[논문리뷰] MultiHashFormer: Hash-based Generative Language Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Huiyin Xue, Atsuki Yamaguchi, Nikolaos Aletras
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Multi-ID Signature: 여러 독립적인 hash function을 사용하여 토큰을 짧은 고유 정수 ID 시퀀스로 변환하는 방식입니다.
- Hash Encoder: 다중 해시 ID 시퀀스를 입력받아 이를 gated compositional embedding을 통해 단일 latent vector로 압축하는 모듈입니다.
- Hash Decoder: cascaded predictor를 통해 다음 토큰의 다중 해시 ID 시퀀스를 auto-regressive하게 생성하는 모듈입니다.
- Vocabulary Bottleneck: 임베딩 행렬이 어휘 사전 크기에 선형적으로 비례하여 모델의 확장성을 제한하는 문제를 의미합니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 고정된 어휘 사전 크기로 인해 발생하는 vocabulary bottleneck 문제를 해결하고, 파라미터 효율적인 causal language modeling을 가능하게 하는 것을 목표로 합니다. 기존의 hash-based 모델(Proformer, HashFormer 등)은 many-to-one collision 문제로 인해 생성형 언어 모델의 디코더 아키텍처에 적용하기 어려웠습니다. 결과적으로 이러한 기존 접근 방식은 고유 토큰 복원이 불가능하여 generative setting에서 성능이 제한되었습니다. 본 논문은 이러한 collision 문제를 해결함으로써 파라미터 footprint를 효율적으로 제어하는 새로운 프레임워크를 제안합니다. [Figure 1]에 제시된 다중 해시 매핑 전략을 통해 모델은 토큰 간 충돌을 방지하고, 새로운 언어에 대해 모델 구조 변경 없이 vocabulary expansion을 지원할 수 있습니다.
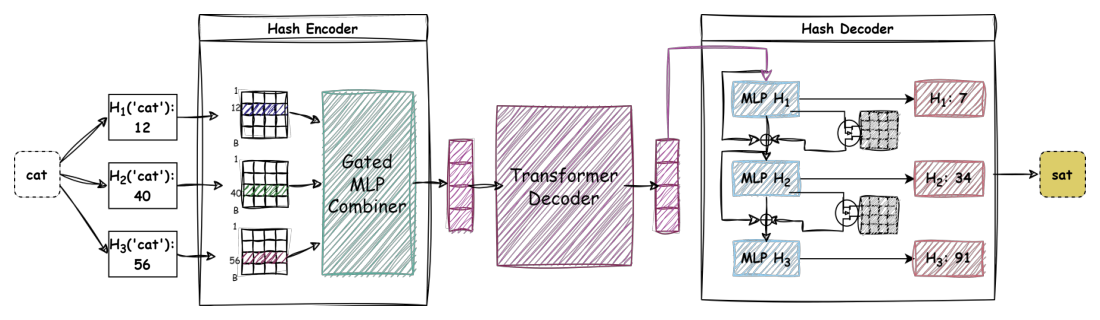
Figure 1 — 제안하는 MultiHashFormer의 전체 아키텍처 및 다중 해시 매핑 과정의 핵심을 보여주는 다이어그램입니다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
MultiHashFormer는 토큰을 고유한 다중 해시 시퀀스로 변환한 뒤, 이를 학습 가능한 임베딩 매트릭스와 gated compositional gate를 통해 처리함으로써 기존의 선형 확장 문제를 극복합니다. 본 모델은 causal language modeling을 지원하기 위해 cascaded predictor를 사용하여 각 해시 ID를 순차적으로 예측하고, 이를 통해 deterministically하게 토큰을 복원합니다. 100M, 1B, 3B 파라미터 스케일에서 실험한 결과, MultiHashFormer는 대부분의 벤치마크에서 기존의 Standard Transformer 모델을 능가하는 성능을 보였습니다. 특히 1B 파라미터 환경에서 LAMBADA 작업의 경우 MultiHashFormer (H4B16K)가 기존 Standard baseline(30.41%) 대비 유의미한 성능 향상을 달성했습니다. 또한, vocabulary를 32K에서 48K로 확장하면서도 추가 파라미터 없이 성능을 유지하는 강건함을 입증했습니다. [Table 1]은 이러한 모델의 비교 우위를 상세히 보여줍니다.
