[논문리뷰] Overcoming Dynamics-Blindness: Training-Free Pace-and-Path Correction for VLA Models
링크: 논문 PDF로 바로 열기
저자: Yanyan Zhang, Chaoda Song, Vikash Singh, Xinpeng Li, Kai Ye, Zhe Hu, Zhongzhu Pu, Yu Yin, Vipin Chaudhary
1. Key Terms & Definitions (핵심 용어 및 정의)
- VLA (Vision-Language-Action) Models: 시각적 관측값과 언어 지시사항을 입력받아 로봇의 제어 명령(Action)을 생성하는 모델.
- Action Chunking: 모델이 한 번의 추론으로 고정된 길이의 미래 동작 시퀀스를 생성하고, 이를 루프 없이 순차적으로 실행하는 방식.
- Dynamics-Blindness: 동작 실행 중에 환경의 변화(움직이는 물체 등)가 발생해도, 최초 시점의 정적 관측값으로만 생성된 동작이 이를 반영하지 못하는 현상.
- PPC (Pace-and-Path Correction): 환경의 동역학 정보를 활용하여 동작 시퀀스를 실시간으로 수정하는 훈련 없는(training-free) 추론 가속 및 보정 프레임워크.
- MoveBench: 로봇의 모션 대응 능력을 평가하기 위해 물체의 이동 패턴(속도, 가속도, 불규칙성 등)을 주 평가 축으로 설계한 로봇 제어 벤치마크.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 VLA 모델들이 Action Chunking 방식을 채택함에 따라 발생하는 Dynamics-Blindness 문제를 해결하는 데 집중한다 [Figure 1]. 대부분의 VLA 모델은 고정된 단일 정적 프레임을 기반으로 미래 동작을 예측하기 때문에, 실행 과정에서 발생하는 환경 변화에 대응할 수 없다. 기존의 연구들은 재훈련(retraining)이 필요하거나, 추론 대기 시간(Latency) 문제, 또는 동작 간의 일관성 붕괴라는 한계에 직면해 있다. 이러한 구조적 결함은 특히 동적인 환경에서 모델의 성공률을 급격히 저하시키며, 기존 벤치마크들은 이러한 문제를 독립적으로 평가하기 어렵다는 한계가 있다.

Figure 1 — Dynamics-Blindness 문제 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 환경의 동역학 정보(Velocity 등)를 활용하여 동작 시퀀스를 실시간 보정하는 PPC를 제안한다 [Figure 2]. 저자들은 웨이포인트(Waypoint) 추적 오차와 동작 보정 비용을 최소화하는 단일 이차 비용 함수(Quadratic Cost)를 설계하였으며, 이 최적화 문제는 Pace(시간 압축) 채널과 Path(공간 오프셋) 채널로 직교 분해(Orthogonal Decomposition)되어 닫힌 형식(Closed-form)으로 풀린다. Pace 채널은 시간 흐름을 압축하여 동적 거동을 흡수하고, Path 채널은 피보나치(Fibonacci) 프로파일을 통해 공간적 오프셋을 적용한다. 또한, Hierarchical 2-EMA Latch Stabilizer를 도입하여 예측 불가능한 불안정 환경에서 동작 실행 길이를 적응적으로 조절한다. 실험 결과, PPC는 모든 foundational VLA 모델의 성능을 향상시켰으며, 동적 환경 전용 환경에서 기존 대비 성공률을 최대 28.8%, 정적-동적 혼합 환경에서 25.9%까지 절대적 개선을 달성하였다 [Table 1]. 특히, PPC는 가속 운동 환경에서 가장 큰 성능 향상(+32.8%)을 보였다 [Figure 4].
