[논문리뷰] Geometric Action Model for Robot Policy Learning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jisang Han, Seonghu Jeon, Jaewoo Jung, René Zurbrügg, Honggyu An, Tifanny Portela, Marco Hutter, Marc Pollefeys, Seungryong Kim, Sunghwan Hong
1. Key Terms & Definitions (핵심 용어 및 정의)
- GFM (Geometric Foundation Model): RGB 입력을 바탕으로 3D 기하학적 구조(깊이, 포인트 맵 등)를 추론하도록 사전 학습된 대규모 Transformer 모델입니다.
- GAM (Geometric Action Model): GFM의 일부 계층을 재구성하여 언어 조건부 로봇 조작 정책으로 활용하는 프레임워크입니다.
- Causal Future Predictor: GFM의 중간 계층에 삽입되어 언어, 로봇 상태, 행동 이력을 바탕으로 미래의 기하학적 특징과 행동 토큰을 예측하는 모듈입니다.
- Action Chunking: 로봇 제어를 위해 한 번의 추론으로 일련의 행동(delta-pose 등)을 생성하는 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 Vision-Language-Action Models (VLAs)가 2D 기반의 시각적 지식에 의존하여 3D 물리적 조작 환경에서 깊이, 스케일, 폐색(occlusion)을 명시적으로 추론하지 못하는 한계를 해결하고자 합니다. 대다수의 기존 연구는 GFM을 정적인 특징 추출기로만 활용하거나, 2D 표현 공간에서 행동을 예측하는 데 그칩니다. 결과적으로 이러한 모델들은 카메라 시점 변경이나 환경 변화와 같은 로봇 조작의 핵심 요소에 대해 일반화 능력이 부족합니다. 저자들은 GFM의 구조 내에서 시각적 인지, 미래 예측, 행동 디코딩이 유기적으로 통합된 새로운 정책 모델이 필요하다고 정의합니다 [Figure 1].
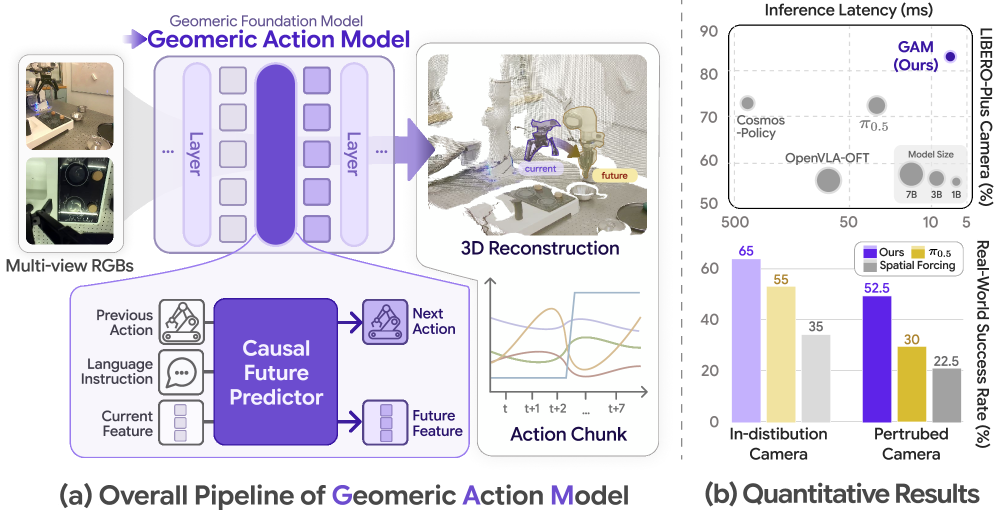
Figure 1 — GAM 아키텍처 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 사전 학습된 GFM을 분할하고 그 사이에 인과적 미래 예측기를 삽입하여, 단일 백본에서 기하학적 추론과 행동 생성을 동시에 수행하는 GAM 아키텍처를 제안합니다 [Figure 3]. Observation Encoder는 얕은 계층을 통해 의미 있는 공간적 표현을 추출하며, Causal Future Predictor는 언어와 행동 이력을 조건으로 미래의 특징 토큰을 예측합니다. 이어서 예측된 토큰들은 남은 GFM 계층을 통과하며 행동 디코딩 및 미래의 3D 기하학적 구조를 동시에 출력합니다. 실험 결과, GAM은 LIBERO-Plus 벤치마크의 카메라 교란 환경에서 기존 SOTA 대비 9.7%p 향상된 강건성을 보였습니다. 또한, 추론 지연 시간(Latency) 측면에서 6.9ms를 기록하며 타 모델 대비 최대 55배 이상의 빠른 성능을 달성하였고, 파라미터 규모 또한 1.4B로 경량화되어 우수한 효율성을 입증했습니다 [Table 1, Table 4].