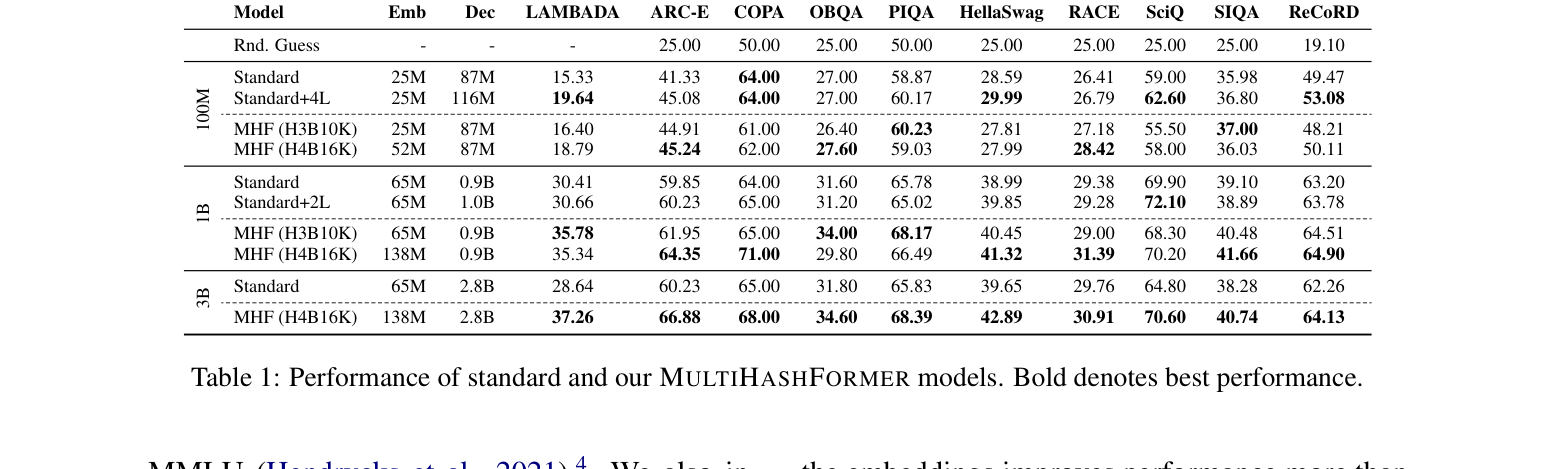
Table 1 — 표준 Transformer 모델과 제안 모델 간의 주요 벤치마크 지표를 비교한 핵심 결과 테이블입니다.
## 4. Conclusion & Impact (결론 및 시사점) MultiHashFormer는 혁신적인 다중 해시 기반의 아키텍처를 통해 언어 모델의 고질적인 vocabulary bottleneck을 성공적으로 해결하였습니다. 본 연구는 파라미터 수를 증가시키지 않으면서도 어휘 사전 확장이 가능함을 실증하였으며, 특히 희귀 단어 표현(rare word representation) 학습에 탁월한 효과를 입증했습니다. 이는 컴퓨팅 자원이 제한된 환경에서도 고성능 대규모 언어 모델을 학습시키고 배포하는 데 중요한 기여를 할 것으로 기대됩니다. 향후 대규모 모델(7B 이상)에서의 확장성 연구는 학계 및 산업계 전반에 걸쳐 효율적인 모델 설계에 중요한 이정표가 될 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] A Causal Language Modeling Detour Improves Encoder Continued Pretraining
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] When LLMs Read Tables Carelessly: Measuring and Reducing Data Referencing Errors
- [논문리뷰] Valdi: Value Diffusion World Models
- [논문리뷰] TurboServe: Serving Streaming Video Generation Efficiently and Economically
Review 의 다른글
- 이전글 [논문리뷰] Learning to Fold: prizewinning solution at LeHome Challenge 2026 (1st place online, 2nd offline)
- 현재글 : [논문리뷰] MultiHashFormer: Hash-based Generative Language Models
- 다음글 [논문리뷰] NormGuard: Reward-Preserving Norm Constraints in Flow-Matching Reinforcement Learning
댓글