[논문리뷰] Object-Centric Residual RL for Zero-Shot Sim-to-Real VLA Enhancement
링크: 논문 PDF로 바로 열기
메타데이터
저자: Kinam Kim, Namiko Saito, Heecheol Kim, Katsushi Ikeuchi, Jaegul Choo, Yasuyuki Matsushita
1. Key Terms & Definitions (핵심 용어 및 정의)
- VLA (Vision-Language-Action Models): 대규모 데이터로 사전 학습되어 다양한 로봇 조작 작업을 수행하는 범용 모델로, 주로 imitation learning을 통해 학습되어 정밀한 상호작용에서 성능 저하가 발생함.
- Residual RL: 고정된 기반 정책(Base policy) 위에 학습 가능한 교정 정책(Corrective policy)을 추가하여, 기본 모델의 일반화 성능과 RL의 정밀한 제어 능력을 결합하는 프레임워크.
- Sim-to-Real Transfer: 시뮬레이션에서 학습한 정책을 실제 로봇 환경에 배포하는 과정에서 발생하는 성능 격차를 극복하는 기술적 과제.
- 6-DoF Object Pose: 시뮬레이션과 실제 환경 모두에서 일관되게 추출 가능한 객체의 위치 및 방향 정보를 의미하며, 본 논문의 핵심 관측 공간(Observation space)임.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 imitation learning 기반의 VLA가 실제 로봇의 정밀한 물리적 상호작용에서 발생하는 오차 누적으로 인해 빈번히 실패하는 문제를 해결하고자 한다. 기존의 Residual RL 연구들은 실제 환경에서의 학습 비용과 안전성 문제, 혹은 시뮬레이션과 실제 환경 간의 visual domain gap으로 인해 zero-shot 배포에 어려움을 겪고 있다. 특히 privileged-state를 사용하는 방식은 배포를 위한 별도의 distillation 과정에서 성능 손실이 발생하며, 이미지 기반 방식은 도메인 간의 시각적 불일치를 완전히 극복하지 못한다. 저자들은 이러한 한계를 극복하기 위해, 복잡한 시각 정보 대신 시뮬레이션과 실제 환경 모두에서 일관되게 획득 가능한 객체 상태 기반의 새로운 접근 방식이 필요함을 제기한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 객체 중심의 관측 공간을 활용한 Object-Centric Residual RL 프레임워크를 제안한다. 제안하는 기법은 세 가지 단계로 구성된다: (1) teleoperation replay를 통해 시뮬레이션과 실제 환경 간의 VLA 동작 분포를 정렬하고, (2) 객체 6-DoF pose, proprioception, base action을 결합한 도메인 불변 관측 공간 위에서 TD3를 사용해 residual policy를 학습하며, (3) 훈련 과정에서 pose noise injection과 dropout을 적용하여 실제 환경의 추정 오차에 대한 강건성을 확보한다. 특히 FoundationPose와 SAM2를 활용해 실제 환경에서 안정적으로 포즈를 추적하며, 추적 신뢰도가 낮을 경우 학습된 dropout fallback 메커니즘을 통해 안정성을 유지한다 [3.2, 3.3]. 실험 결과, 5개의 로봇 조작 작업에서 기존 대비 평균 성공률을 42%에서 76%로 비약적으로 향상시켰으며, 별도의 real-world RL이나 추가적인 teleoperation 데이터 없이도 성공적인 배포가 가능함을 증명하였다. 또한, 학습된 residual-corrected rollout을 사용하여 기반 VLA를 재학습함으로써 추가 비용 없는 모델의 자가 개선(Self-improvement)이 가능함을 보였다. [Figure 1] [Figure 2] [Figure 3]
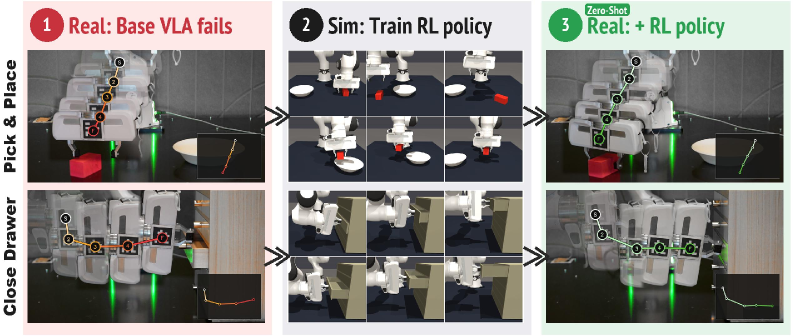
Figure 1 — 객체 중심 Residual RL 개념도
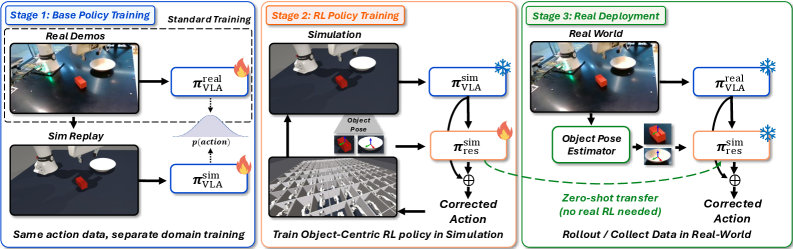
Figure 2 — 전체 Residual RL 파이프라인

Figure 3 — 시뮬레이션 및 실제 로봇 평가 환경
4. Conclusion & Impact (결론 및 시사점)
본 연구는 시뮬레이션에서 학습한 residual 정책을 zero-shot으로 실제 로봇에 성공적으로 전이시키는 실용적이고 효과적인 프레임워크를 제시하였다. 객체 중심의 관측 설계와 강건한 훈련 기법을 통해 sim-to-real 환경의 고질적인 불일치 문제를 해결하였으며, 이는 대규모 VLA의 배포와 로봇 제어의 정밀도를 동시에 달성하는 중요한 이정표가 될 것이다. 또한, 로봇 데이터의 자동 생성과 모델 재학습을 연결하는 self-improvement 루프를 통해 지속 가능한 로봇 학습 생태계 구축에 기여할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] An Anatomy of Vision-Language-Action Models: From Modules to Milestones and Challenges
- [논문리뷰] ACE-Ego-0: Unifying Egocentric Human and Robotic Data for VLA Pretraining
- [논문리뷰] LaWAM: Latent World Action Models for Efficient Dynamics-Aware Robot Policies
- [논문리뷰] Hierarchical Advantage Weighting for Online RL Fine-Tuning of VLAs from Sparse Episode Outcomes
- [논문리뷰] Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
Review 의 다른글
- 이전글 [논문리뷰] NormGuard: Reward-Preserving Norm Constraints in Flow-Matching Reinforcement Learning
- 현재글 : [논문리뷰] Object-Centric Residual RL for Zero-Shot Sim-to-Real VLA Enhancement
- 다음글 [논문리뷰] Parallel Rollout Approximation for Pixel-Space Autoregressive Image Generation
댓글