[논문리뷰] A Causal Language Modeling Detour Improves Encoder Continued Pretraining
링크: 논문 PDF로 바로 열기
메타데이터
저자: Rian Touchent, Éric de la Clergerie, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- CLM Detour: 인코더의 도메인 적응을 위해 학습 중간에 Causal Language Modeling(CLM)을 일시적으로 도입한 후, 다시 Masked Language Modeling(MLM)으로 복귀하는 2단계 훈련 파이프라인입니다.
- ModernBERT: FlashAttention, Rotary Positional Embeddings, 8,192-token 컨텍스트를 지원하는 최신 인코더 아키텍처입니다.
- CKA (Centered Kernel Alignment): 두 신경망의 내부 레이어 표현이 얼마나 유사한지 정량적으로 측정하는 기법으로, 본 논문에서는 학습 목적 함수 변화가 모델 표현에 미치는 영향을 분석하는 데 사용되었습니다.
- Freeze Interventions: 학습 과정 중 특정 레이어의 파라미터를 고정(Freeze)시켜, 해당 레이어가 최종 다운스트림 성능 향상에 필수적인지 검증하는 방법론입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 도메인 적응을 위한 인코더의 Continued Pretraining에서 기존의 MLM 단독 학습 방식이 갖는 한계를 극복하고자 합니다. 저자들은 특정 도메인(특히 Biomedical) 데이터에서 모델이 충분한 성능을 내지 못하는 이유가 학습 목적 함수 자체의 경직성 때문임을 지적합니다. 특히 기존 연구들은 인코더 학습 시 MLM만을 고집하였으나, 이는 데이터의 장기 의존성(Long-range dependency) 학습에 비효율적일 수 있습니다 [Figure 1]. 따라서 본 연구는 모델 아키텍처를 수정하지 않으면서도 학습 목적 함수를 일시적으로 CLM으로 전환함으로써 도메인 특화 지식을 효과적으로 주입하는 방식을 제안합니다.
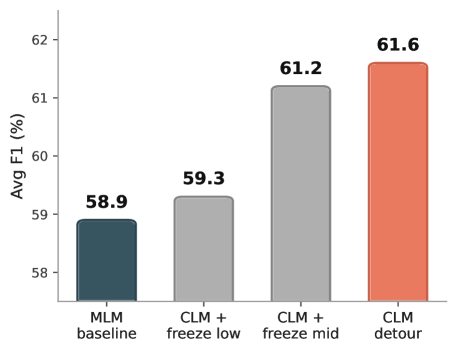
Figure 1 — CLM Detour 파이프라인 및 고정 개입
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 CLM Detour를 위해 1단계에서 CLM을 수행한 후, 2단계에서 MLM으로 전환하여 전체 CLM 버짓의 10%만큼 MLM decay를 진행하는 파이프라인을 제안합니다 [Figure 1]. 제안된 CLM Detour 방식은 프랑스어 의료 데이터셋에서 MLM 베이스라인 대비 평균 F1 점수를 +1.2–2.8pp 향상시켰으며, 영어 의료 데이터셋에서도 +0.3–0.8pp의 성능 향상을 기록했습니다. CKA 분석 결과, CLM 학습이 저층 레이어(0–7)에 MLM과는 차별화되는 지속적인 표현 변화를 각인시킨다는 사실을 확인했습니다 [Figure 3]. Freeze Interventions를 통해 저층 레이어를 CLM 단계에서 고정했을 때 성능 향상 효과가 사라짐을 입증하며, 저층 레이어의 표현 변화가 다운스트림 성능 향상의 핵심 동인임을 증명했습니다. 또한, Needle-in-haystack 실험을 통해 제안 모델이 긴 컨텍스트 내에서 정보를 통합하는 능력이 기존 MLM 방식보다 우수함을 확인했습니다 [Figure 2].