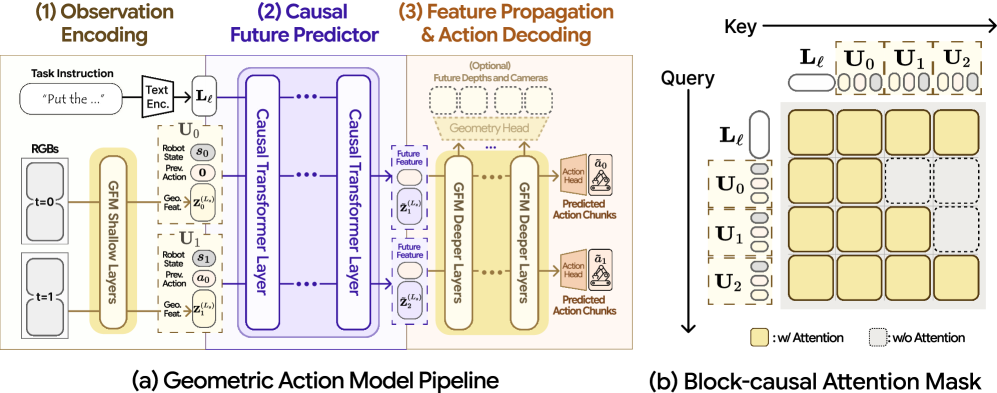
Figure 3 — GAM의 상세 아키텍처
4. Conclusion & Impact (결론 및 시사점)
본 연구는 GFM을 단순히 시각적 인지 도구로 사용하는 것을 넘어, 로봇 정책의 시간적/공간적 월드 모델로서 활용하는 새로운 패러다임을 제시했습니다. GAM은 명시적인 3D 기하학적 사전 지식을 행동 예측과 통합함으로써 조작 환경에서의 높은 일반화 성능과 효율성을 확보하였습니다. 이 연구는 향후 복잡한 물리적 환경에서 활동하는 범용 로봇 정책 개발에 있어 기하학 기반 모델링의 중요성을 재확인하는 계기가 될 것입니다.
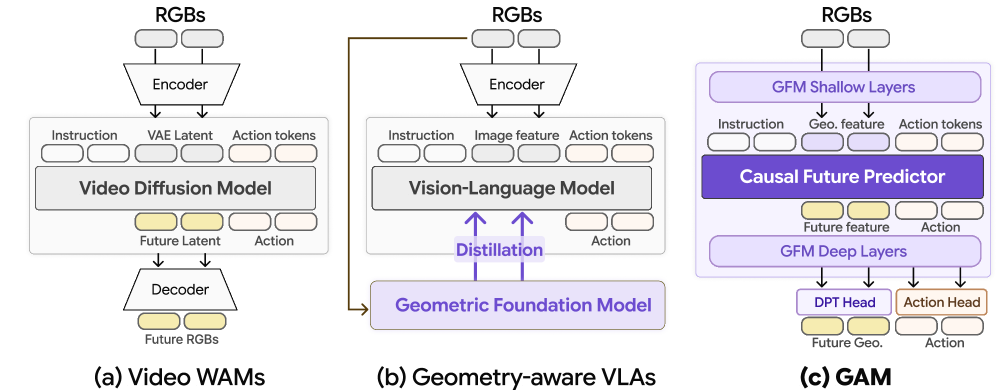
Figure 2 — 기존 방식과 GAM의 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] NORA-1.5: A Vision-Language-Action Model Trained using World Model- and Action-based Preference Rewards
- [논문리뷰] GigaBrain-0: A World Model-Powered Vision-Language-Action Model
- [논문리뷰] Kairos: A Native World Model Stack for Physical AI
- [논문리뷰] ActWorld: From Explorable to Interactive World Model via Action-Aware Memory
- [논문리뷰] Qwen-RobotWorld Technical Report: Unifying Embodied World Modeling through Language-Conditioned Video Generation
Review 의 다른글
- 이전글 [논문리뷰] GD^2PO: Mitigating Multi-Reward Conflicts via Group-Dynamic reward-Decoupled Policy Optimization
- 현재글 : [논문리뷰] Geometric Action Model for Robot Policy Learning
- 다음글 [논문리뷰] Hierarchical Advantage Weighting for Online RL Fine-Tuning of VLAs from Sparse Episode Outcomes
댓글