[논문리뷰] GD^2PO: Mitigating Multi-Reward Conflicts via Group-Dynamic reward-Decoupled Policy Optimization
링크: 논문 PDF로 바로 열기
메타데이터
저자: Haotian Liu, Yihao Liu, Jingwei Ni, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Multi-Reward Conflicts: 서로 다른 보상 차원(예: Helpfulness vs. Safety) 간의 상충으로 인해, 정책 최적화 과정에서 서로 다른 방향의 Advantage가 서로 상쇄되어 학습 효율을 저해하는 현상.
- GDPO (Group reward-Decoupled Policy Optimization): 보상 차원별로 독립적으로 Advantage를 정규화하여 학습하는 기법이나, 최종적으로는 이를 하나의 스칼라 값으로 합산하기 때문에 여전히 Conflict에 취약함.
- Group-Dynamic Filtering: Rollout 수준에서 보상 간의 일관성을 평가하여, 심각한 충돌을 보이는 샘플을 사전에 마스킹(Masking)하여 제거하는 메커니즘.
- Query-level Reweighting: 특정 Query에 대해 신뢰할 수 있는 Rollout의 비율을 계산하고, 이를 기반으로 해당 Query의 업데이트 강도를 동적으로 조절하는 방식.
- SNR (Signal-to-Noise Ratio): 본 논문에서 정의한 일관성 지표로, 개별 보상 차원의 절대적 기여도 총합 대비 최종 합산된 Advantage의 비율을 통해 Conflict 정도를 정량화함.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM의 다차원적 성능 향상을 위해 사용되는 Multi-Reward RL 환경에서 발생하는 Advantage 상쇄 문제를 해결하고자 한다. 기존의 GDPO와 같은 기법은 차원별 Advantage를 분리 계산하더라도, 최종 합산 과정에서 상충하는 신호들이 서로를 지워버려 유효한 학습 신호를 희석시킨다는 한계가 있다. 이러한 Conflict는 모델의 학습 효율을 심각하게 저해하며, 단순한 Reward 가중치 조절이나 Gradient 조정만으로는 Rollout 수준의 미세한 불일치를 해결할 수 없다 [Figure 1]. 따라서 본 연구는 Conflict가 발생하는 Rollout을 효과적으로 선별하고, Query 단위의 업데이트 신뢰도를 반영하는 새로운 최적화 프레임워크의 필요성을 제기한다.
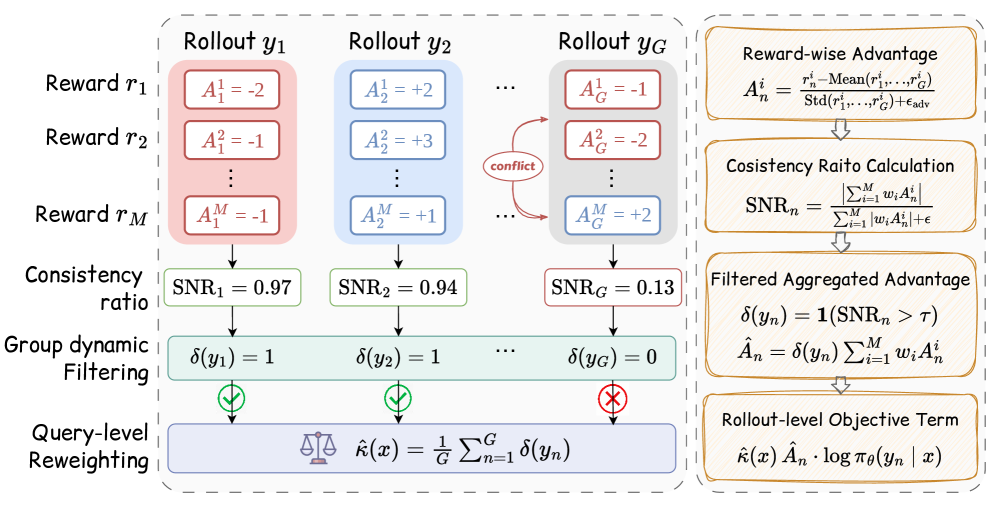
Figure 1 — GD2PO 아키텍처 및 성능 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 GD^2^PO (Group-Dynamic reward-Decoupled Policy Optimization)를 제안하며, 이는 Conflict-aware Filtering과 Query-level Reweighting을 핵심으로 한다 [Figure 1]. 저자들은 Hard Filtering(부호 기반 일관성 검사) 또는 SNR-Based Filtering(보상 일관성 지표 활용)을 통해 상충하는 Rollout을 마스킹하고, 잔여 Rollout의 비율을 사용하여 Query별 업데이트 강도를 동적으로 조정한다 [Figure 1]. 실험 결과, GD^2^PO는 Tool Calling 및 Helpfulness-Safety Alignment 작업에서 기존 GRPO 및 GDPO 대비 일관된 성능 우위를 보였다 [Table 1, Table 2]. 특히 Tool Calling 환경(Correctness + Length)에서 GD^2^PO-Hard는 Qwen2.5-3B-Instruct Backbone 기준 기존 최강 Baseline 대비 Correct Acc.를 유의미하게 개선하였으며, Helpfulness-Safety Alignment에서도 두 보상 지표의 동반 향상을 달성하였다 [Table 1, Table 2]. 이러한 결과는 제안하는 필터링 기법이 무의미한 학습 신호를 제거하고 효과적인 Advantage 신호를 보존함으로써 최적화 효율을 극대화함을 입증한다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Multi-Reward RL의 핵심 난제인 Advantage 상쇄 문제를 Rollout 수준의 필터링과 Query 수준의 재가중치 기법을 통해 성공적으로 해결하였다. GD^2^PO는 복잡한 보상 구조 하에서도 일관된 최적화 방향을 유지하도록 설계되었으며, 다양한 Backbone과 Task에서 그 범용성과 효용성을 증명하였다. 이 연구는 고성능 LLM을 위한 RL Post-Training 과정에서 더 정교한 신호 제어 전략이 필요함을 시사하며, 향후 더욱 다양하고 복합적인 정렬(Alignment) 문제 해결에 기여할 것으로 기대된다.
