[논문리뷰] PhysBrain 1.0 Technical Report
링크: 논문 PDF로 바로 열기
메타데이터
저자: Shijie Lian, Bin Yu, Xiaopeng Lin, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- PhysBrain 1.0: 대규모 인간 egocentric 비디오를 구조화된 물리적 커먼센스 데이터로 변환하여 VLM(Vision-Language Model)의 물리적 이해를 강화하고 이를 로봇 제어(VLA)로 전이하는 시스템입니다.
- VLA (Vision-Language-Action): 시각적 정보와 언어적 지시를 결합하여 로봇의 제어 명령(Action)을 생성하는 모델링 프레임워크입니다.
- Structured Scene Meta-Information: 비디오 클립 내의 객체 요소, 공간적 역학, 행동 실행 과정을 JSON 스키마로 추출하여 물리적 추론의 기초를 형성하는 중간 데이터 포맷입니다.
- Depth-Aware Spatial Augmentation: Depth Anything v3를 활용하여 영상에 3D 공간 정보 및 거리 지표를 부가함으로써 모델의 정밀한 물리적 공간 인지 능력을 향상시키는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 VLA 시스템이 의존하는 플랫폼 종속적인 로봇 궤적(Trajectory) 데이터 수집의 한계를 극복하고, 물리적 환경에 대한 근본적인 이해(Physical Commonsense)를 확보하는 것을 목표로 합니다. 현재의 로봇 데이터 위주 학습은 범용성을 확보하기 어렵고, 시점 변화나 장면 구성의 변화에 대응하는 로봇 정책의 강건성이 부족하다는 문제점이 있습니다. 저자들은 인간의 일상적 상호작용을 담은 대규모 egocentric 비디오가 이러한 물리적 규칙을 학습하는 데 더 효과적인 원천임을 강조합니다. 이를 위해 Raw 비디오를 물리적으로 명시적인(Physically Explicit) 데이터로 변환하는 새로운 데이터 엔진을 도입합니다 [Figure 1].
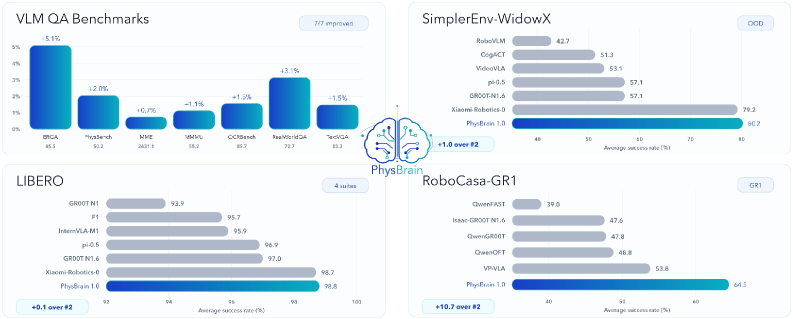
Figure 1 — PhysBrain 1.0 전체 시스템 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 egocentric 비디오를 구조화된 메타데이터로 파싱한 후, 이를 물리적으로 근거 있는(Physically Grounded) QA 데이터로 렌더링하는 3단계 데이터 엔진을 제안합니다. 제안된 아키텍처는 PhysBrain 1.0 시스템 내에서 비디오의 핵심 요소를 Scene elements, Spatial dynamics, Action execution의 세 필드로 명확히 구분하여 추출합니다 [Figure 2]. 또한, Depth-Aware Spatial Augmentation을 통해 학습된 물리적 priors를 기반으로, 소량의 로봇 데이터를 활용한 VLA 적응(Adaptation) 단계에서 기존의 일반적인 시각-언어적 성능을 보존하며 로봇 제어 능력을 성공적으로 이식합니다.
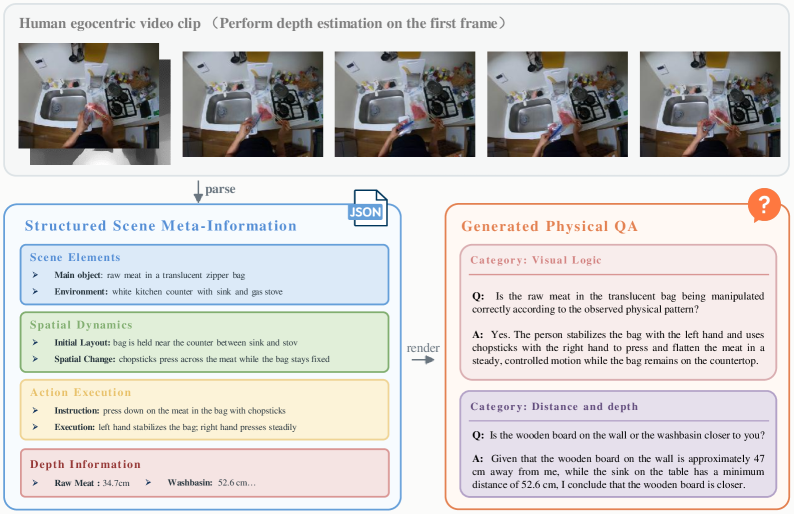
Figure 2 — 구조화된 메타데이터 및 QA 생성 예시
주요 실험 결과로서, PhysBrain 1.0은 다양한 multimodal QA 벤치마크(ERQA, PhysBench 등)와 embodied control 벤치마크(SimplerEnv, LIBERO, RoboCasa)에서 SOTA 성능을 달성하였습니다. 특히 로봇 조작 작업에서, 기존 베이스라인인 π0.5 대비 단일 객체 파지 성공률을 47.1%에서 63.3%로, 장기 행동(Long-horizon) 성공률을 31.0%에서 45.0%로 대폭 개선하며 그 우수성을 입증하였습니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 로봇 데이터의 양적 팽창보다 인간의 일상적 물리적 상호작용을 활용한 commonsense 습득이 embodied intelligence의 핵심임을 효과적으로 보여줍니다. 제안된 데이터 엔진은 인간의 행동을 구조화된 언어적·공간적 지도(Supervision)로 변환함으로써 VLM과 VLA 사이의 강력한 가교 역할을 합니다. 본 연구는 향후 로봇 데이터 수집 비용을 절감하는 동시에, 환경 변화에 더욱 강건한 범용 로봇 정책을 개발하는 데 중요한 학술적·산업적 토대를 마련한 것으로 평가됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
- [논문리뷰] Chain of World: World Model Thinking in Latent Motion
- [논문리뷰] An Anatomy of Vision-Language-Action Models: From Modules to Milestones and Challenges
- [논문리뷰] Scaling Mixture-of-Experts Video Pretraining for Embodied Intelligence
- [논문리뷰] RoboDojo: A Unified Sim-and-Real Benchmark for Comprehensive Evaluation of Generalist Robot Manipulation Policies
Review 의 다른글
- 이전글 [논문리뷰] PAGER: Bridging the Semantic-Execution Gap in Point-Precise Geometric GUI Control
- 현재글 : [논문리뷰] PhysBrain 1.0 Technical Report
- 다음글 [논문리뷰] ReactiveGWM: Steering NPC in Reactive Game World Models
댓글