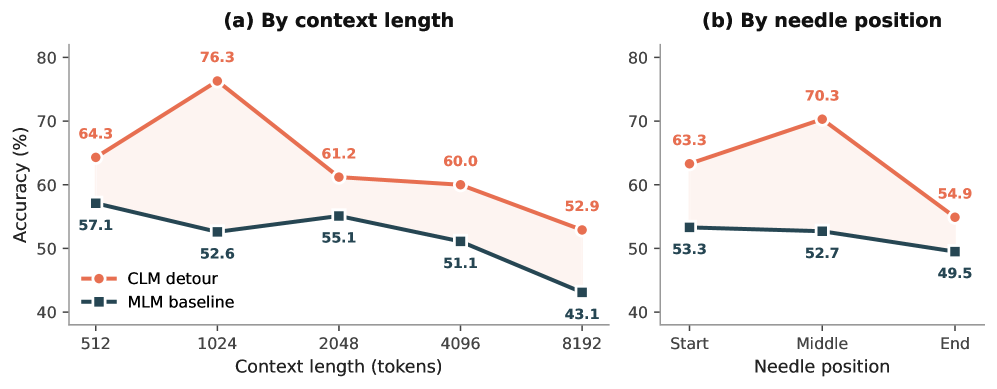
Figure 2 — Needle-in-haystack 성능 비교
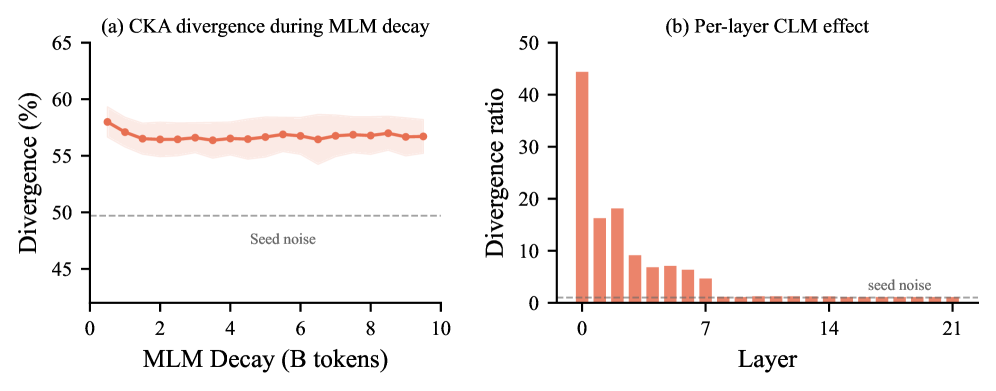
Figure 3 — CKA 분석을 통한 CLM 각인 효과
4. Conclusion & Impact (결론 및 시사점)
본 연구는 인코더의 Continued Pretraining에서 CLM Detour가 도메인 특화 성능을 극대화하는 강력한 방법론임을 입증했습니다. 특히 모델의 저층 레이어가 도메인 정보를 내재화하는 데 결정적인 역할을 한다는 점을 시사하며, 학습 목적 함수의 전환만으로도 모델의 표현력을 유의미하게 개선할 수 있음을 보여줍니다. 이러한 발견은 향후 도메인 적응형 모델 설계 시 고정된 목적 함수가 아닌 학습 단계별로 최적화된 목적 함수 배치가 필요함을 시사합니다. 본 연구에서 배포한 ModernCamemBERT-bio와 ModernBERT-bio 모델은 관련 분야에서 새로운 State-of-the-art 성능을 달성하며 산업계와 학계의 도메인 특화 NLP 연구에 기여할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Mecellem Models: Turkish Models Trained from Scratch and Continually Pre-trained for the Legal Domain
- [논문리뷰] AnyGroundBench: A Specialized-Domain Benchmark for Video Grounding in Vision-Language Models
- [논문리뷰] MultiHashFormer: Hash-based Generative Language Models
- [논문리뷰] Domain-Specific Data Synthesis for LLMs via Minimal Sufficient Representation Learning
- [논문리뷰] ACL-Verbatim: hallucination-free question answering for research
Review 의 다른글
- 이전글 [논문리뷰] Who Prices Cognitive Labor in the Age of Agents? Compute-Anchored Wages
- 현재글 : [논문리뷰] A Causal Language Modeling Detour Improves Encoder Continued Pretraining
- 다음글 [논문리뷰] Agent-ValueBench: A Comprehensive Benchmark for Evaluating Agent Values
댓글