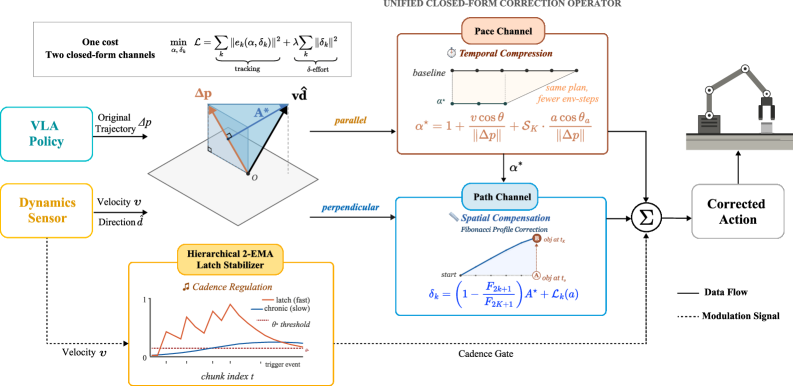
Figure 2 — PPC 프레임워크 개요
4. Conclusion & Impact (결론 및 시사점)
본 논문은 VLA 모델의 구조를 수정하거나 재훈련할 필요 없이, 동적 환경에서의 제어 정밀도를 획기적으로 높일 수 있는 강력한 inference-time wrapper인 PPC를 제시하였다. 이는 물체의 움직임에 대응해야 하는 실시간 로봇 제어 분야에서 필수적인 동역학 인식 문제를 물리적으로 근거 있는 수식으로 해결했다는 점에서 학계와 산업계에 큰 의의를 갖는다. 본 연구의 결과는 로봇이 제조 현장이나 가정 내 이동 물체와 같은 복잡한 동적 환경에서 더욱 안전하고 능동적으로 상호작용할 수 있는 기반 기술로 활용될 수 있을 것으로 기대된다.
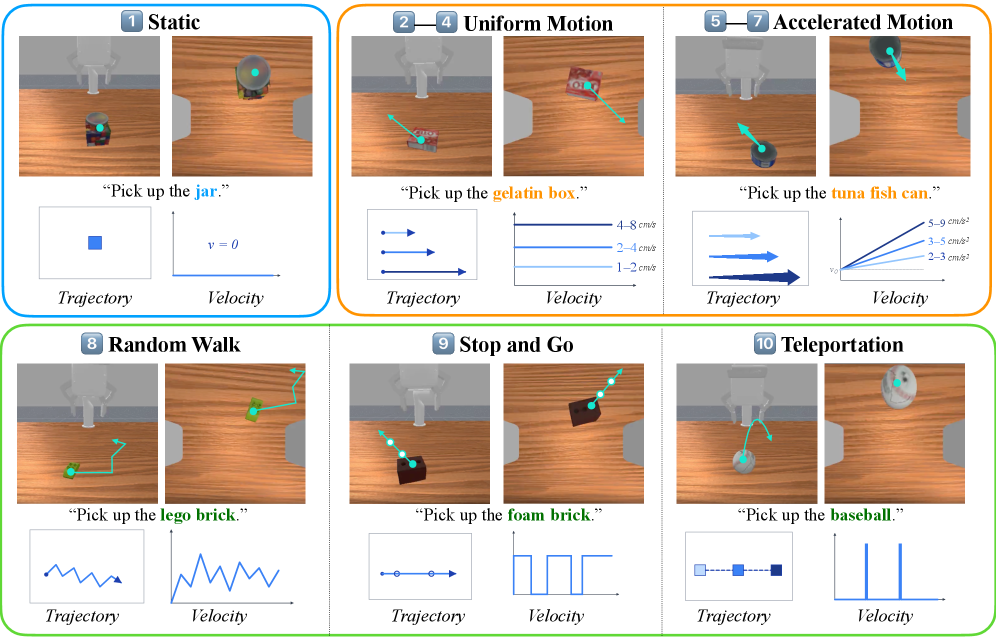
Figure 3 — MoveBench 벤치마크 구성
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Mixture of Horizons in Action Chunking
- [논문리뷰] Dual Latent Memory in Vision-Language-Action Models for Robotic Manipulation
- [논문리뷰] Learning to Move Before Learning to Do: Task-Agnostic pretraining for VLAs
- [논문리뷰] EventVLA: Event-Driven Visual Evidence Memory for Long-Horizon Vision-Language-Action Policies
- [논문리뷰] Cortex 2.0: Grounding World Models in Real-World Industrial Deployment
Review 의 다른글
- 이전글 [논문리뷰] Orchard: An Open-Source Agentic Modeling Framework
- 현재글 : [논문리뷰] Overcoming Dynamics-Blindness: Training-Free Pace-and-Path Correction for VLA Models
- 다음글 [논문리뷰] PREPING: Building Agent Memory without Tasks
댓글