[논문리뷰] Hierarchical Advantage Weighting for Online RL Fine-Tuning of VLAs from Sparse Episode Outcomes
링크: 논문 PDF로 바로 열기
The full content of the research paper is provided, including abstract, introduction, method, experiments, conclusion, and references, along with several figures.
Now I need to extract the required information and format it according to the instructions.
Part 1: Markdown Summary
-
Authors: Tongyan Fang, Siyuan Huang, Naiyu Fang, Ganlong Zhao, Zhongjin Luo, Jianbo Liu, Xiaogang Wang, Ying Dong, Hongsheng Li
-
Keywords: From the abstract: Vision-Language-Action Models, Online Reinforcement Learning, Robot Manipulation. I will also add some others like "Hierarchical Advantage Weighting", "Sparse Episode Outcomes", "Dual-Head Critic", "Intervention-Aware Credit Assignment".
-
Section 1: Key Terms & Definitions
- VLA (Vision-Language-Action) Models: Pretrained policies capable of generalizing across diverse manipulation tasks, combining visual, linguistic, and action understanding.
- Sparse Episode Outcomes: Online RL fine-tuning often yields only a single binary (success/failure) signal per episode, lacking detailed per-transition feedback.
- Viability: Whether a given state can still lead to successful task completion.
- Efficiency: Given that success is reachable, whether a current transition is advancing towards completion or wasting time.
- Intervention-Aware Credit Assignment: A mechanism to restrict episode outcome labels to policy execution segments, preventing incorrect attribution of outcomes across human intervention boundaries.
-
Section 2: Motivation & Problem Statement
- Pretrained VLA policies, while demonstrating generalization, still require online RL fine-tuning for robust real-world deployment. The core problem is that online RL fine-tuning of VLAs typically yields only a single, sparse binary outcome (success or failure) per episode, whereas actor updates necessitate per-transition supervision. Existing methods commonly reduce this sparse outcome to a single scalar reward or advantage signal, which conflates distinct forms of transition-level feedback, particularly viability and efficiency, and offers limited guidance once basic task success is achieved. Additionally, real-world rollouts often mix autonomous policy execution with human intervention segments, and naively assigning episode outcomes across these segments leads to incorrect credit assignment, potentially reinforcing policy mistakes or penalizing human corrections. These limitations hinder the effective and efficient learning of robust robotic manipulation skills from online interaction.
-
Section 3: Method & Key Results
- 본 논문은 이러한 문제를 해결하기 위해 Hierarchical Advantage-Weighted Behavior Cloning (HABC)을 제안한다 [Figure 1]. HABC는 sparse episode outcomes에서 두 가지 separable한 신호인 viability와 efficiency를 추출하기 위해 dual-head critic을 학습한다. Viability head $V_v$는 현재 상태에서 task success 가능성을 예측하며, 모든 outcome-labeled policy execution windows에서 binary cross-entropy loss로 학습된다. Efficiency head $V_e$는 성공적인 trajectory에서만 steps-to-success를 예측하며, Huber loss로 학습되어 fast progress와 slow progress를 구분한다. 두 critic head의 one-step advantages, $A_v$와 $A_e$,는 state-adaptive gate $g_t$를 통해 결합되어 actor loss의 per-transition weights로 사용된다. 이 gate는 $p_v(s_t)$가 낮을 때는 $A_v$를, 높을 때는 $A_e$를 강조하여 viability가 불확실할 때 생존 가능성을, viability가 높을 때 효율성을 우선시한다. 또한, intervention-aware credit assignment를 통해 outcome labels을 policy execution segments로 제한하여, human intervention과 policy execution 간의 credit leakage를 방지하고 cleaner supervision을 제공한다.
- 실제 로봇 실험에서, HABC는 세 가지 contact-rich bimanual tasks인 Pencil Pouch, Paper Bag, Snack Bag에서 SFT (Supervised Fine-Tuning) baseline 대비 상당한 성능 향상을 보였다 [Figure 3]. HABC는 Pencil Pouch에서 36%에서 92%, Paper Bag에서 44%에서 88%, Snack Bag에서 12%에서 38%로 success rate를 향상시켰다. Efficiency head의 기여를 보여주는 HABC-V (viability head만 사용)에서 HABC로 전환했을 때, mean trajectory length가 Pencil Pouch에서 55프레임, Paper Bag에서 162프레임, Snack Bag에서 32프레임 감소하여 효율성 향상을 입증했다. 이러한 결과는 HABC가 sparse episode outcomes에서 효과적인 transition-level supervision을 추출하여 task success rate와 trajectory efficiency를 모두 개선함을 시사한다.
