[논문리뷰] MMaDA-VLA: Large Diffusion Vision-Language-Action Model with Unified Multi-Modal Instruction and Generation
링크: 논문 PDF로 바로 열기
저자: Yang Liu, Pengxiang Ding, Tengyue Jiang, Xudong Wang, Minghui Lin, Wenxuan Song, Hongyin Zhang, Zifeng Zhuang, Han Zhao, Wei Zhao, Siteng Huang, Jinkui Shi, Donglin Wang
1. Key Terms & Definitions (핵심 용어 및 정의)
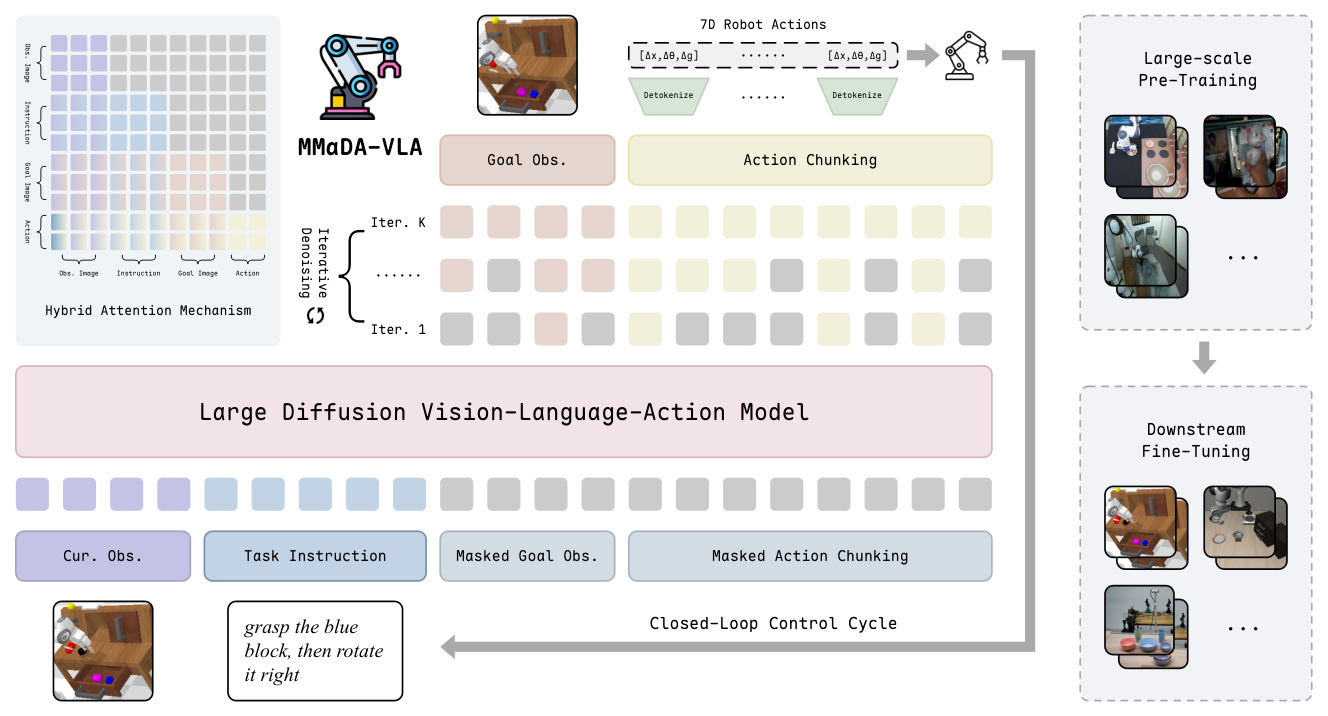
- MMaDA-VLA : 언어, 이미지, 연속적인 로봇 제어 명령을 하나의 discrete token space로 통합하여 처리하는 fully native pre-trained large diffusion VLA 모델입니다.
- Discrete Diffusion : 연속적인 로봇 제어 값을 bin 단위로 이산화(discretize)하고, masked token denoising을 통해 action을 생성하는 방식으로, 기존 autoregressive 모델의 단점인 누적 오류를 줄이는 기법입니다.
- Action Chunking : 모델이 단일 전향 패스(single forward pass)에서 다중 스텝의 action 시퀀스를 병렬로 예측하여 장기적인 시간 일관성(long-horizon consistency)을 강화하는 방식입니다.
