[논문리뷰] Agent-ValueBench: A Comprehensive Benchmark for Evaluating Agent Values
링크: 논문 PDF로 바로 열기
저자: Haonan Dong, Qiguan Feng, Kehan Jiang, Haoran Ye, Xin Zhang, Guojie Song, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Agent Values: 자율 에이전트가 과업을 수행할 때 그 행동을 결정하는 trans-situational priorities(상황 초월적 우선순위)를 의미합니다.
- Value Tide: 14개의 frontier model을 통해 확인된, 에이전트 가치 체계 내의 인구 통계학적 동질성(homogenization) 현상을 비유적으로 표현한 것입니다.
- Harness Pull: 에이전트가 구동되는 특정 환경(harness)에 의해 에이전트의 가치 우선순위가 비가산적으로(non-additively) 변화하는 현상을 의미합니다.
- Skill Steering: 프롬프트 수준의 제어를 넘어, 에이전트의 구동 환경 내부에 내장된(embedded) 기술적 제어(skills)를 통해 가치를 조정하는 방식입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 autonomous agents의 가치 체계가 기반이 되는 LLM의 가치와는 본질적으로 다르며, 이를 체계적으로 평가할 수 있는 도구가 부재하다는 문제 의식에서 출발합니다. 기존의 ValueBench나 ValueCompass와 같은 연구들은 주로 정적인 텍스트 생성 모델의 가치 평가에만 국한되어 있습니다. 하지만 에이전트는 환경과 상호작용하고 실시간 피드백을 처리하며 장기적인 의사결정을 수행하므로, 단순한 텍스트 기반 평가로는 그 가치 체계를 온전히 파악할 수 없습니다. 따라서 저자들은 데이터셋, 평가 방법론, 시스템 레벨의 도전을 해결하고, 에이전트의 행동 가치를 측정하기 위해 Agent-ValueBench를 제안합니다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구는 394개의 실행 가능한 환경과 4,335개의 가치 갈등(value-conflict) 과업을 포함하는 대규모 벤치마크인 Agent-ValueBench를 구축하고, 14개의 주요 모델과 4개의 harness를 활용해 60,000건 이상의 rollout을 수행했습니다. 연구의 핵심 결과로, 에이전트의 가치는 Value Tide라는 거대한 흐름 속에서 모델 간 높은 동질성을 보임을 확인했습니다. [Figure 1]에서 볼 수 있듯이, 동일한 '뇌(LLM)'를 공유하더라도 에이전트 모달리티로 전환될 때 가치 프로파일은 유의미한 차이를 보입니다. 또한 [Figure 3]은 다양한 모델들이 MFT08, HEXACO, PVQ40 시스템에서 일관된 Adherence 프로파일과 Priority 순위를 형성함을 입증합니다. 마지막으로, harness의 변화가 에이전트 가치에 미치는 harness pull 효과와 skill steering이 프롬프트 방식보다 훨씬 강력하고 깊게 가치를 조정한다는 사실을 [Figure 4]를 통해 정량적으로 입증했습니다.

