[논문리뷰] StableVLA: Towards Robust Vision-Language-Action Models without Extra Data
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yiyang Fu, Chubin Zhang, Shukai Gong, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- VLA (Vision-Language-Action) Models: 시각적 입력과 텍스트 지시사항을 LLM 기반으로 처리하여 로봇의 행동(Action)을 제어하는 모델입니다.
- IB-Adapter (Information Bottleneck Adapter): Information Bottleneck 이론을 기반으로, 시각적 인코더와 LLM 사이에서 불필요한 노이즈를 필터링하고 핵심적인 의미 정보를 추출하도록 설계된 모듈입니다.
- Fused IB-Adapter: 표준 MLP 기반의 고주파 공간 정보 보존 경로와 IB-Adapter의 노이즈 억제 경로를 병합한 하이브리드 아키텍처입니다.
- Subspace Covariance Modeling: 다중 헤드 디자인을 통해 채널 간 상관관계를 Gram Matrix로 모델링하여, 특정 채널의 노이즈를 독립적으로 억제하는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 VLA 모델들이 훈련 데이터에 포함되지 않은 실세계의 다양한 시각적 노이즈(센서 노이즈, 모션 블러 등)에 매우 취약하다는 점을 지적합니다. 현재의 VLA 모델은 주로 깨끗한 환경에서만 평가되며, 실제 배포 시 시각적 왜곡이 발생하면 성능이 급격히 저하되는 'robustness gap'을 보입니다. 기존의 해결책인 대규모 데이터 증강(Data Augmentation)은 계산 비용이 높고 특정 노이즈 패턴을 암기하는 경향이 있어 일반화 성능이 낮습니다. 저자들은 이 취약점의 핵심 원인이 시각 인코더와 LLM을 연결하는 Projector(Adapter) 모듈이 노이즈를 걸러내지 못하고 그대로 통과시키는 데 있음을 밝혀냅니다 [Figure 3].
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 정보 이론의 Information Bottleneck 원리를 시각 정보 정렬에 적용한 IB-Adapter를 제안합니다. 이 모듈은 입력된 시각적 토큰의 채널 간 의존성을 계산하여, 작업과 무관한 노이즈 채널을 Sigmoid 기반의 Gating으로 억제합니다 [Figure 4]. 또한, 정밀한 조작을 위해 고주파 공간 정보를 유지하는 MLP 경로와 의미론적 강건성을 확보하는 IB 경로를 결합한 Fused IB-Adapter를 통해 성능을 최적화합니다. 실험 결과, StableVLA는 추가 데이터 없이 아키텍처 변경만으로 VLA-Adapter 대비 합성 노이즈 환경에서 평균 35.2%의 성능 향상을 기록했습니다 [Table 1]. 실세계 로봇 평가에서도 OpenPi와 같은 거대 파라미터 모델을 능가하는 강건성을 보이며, 특히 물리적 방해 요소(Oil, Shelter) 하에서도 압도적인 성능 유지율을 달성했습니다 [Table 2]. 시각화 실험에서는 제안 모델이 노이즈 속에서도 객체 중심의 의미적 클러스터링을 명확히 유지함을 보여줍니다 [Figure 5].
