[논문리뷰] Beyond GRPO and On-Policy Distillation: An Empirical Sparse-to-Dense Reward Principle for Language-Model Post-Training
링크: 논문 PDF로 바로 열기
본 논문은 Language-Model post-training 과정에서 제한된 labeled training data를 효율적으로 활용하기 위한 Reward-Density Principle을 제안하며, sparse reward와 dense reward를 적절한 모델에 순차적으로 할당하는 최적의 파이프라인을 제시한다.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Sparse Reward: trajectory 종료 시점에 단 한 번 주어지는 sequence-level 보상으로, 전통적인
RL방식(예:GRPO)에서 주로 사용된다. - Dense Reward:
Teacher모델의log-probability를 활용하여 매 token마다 주어지는 보상으로,OPD(On-Policy Distillation)에서 활용된다. - Two-Stage Bridge:
Teacherrollouts에 대한 Forward-KL warmup 후,Studentrollouts에 대해 OPD를 수행하여Teacher의 지식을Student모델로 효과적으로 전달하는 기법이다. - Reward-Density Principle:
Sparse보상은 탐색 능력이 뛰어난 대형Teacher모델 학습에 사용하고, 이를 통해 정제된Dense보상을 활용하여 중소형Student모델을 효율적으로 압축(distill)하는 전략적 자원 할당 원칙이다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 Language-Model post-training 시 제한된 labeled training data가 비효율적으로 사용되는 문제를 해결하고자 한다. 기존의 관행인 GRPO 등을 통해 deployment student 모델에 직접 Sparse Reward를 적용하는 방식은, 탐색 능력이 부족한 소형 모델에서 reward signal을 효과적으로 학습하지 못하게 만든다 [Figure 1]. 따라서 저자들은 Sparse 보상과 Dense 보상이 상충하는 개념이 아니라 동일한 KL-regularized 목적 함수 내의 다른 reward-density regime임을 규명하고, 데이터 할당 순서를 최적화하는 새로운 접근 방식을 제안한다 [Figure 1].
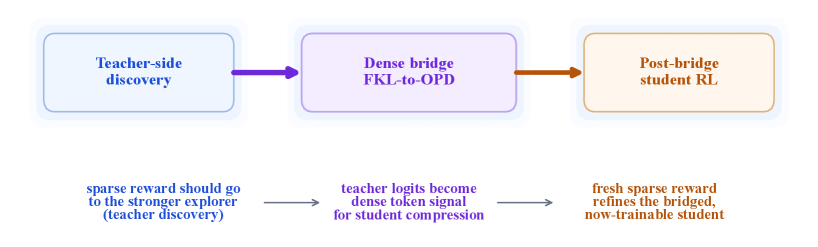
Figure 1 — 제안된 3단계 데이터 할당 파이프라인
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 제안한 Reward-Density Principle에 따라, Labeled Training Data를 먼저 대형 Teacher 모델의 Sparse RL에 사용하여 보상 기반의 강력한 Teacher 정책을 발견한다. 이후, 이 Teacher로부터 Two-Stage Bridge(Forward-KL warmup + OPD)를 거쳐 Student 모델로 지식을 전이하며, 최종적으로 남아있는 labeled data를 사용하여 Student 모델의 Sparse RL을 수행하는 3단계 파이프라인을 확립한다 [Figure 1].
실험 결과, Qwen3-1.7B 모델을 Student로 사용할 때, 해당 파이프라인을 적용한 경우가 기존 Direct GRPO 대비 MATH 벤치마크에서 79.3% vs 75.9%로 성능 우위를 보였다 [Table 3]. 또한, AIME 2024에서도 25.2 vs 19.8의 점수를 기록하며 정량적 지표에서 명확한 비교 우위를 입증했다. 특히, Two-Stage Bridge는 기존의 OPD-only나 Teacher-sample SFT 방식보다 항상 높은 성능을 기록하여, 지식 전이의 안정성과 효율성을 동시에 달성하였다 [Table 3].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Language-Model post-training의 핵심이 단순한 알고리즘 선택이 아니라, 자원 할당의 순서와 보상의 밀도(density) 최적화에 있음을 밝혀냈다. 제안된 Two-Stage Bridge 파이프라인은 Teacher-Student 구조를 활용하는 모든 학계 및 산업계 모델 학습 프로세스에 즉시 적용 가능하며, 특히 Verifiable task 데이터가 부족한 환경에서 모델의 성능을 극대화하는 표준 지침이 될 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Agent-ValueBench: A Comprehensive Benchmark for Evaluating Agent Values
- 현재글 : [논문리뷰] Beyond GRPO and On-Policy Distillation: An Empirical Sparse-to-Dense Reward Principle for Language-Model Post-Training
- 다음글 [논문리뷰] Continual Harness: Online Adaptation for Self-Improving Foundation Agents
댓글