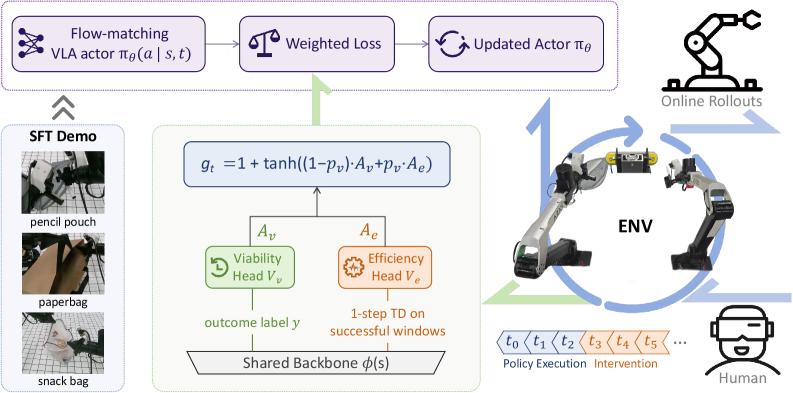
Figure 1 — HABC 방법론 개요
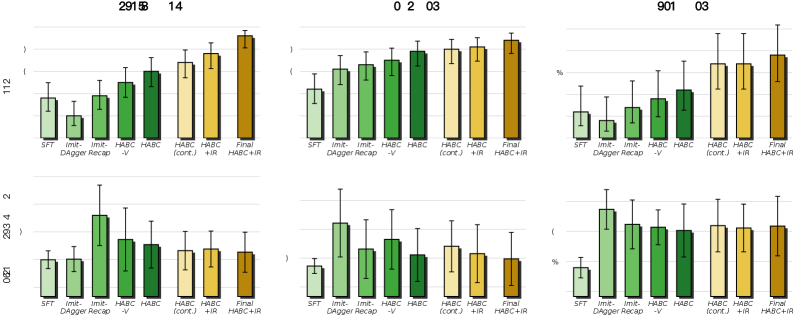
Figure 3 — 세 가지 작업의 주요 결과
- Section 4: Conclusion & Impact
- 본 연구는 sparse episode outcomes에서 per-transition behavior-cloning weights를 생성하는 VLA의 online RL fine-tuning 방법론인 HABC를 제안한다. HABC는 dual-head critic과 intervention-aware credit assignment를 활용하여 viability와 efficiency라는 두 가지 핵심 신호를 분리하고, 이를 바탕으로 효과적인 학습을 가능하게 한다. 이 연구는 VLA fine-tuning 시 직면하는 sparse reward와 mixed-control rollouts 문제에 대한 실질적인 해결책을 제시하며, 특히 contact-rich bimanual tasks와 같이 복잡한 로봇 조작 환경에서 로봇 정책의 robustness와 performance를 크게 향상시킬 수 있음을 입증했다. HABC는 로봇 학습 분야에서 온라인 상호작용을 통해 generalist robot policies를 실제 환경에 배포하고 지속적으로 개선하는 데 중요한 발판을 마련할 것으로 기대된다.
Part 2: Important Figure Information (JSON)
I need to find the <img> tags and their src attributes.
- Figure 1:
2606.17043v1/x1.png->https://arxiv.org/html/2606.17043v1/x1.png - Figure 2:
2606.17043v1/x2.png->https://arxiv.org/html/2606.17043v1/x2.png - Figure 3:
2606.17043v1/x3.png->https://arxiv.org/html/2606.17043v1/x3.png - Figure 4:
2606.17043v1/x4.png(left) and2606.17043v1/x5.png(right). The caption refers to both. I'll pickx4.pngas the main one for the generalization. - Figure 5:
2606.17043v1/x6.png->https://arxiv.org/html/2606.17043v1/x6.png - Figure 6:
2606.17043v1/x7.png->https://arxiv.org/html/2606.17043v1/x7.png - Figure 7:
2606.17043v1/x8.png->https://arxiv.org/html/2606.17043v1/x8.png
I need to select up to 3 figures.
- Figure 1: Overview of HABC (Architecture/Framework Diagram). This is essential.
- Figure 3: Main results across three tasks (Key Quantitative Results). This is also essential for showing performance.
- Figure 6: Recovery behavior: HABC vs. SFT baseline (Qualitative Results/Behavior). This illustrates the impact well. Or Figure 5 for the weight analysis which explains the method better. Figure 5 might be better for explaining the Method, Figure 6 is more Qualitative Results. The prompt asks for "핵심 방법론을 설명하는 그림" and "핵심 결과를 보여주는 비교 테이블 또는 그래프". Figure 5 better explains the method (how the weights are created) and Figure 6 shows an important aspect of the results (recovery behavior). I'll go with Figure 5, as it directly supports the method explanation.
Let's refine the JSON captions.
- Figure 1: "HABC 방법론 개요"
- Figure 3: "세 가지 작업의 주요 결과"
- Figure 5: "Viability 및 효율성 신호 분석"
Double check all constraints:
- Technical Terminology in English: Yes, kept original.
- Natural Korean Phrasing: Yes, mixed style.
- Mandatory Metadata: Yes, Authors and Keywords.
- Output Format: Part 1 (Markdown), Part 2 (JSON) separated by `
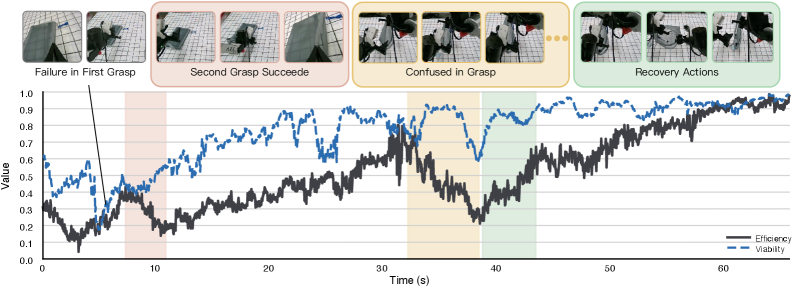
Figure 5 — Viability 및 효율성 신호 분석
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Understanding the Behaviors of Environment-aware Information Retrieval
- [논문리뷰] Thinking with Visual Grounding
- [논문리뷰] Taylor-Calibrate: Principled Initialization for Hybrid Linear Attention Distillation
- [논문리뷰] Selective Synergistic Learning for Video Object-Centric Learning
Review 의 다른글
- 이전글 [논문리뷰] Geometric Action Model for Robot Policy Learning
- 현재글 : [논문리뷰] Hierarchical Advantage Weighting for Online RL Fine-Tuning of VLAs from Sparse Episode Outcomes
- 다음글 [논문리뷰] Implicit Reasoning for Large Language Model-based Generative Recommendation
댓글