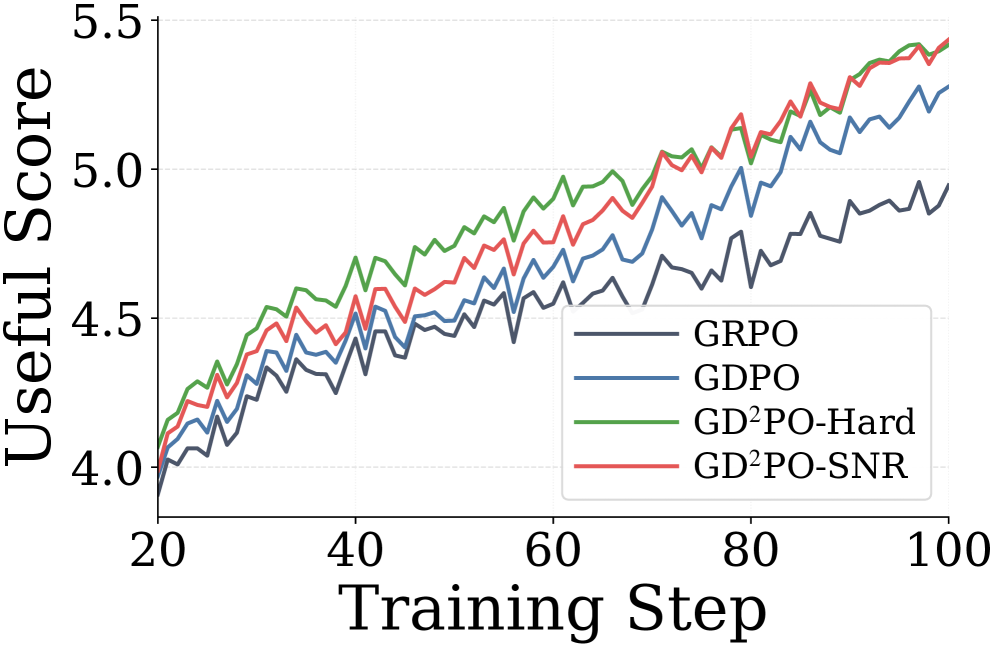
Figure 2 — 정렬 작업 학습 동향(유용성)
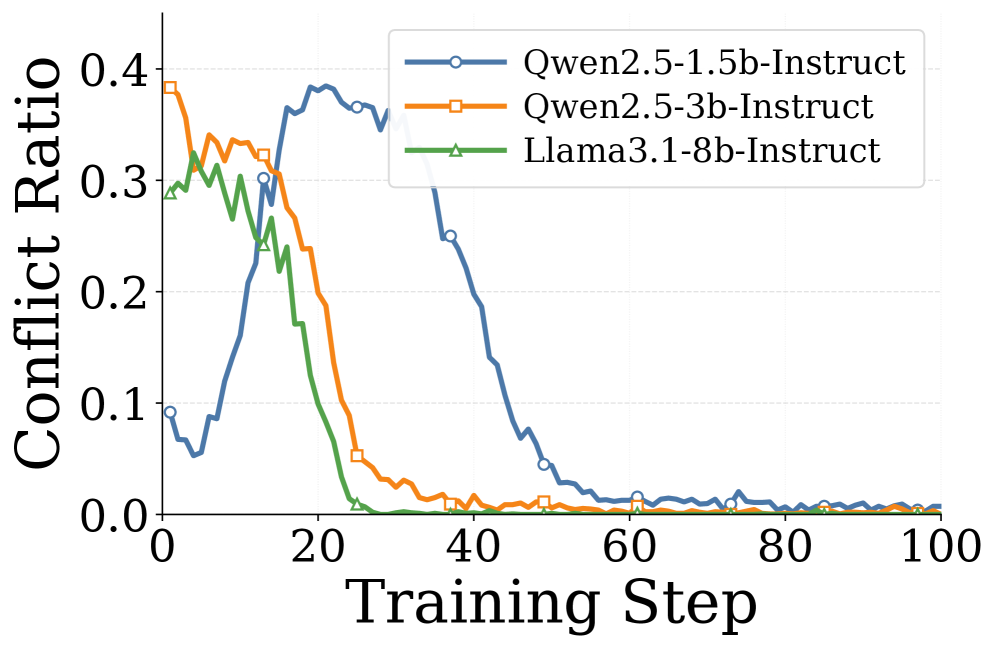
Figure 3 — 학습 중 Conflict 비율 변화
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Reproducing, Analyzing, and Detecting Reward Hacking in Rubric-Based Reinforcement Learning
- [논문리뷰] MARBLE: Multi-Aspect Reward Balance for Diffusion RL
- [논문리뷰] N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
- [논문리뷰] Retrospective Harness Optimization: Improving LLM Agents via Self-Preference over Trajectory Rollouts
- [논문리뷰] Self-Evaluation Is Already There: Eliciting Latent Judge Calibration in Base LLMs with Minimal Data
Review 의 다른글
- 이전글 [논문리뷰] FastContext: Training Efficient Repository Explorer for Coding Agents
- 현재글 : [논문리뷰] GD^2PO: Mitigating Multi-Reward Conflicts via Group-Dynamic reward-Decoupled Policy Optimization
- 다음글 [논문리뷰] Geometric Action Model for Robot Policy Learning
댓글