- Hybrid Attention : intra-modal(같은 모달리티 내)에는 bidirectional full attention을, inter-modal(모달리티 간)에는 causal attention을 적용하여 정보 흐름을 제어하고 생성 품질을 높이는 메커니즘입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존 VLA 모델들은 hierarchical 구조나 autoregressive 패러다임에 의존함으로써 발생하는 아키텍처 오버헤드, 장기적 시간 일관성 결여, 그리고 환경 역학(environment dynamics)을 파악하는 명시적 메커니즘 부족이라는 한계에 직면해 있습니다.
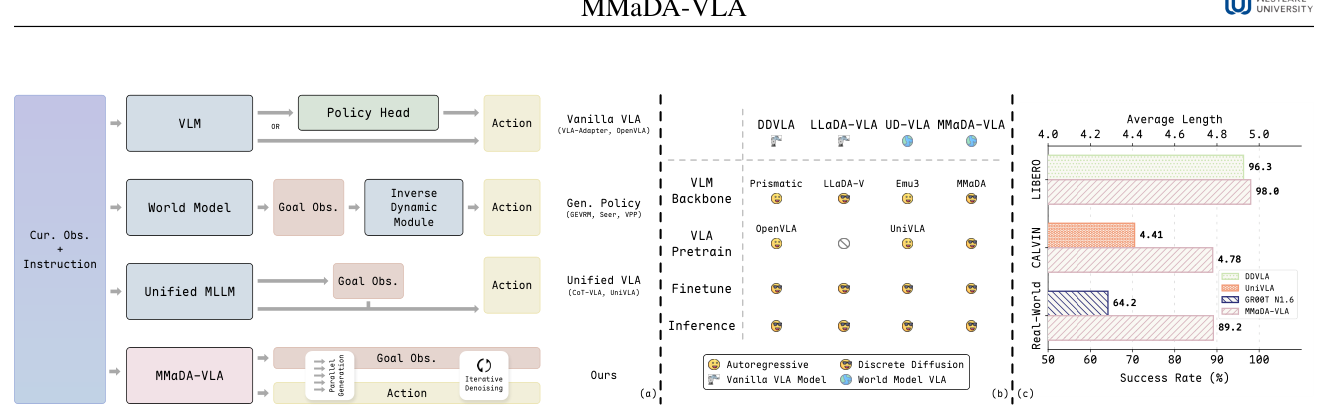
에서 볼 수 있듯이, 이러한 기존 모델들은 multi-stage 구조로 인해 정보 전달의 불일치가 발생하고 오류가 축적되는 경향이 있습니다. 특히 복잡한 로봇 조작 과업에서 autoregressive 방식은 action 차원 간의 고유한 순서가 없음에도 불구하고 강제로 순서를 부여하여 성능 저하를 야기합니다. 따라서, 본 논문은 이러한 환경적 역학을 모델링하고 정확한 조작을 수행하기 위해 별도의 auxiliary module 없이도 미래의 시각적 결과를 함께 예측할 수 있는 새로운 통합 프레임워크의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 언어, 시각, 그리고 제어 데이터를 하나의 discrete token 공간에서 처리하는 MMaDA-VLA 를 제안하며, 이는 masked token denoising objective를 통해 미래의 goal observation과 action 시퀀스를 동시에 병렬로 생성합니다. Hybrid Attention Mechanism 을 도입하여 모델 내부의 정보 흐름을 효과적으로 관리하고, iterative denoising 과정을 통해 매 단계에서 예측된 action을 시각적 기대치와 일치시킴으로써 정교한 제어가 가능하도록 설계하였습니다. 주요 실험 결과, MMaDA-VLA 는 LIBERO 벤치마크에서 98.0% 의 평균 성공률을 달성하여 기존 SOTA 모델들을 상회하는 성능을 입증하였습니다.