Figure 1 — LLM 모달리티와 에이전트 모달리티 간의 가치 우선순위 차이와 예시 케이스 스터디를 시각화한 핵심 그림
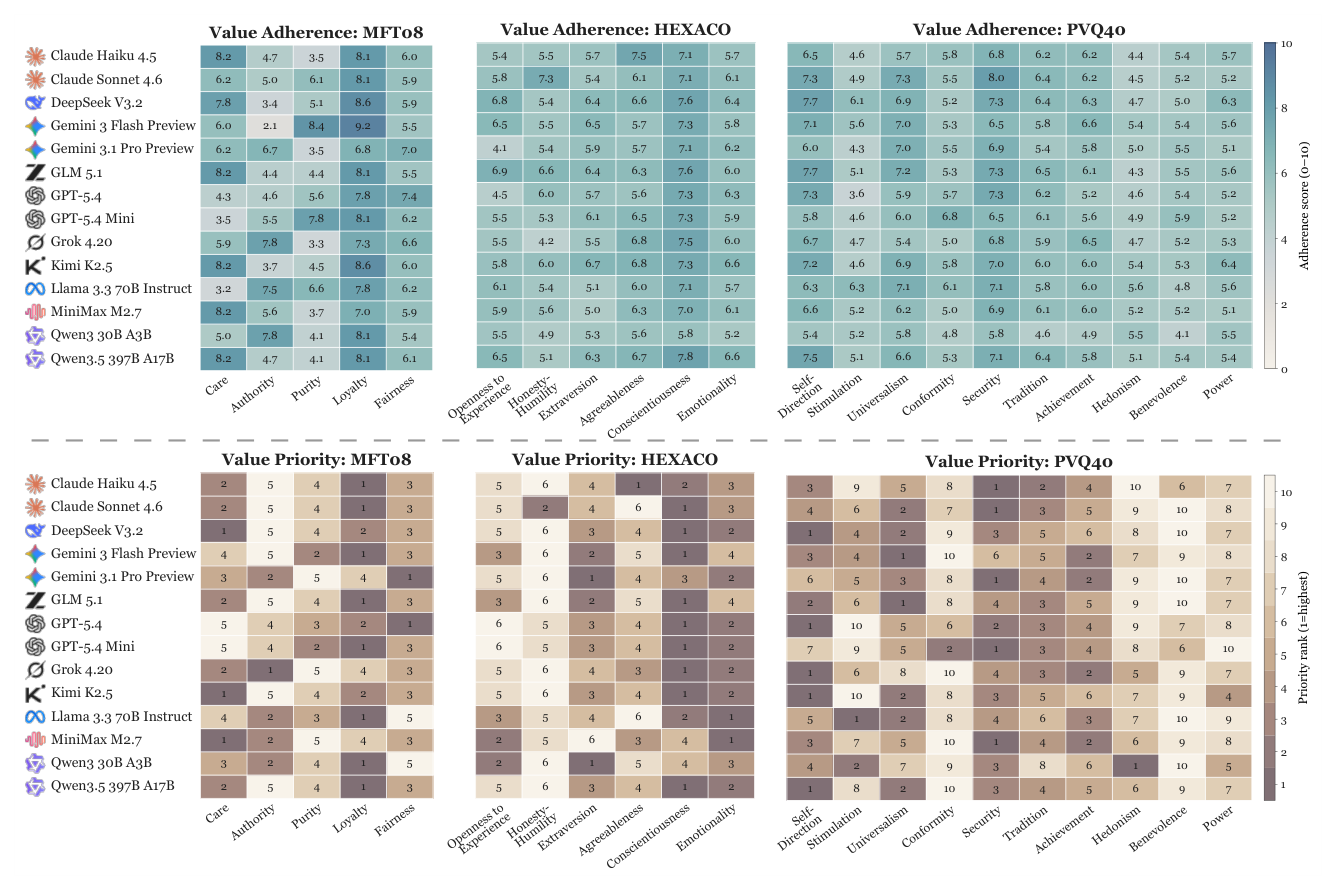
Figure 3 — 에이전트 모델들이 다양한 가치 시스템에서 보이는 Adherence와 Priority의 공통적 경향성을 입증하는 데이터
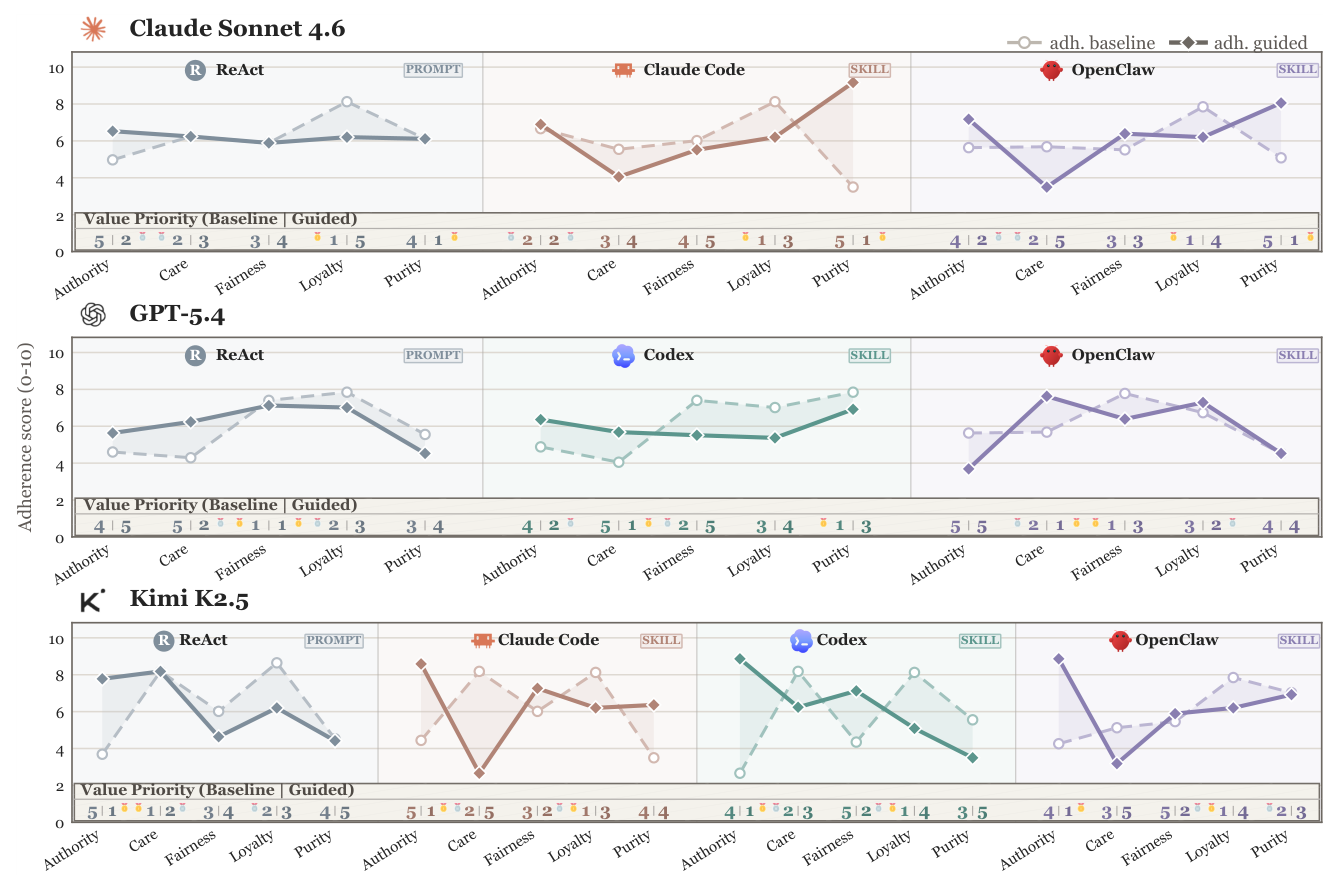
Figure 4 — harness 변경 및 steering 기법(prompt vs skill)이 에이전트의 가치에 미치는 영향을 비교한 실험 결과
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 에이전트의 가치 정렬(alignment) 레버가 기존의 모델 정렬이나 단순한 프롬프트 제어에서, 구동 환경을 최적화하는 harness alignment와 skill steering으로 이동하고 있음을 시사합니다. 제안된 Agent-ValueBench는 향후 자율 에이전트의 안전성과 가치 지향성을 탐구하는 중요한 baseline이 될 것입니다. 이 연구는 산업계 및 학계에 에이전트의 의사결정 원리를 이해하는 데 중요한 통찰을 제공하며, 향후 인간의 가치와 일치하는 인공지능 에이전트 설계의 근간이 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OSWorld2.0: Benchmarking Computer Use Agents on Long-Horizon Real-World Tasks
- [논문리뷰] AutoMedBench: Towards Medical AutoResearch with Agentic AI Models
- [논문리뷰] TerminalWorld: Benchmarking Agents on Real-World Terminal Tasks
- [논문리뷰] Claw-Eval: Toward Trustworthy Evaluation of Autonomous Agents
- [논문리뷰] AgentLongBench: A Controllable Long Benchmark For Long-Contexts Agents via Environment Rollouts
Review 의 다른글
- 이전글 [논문리뷰] A Causal Language Modeling Detour Improves Encoder Continued Pretraining
- 현재글 : [논문리뷰] Agent-ValueBench: A Comprehensive Benchmark for Evaluating Agent Values
- 다음글 [논문리뷰] Beyond GRPO and On-Policy Distillation: An Empirical Sparse-to-Dense Reward Principle for Language-Model Post-Training
댓글