼 수 있듯이, 본 모델은 다양한 작업과 환경을 포괄하는 범용 정책으로서의 가능성을 탐구합니다.
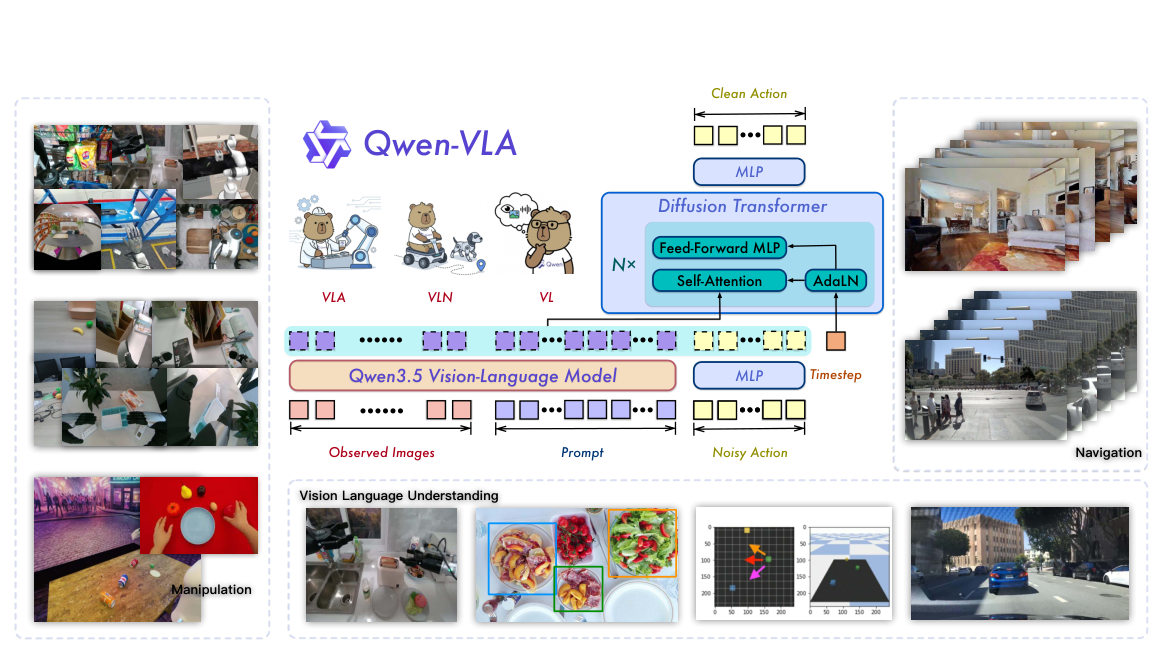
Figure 1 — 통합 아키텍처 및 입력-출력 흐름을 보여주는 핵심 다이어그램
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 Qwen3.5 백본과 DiT 기반 action decoder를 결합하고, 단계별 학습 전략(T2A -> CPT -> SFT -> RL)을 통해 시각적 이해와 제어 능력을 동시에 최적화하였습니다. 특히 Embodiment-aware Prompt Conditioning을 도입하여 서로 다른 로봇 제어 규칙을 단일 네트워크에서 수용하도록 했습니다. 핵심적인 실험 결과로, Qwen-VLA-Instruct는 LIBERO 벤치마크에서 97.9%, Simpler-WidowX에서 73.7%, RoboTwin-Easy/Hard에서 각각 86.1%/87.2%의 높은 성공률을 달성했습니다. 또한, 동적 조작(dynamic manipulation) 평가인 DOMINO 벤치마크에서는 별도의 미세 조정 없이 제로샷(zero-shot) 환경에서 26.6% SR(Success Rate) 및 39.5 MS(Manipulation Score)를 기록하며 기존 전문 모델들을 상회하는 성능을 보여주었습니다. [Table 4]에서 이러한 성능적 우위를 확인할 수 있습니다.
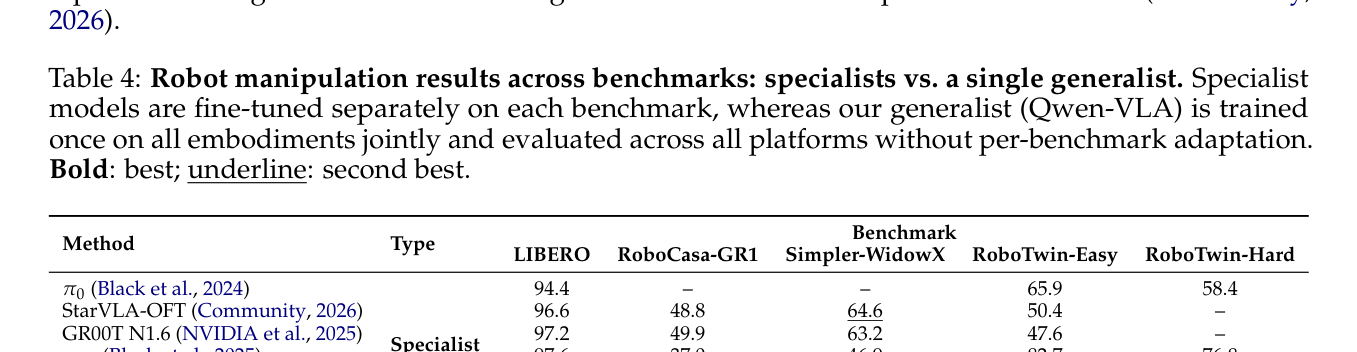
Table 4 — 다양한 벤치마크에서 일반 모델(Qwen-VLA)과 전문 모델(Specialist)의 성능을 비교한 핵심 결과 테이블
4. Conclusion & Impact (결론 및 시사점)
본 논문은 다양한 Embodied AI 작업을 단일 모델로 통합하는 것이 가능하며, 대규모 다중 도메인 데이터 학습이 전이 학습 및 일반화 성능 향상에 결정적인 기여를 함을 입증했습니다. 제안된 Qwen-VLA 아키텍처는 고수준의 언어 추론과 저수준의 물리적 제어를 효과적으로 연결하여 embodied intelligence의 실용적 진전을 이끌었습니다. 이 연구는 향후 로봇의 자율적 동작 생성과 일반 목적 로봇(General-purpose Robot) 개발을 위한 핵심적인 연구 방향성을 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] SOP: A Scalable Online Post-Training System for Vision-Language-Action Models
- [논문리뷰] An Anatomy of Vision-Language-Action Models: From Modules to Milestones and Challenges
- [논문리뷰] Scaling Mixture-of-Experts Video Pretraining for Embodied Intelligence
- [논문리뷰] Object-Centric Residual RL for Zero-Shot Sim-to-Real VLA Enhancement
- [논문리뷰] PhysBrain 1.0 Technical Report
Review 의 다른글
- 이전글 [논문리뷰] PhyGenHOI: Physically-Aware 4D Generation of Dynamic Human-Object Interactions
- 현재글 : [논문리뷰] Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
- 다음글 [논문리뷰] RUBRIC-ARROW: Alternating Pointwise Rubric Reward Modeling for LLM Post-training in Non-verifiable Domains
댓글