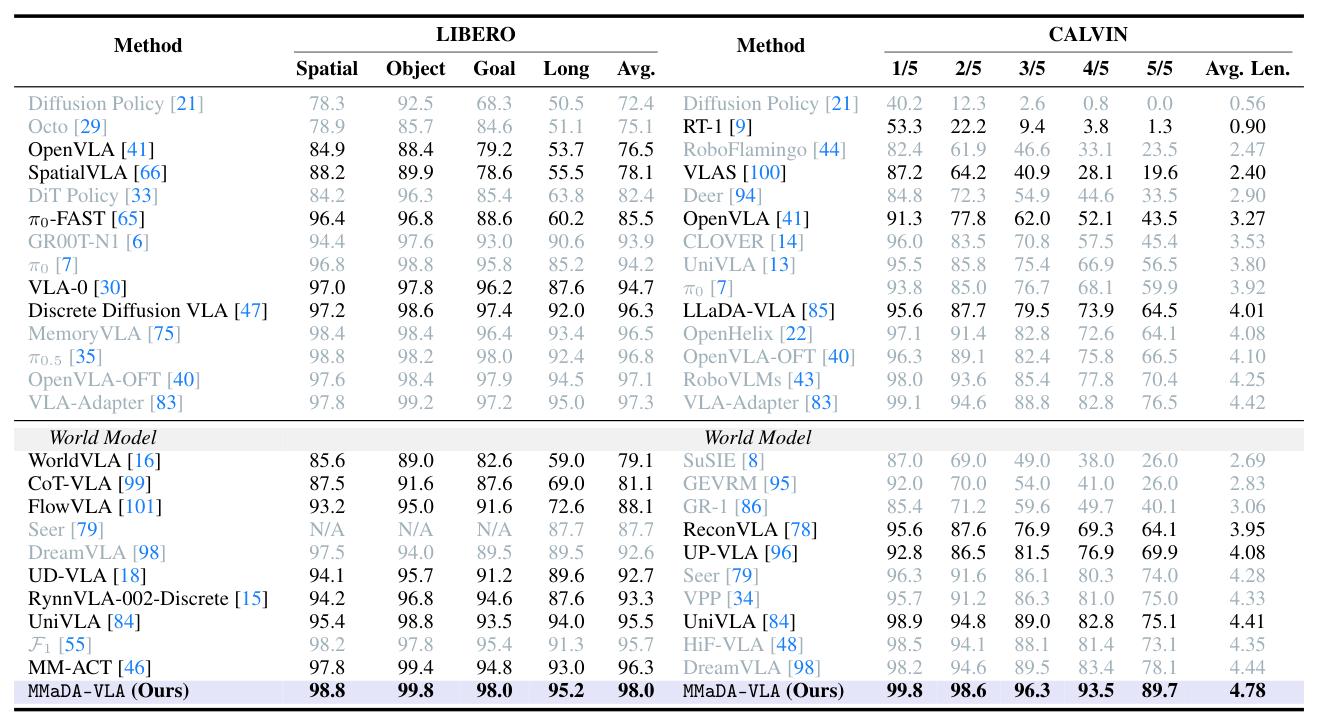
에 따르면, CALVIN 벤치마크에서도 ABC→D 설정 하에 4.78 의 평균 작업 길이(Average Length)를 기록하며 압도적인 long-horizon 과업 수행 능력을 보여주었습니다. 특히, pre-training 없이 수행한 ablation 연구에서도 제안된 병렬 denoising과 hybrid attention이 각각 성능 향상에 크게 기여함을 확인했습니다.
4. Conclusion & Impact (결론 및 시사점)
MMaDA-VLA 는 로봇 조작을 위한 vision-language-action 모델을 대규모 discrete diffusion 프레임워크로 재정의하여 성공적으로 통합한 연구입니다. 본 연구는 명시적인 외부 world model 모듈 없이도 시각적 미래 예측과 제어 작업을 병렬로 최적화할 수 있음을 증명했습니다. 이러한 접근 방식은 로봇 제어의 복잡한 추론과 정밀한 조작을 동시에 달성할 수 있는 새로운 가능성을 제시하며, 향후 embodied AI 및 generalist robot policy 발전에 중요한 학술적 토대를 마련할 것으로 평가됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] From Foundation to Application: Improving VLA Models in Practice
- [논문리뷰] WEAVER, Better, Faster, Longer: An Effective World Model for Robotic Manipulation
- [논문리뷰] Discrete-WAM: Unified Discrete Vision-Action Token Editing for World-Policy Learning
- [논문리뷰] Overcoming Dynamics-Blindness: Training-Free Pace-and-Path Correction for VLA Models
- [논문리뷰] Learning Native Continuation for Action Chunking Flow Policies
Review 의 다른글
- 이전글 [논문리뷰] HippoCamp: Benchmarking Contextual Agents on Personal Computers
- 현재글 : [논문리뷰] MMaDA-VLA: Large Diffusion Vision-Language-Action Model with Unified Multi-Modal Instruction and Generation
- 다음글 [논문리뷰] MemRerank: Preference Memory for Personalized Product Reranking
댓글