[논문리뷰] NormGuard: Reward-Preserving Norm Constraints in Flow-Matching Reinforcement Learning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Tianlin Pan, Lianyu Pang, Cheng Da, Huan Yang, Changqian Yu, Kun Gai, Wenhan Luo, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Norm Inflation: RL post-training 과정에서 fine-tuned velocity($v_{\theta}$)의 norm이 reference velocity($v_{\text{ref}}$) 대비 5%에서 15% 정도 비정상적으로 증가하는 현상입니다.
- Velocity-local Post-Training Loss: parameter gradient가 local velocity residuals의 형태로 표현되는 손실 함수를 의미하며, NFT, AWM, DPO 등이 이에 해당합니다.
- NormGuard: RL post-training 시 발생하는 과도한 velocity norm inflation을 억제하기 위해 제안된 hinge penalty 기반의 정규화 기법입니다.
- Adjoint Sensitivity Analysis: velocity magnitude rescaling이 전체 batch 수준에서 유의미한 첫 번째 순서(first-order)의 보상 신호를 가지는지 검증하기 위해 사용된 분석 방법입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 Flow-matching 모델의 RL post-training 시 발생하는 reward over-optimization과 그에 따른 지각적 품질 저하 문제를 해결합니다. 기존의 RL fine-tuning은 보상 점수를 상승시키지만, over-sharpening, 색상 왜곡, 부자연스러운 조명 등의 시각적 artifacts를 유발합니다 [Figure 2]. 저자들은 이러한 현상이 Classifier-Free Guidance(CFG)와 유사한 Norm Inflation으로 인해 발생함을 밝혀냈습니다 [Figure 3]. 기존의 inference-time renormalization 기법은 RL 모델에 적용 시 모델 weights에 이미 내재된 inflation을 해결하지 못하며 보상 유지에도 실패한다는 한계가 있습니다 [Figure 2].
Figure 2 — NormGuard의 연구 동기 및 개념도
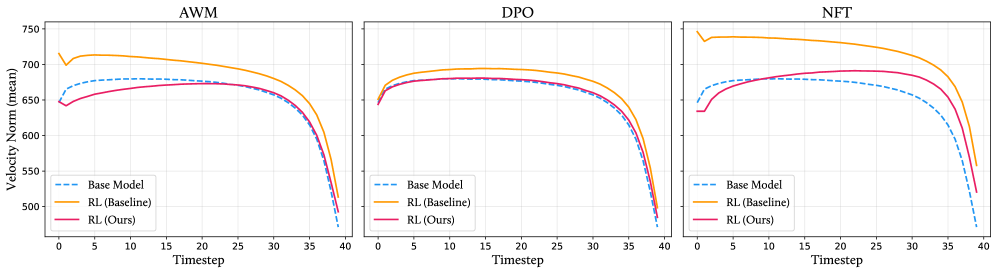
Figure 3 — RL 학습에 따른 Norm Inflation 현상
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 논문은 velocity norm이 reference 모델의 norm을 초과할 때만 활성화되는 hinge penalty인 NormGuard를 제안합니다 [Figure 2]. 이 방법론은 모델이 학습 과정에서 과도한 norm 성장을 방지하도록 유도하며, 다양한 Velocity-local Post-training losses와 가산적으로 결합할 수 있는 유연성을 제공합니다. 실험 결과, NormGuard는 SD3.5-Medium 및 FLUX.2-4B 모델에서 NFT, AWM, DPO 등 다양한 기법들과 결합하여 우수한 성능을 보였습니다 [Table 2]. 정량적 평가에서 MLLM(Qwen3.5, GPT-4.1) 기반 품질 평가와 RealScore(Forensic realism detection) 지표 모두에서 baseline 대비 일관된 향상을 달성하였습니다 [Table 3]. 특히, Few-step inference 환경에서 품질 개선 효과가 더욱 두드러지며, 기존 KL regularization과 상호 보완적인 관계임을 입증했습니다 [Table 4, Table 6].
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 RL post-training에서 발생하는 velocity norm inflation이 시각적 artifacts의 주요 원인임을 규명하고, 이를 억제하는 NormGuard를 통해 보상 점수를 유지하면서도 생성 품질을 효과적으로 개선했습니다. 이 연구는 RLHF 과정에서 흔히 발생하는 보상 최적화의 부작용을 기술적으로 분해하고 해결할 수 있는 새로운 진단 프레임워크를 제시합니다. 학계와 산업계에서는 본 연구를 통해 복잡한 보상 함수 환경에서도 고품질의 생성 모델을 안정적으로 정렬(alignment)할 수 있는 가이드라인을 확보하게 되었습니다.

Figure 1 — NormGuard의 시각적 개선 효과
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Video Models Can Reason with Verifiable Rewards
- [논문리뷰] Xiaomi-GUI-0 Technical Report
- [논문리뷰] Reinforcement Learning with Metacognitive Feedback Elicits Faithful Uncertainty Expression in LLMs
- [논문리뷰] QVal: Cheaply Evaluating Dense Supervision Signals for Long-Horizon LLM Agents
- [논문리뷰] Dockerless: Environment-Free Program Verifier for Coding Agents
Review 의 다른글
- 이전글 [논문리뷰] MultiHashFormer: Hash-based Generative Language Models
- 현재글 : [논문리뷰] NormGuard: Reward-Preserving Norm Constraints in Flow-Matching Reinforcement Learning
- 다음글 [논문리뷰] Object-Centric Residual RL for Zero-Shot Sim-to-Real VLA Enhancement
댓글