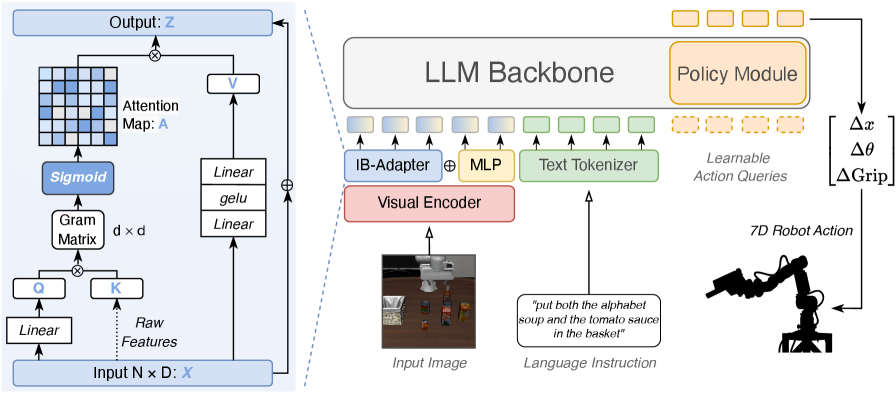
Figure 4 — IB-Adapter 아키텍처
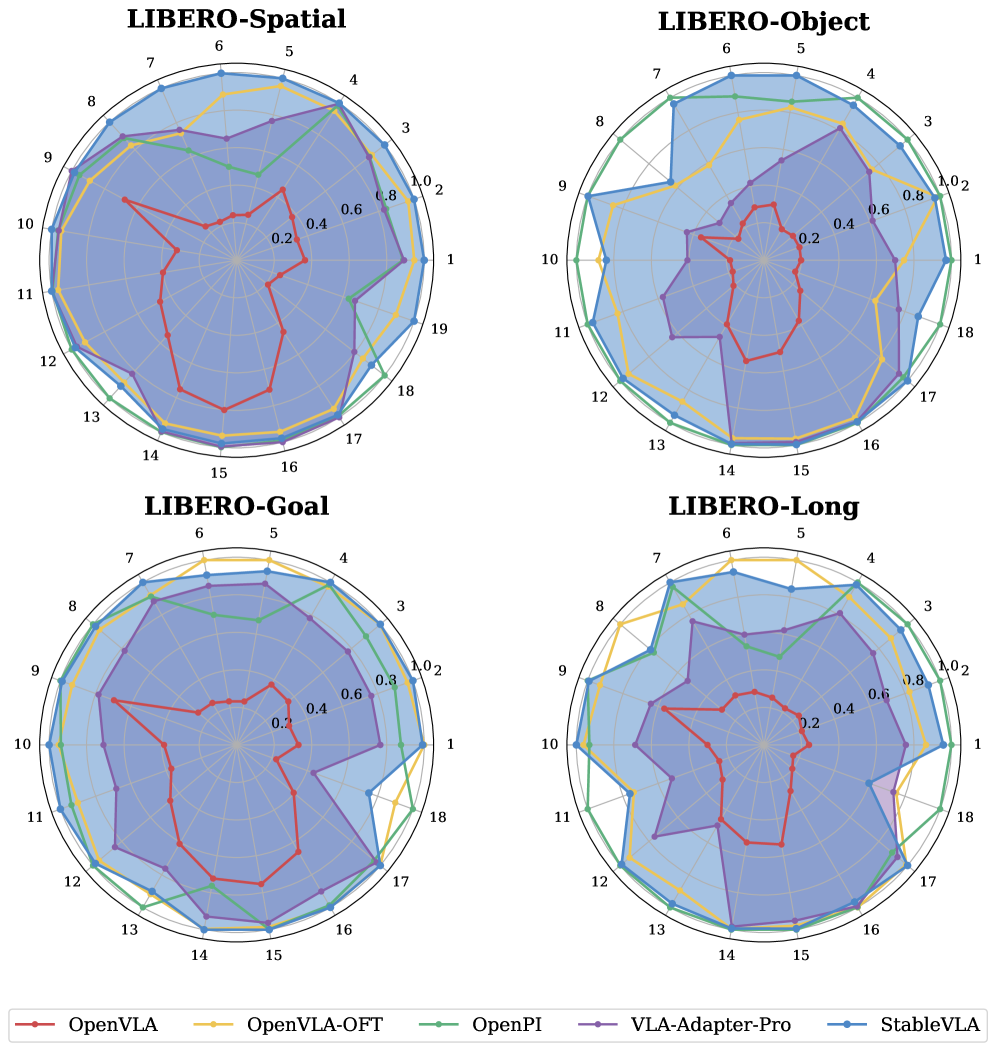
Figure 5 — 강건성 비교 및 시각화
4. Conclusion & Impact (결론 및 시사점)
본 연구는 아키텍처 설계를 통해 VLA 모델의 고질적인 문제인 시각적 노이즈에 대한 취약성을 근본적으로 해결했습니다. IB-Adapter는 데이터 의존성을 줄이면서도 파라미터 오버헤드가 매우 적어(10M 미만), 향후 효율적인 embodied AI 개발의 새로운 패러다임을 제시합니다. 이 연구는 대규모 모델 확장이 어려운 상황에서도 아키텍처의 inductive bias 개선만으로 모델의 강건성을 확보할 수 있음을 입증하여, 학계와 산업계 전반에 중요한 기술적 이정표가 될 것으로 기대됩니다.
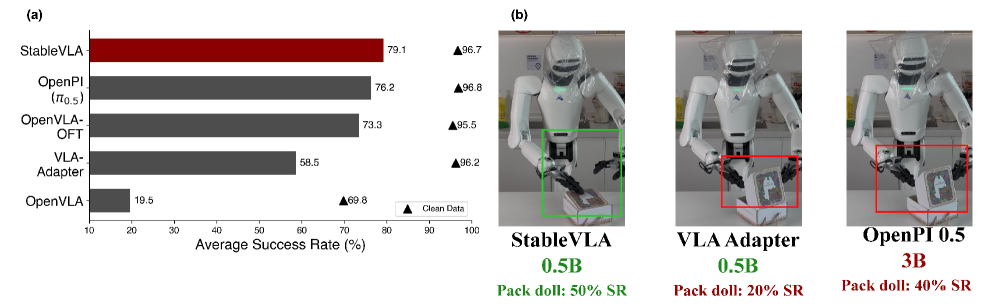
Figure 1 — StableVLA 성능 요약
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Learning to Move Before Learning to Do: Task-Agnostic pretraining for VLAs
- [논문리뷰] ACE-Ego-0: Unifying Egocentric Human and Robotic Data for VLA Pretraining
- [논문리뷰] Hy-Embodied-0.5-VLA: From Vision-Language-Action Models to a Real-World Robot Learning Stack
- [논문리뷰] Robots Need More than VLA and World Models
- [논문리뷰] Silent Failures in Physical AI: A Literature Review of Runtime Action Authorization for Autonomous Systems
Review 의 다른글
- 이전글 [논문리뷰] SkillsVote: Lifecycle Governance of Agent Skills from Collection, Recommendation to Evolution
- 현재글 : [논문리뷰] StableVLA: Towards Robust Vision-Language-Action Models without Extra Data
- 다음글 [논문리뷰] Stop When Reasoning Converges: Semantic-Preserving Early Exit for Reasoning Models
댓글