[논문리뷰] VideoSeeker: Incentivizing Instance-level Video Understanding via Native Agentic Tool Invocation
링크: 논문 PDF로 바로 열기
저자: Yiming Zhao, Yu Zeng, Wenxuan Huang, Zhen Fang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Visual Prompts: 사용자가 비디오 프레임 내의 특정 영역을 직접 표시(예: bounding box, mask, point)하여 객체에 대한 공간적·시간적 참조를 제공하는 방식입니다.
- Agentic Tool Invocation: 모델이 능동적으로 perception tools를 선택하고 실행하여 비디오 환경과 상호작용함으로써, 효율적인 정보 획득 및 추론을 수행하는 능력을 의미합니다.
- GRPO (Group Relative Policy Optimization): 다수의 출력 후보군을 생성하고, 그룹 내 상대적 보상을 통해 모델의 추론 정책을 최적화하는 강화학습 기법입니다.
- Instance-level Video Understanding: 비디오 내 특정 객체나 대상 인스턴스를 정확하게 위치 추적(localization)하고 해당 인스턴스의 동적 변화를 추론하는 복합적인 과업입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 LLM 기반 비디오 이해 모델들이 겪는 공간적·시간적 참조의 모호성 문제를 해결하기 위해 VideoSeeker를 제안한다. 기존 연구들은 주로 텍스트 프롬프트에 의존하여 정밀한 대상 위치 지정에 한계를 보였으며, visual perception과 language reasoning이 분리되어 있어 세밀한 시각적 증거를 포착하는 데 어려움을 겪었다 [Figure 1]. 또한, 홀리스틱한(holistic) 비디오 이해에만 집중된 연구 경향으로 인해 특정 인스턴스 중심의 정교한 시공간적 추론 능력이 결여되어 있다. 이러한 한계를 극복하고자 저자들은 시각적 프롬프트를 활용하여 모델이 능동적으로 핵심 정보를 탐색하고 인지하도록 하는 새로운 에이전트 패러다임을 설계하였다.
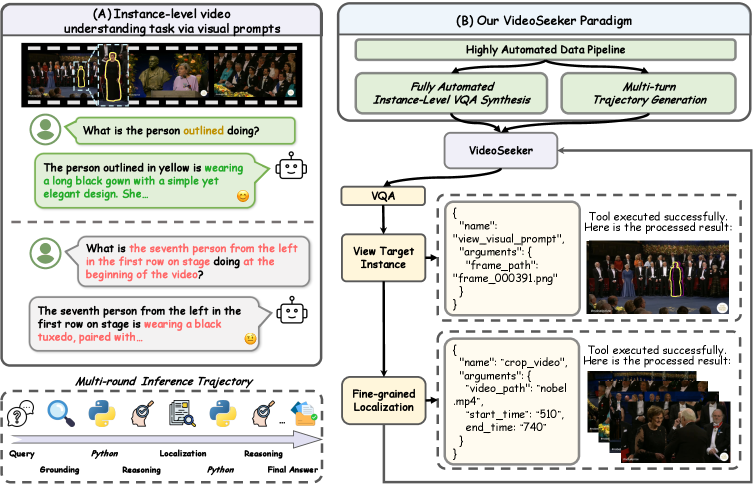
Figure 1 — VideoSeeker 아키텍처 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 instance-level 비디오 데이터를 자동으로 생성하는 4단계 파이프라인과 이를 활용한 2단계 학습 전략을 제안한다 [Figure 2]. 데이터 파이프라인은 Text Filtering, Video-level Verification, Pixel-level Mask Generation(via SAM3), 그리고 Visual Prompt Rendering 단계를 거쳐 고품질의 시각적 프롬프트 데이터를 확보한다. 학습은 SFT를 통한 cold-start supervision과 GRPO를 기반으로 한 agentic RL을 통해 수행되며, 모델은 환경 보상(정확도, 형식 준수, 효율성)을 최대화하며 능동적인 인식 정책을 내재화한다. 실험 결과, VideoSeeker-8B 모델은 V2P-Bench에서 기존 Baseline 대비 평균 +13.7%의 성능 향상을 기록하며, GPT-4o 및 Gemini-2.5-Pro와 같은 강력한 상용 모델의 성능을 상회하였다 [Table 1]. 또한, 본 모델은 인스턴스 수준의 학습만으로도 일반 비디오 이해 벤치마크(Video-MME 등)에서 유의미한 전이 학습 성능(+3.2%~+3.3%)을 입증하였다.
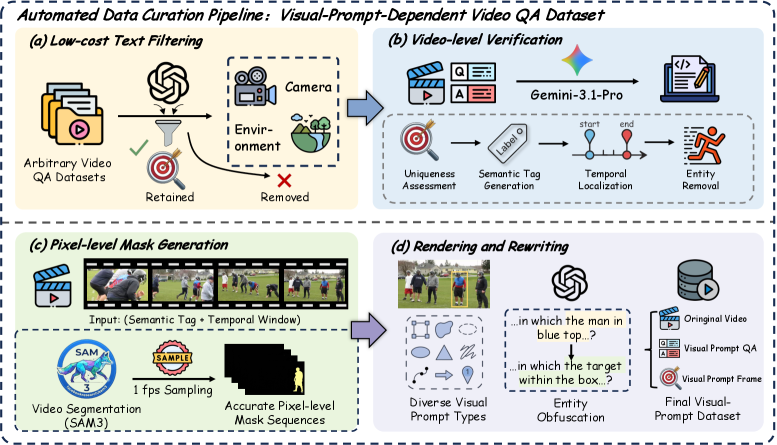
Figure 2 — 데이터 자동 생성 파이프라인
4. Conclusion & Impact (결론 및 시사점)
본 연구는 비디오 이해 분야에서 에이전트 기반의 능동적 도구 호출 패러다임을 도입하여 인스턴스 수준의 이해도를 획기적으로 개선하였다. 제안된 VideoSeeker는 텍스트 위주의 제한적인 상호작용에서 벗어나, 시각적 프롬프트를 통한 정밀한 시공간적 참조를 가능하게 함으로써 모델의 추론 능력을 극대화하였다. 이 연구는 대규모 자동 데이터 생성 파이프라인과 강화학습 전략을 결합하여, 향후 더 복잡하고 긴 비디오 환경에서의 범용적인 멀티모달 에이전트 개발을 위한 중요한 방법론적 토대를 마련하였다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] CODA: Coordinating the Cerebrum and Cerebellum for a Dual-Brain Computer Use Agent with Decoupled Reinforcement Learning
- [논문리뷰] Single-Rollout Asynchronous Optimization for Agentic Reinforcement Learning
- [논문리뷰] Scaling Mixture-of-Experts Video Pretraining for Embodied Intelligence
- [논문리뷰] TurnOPD: Making On-Policy Distillation Turn-Aware for Efficient Long-Horizon Agent Training
- [논문리뷰] TREK: Distill to Explore, Reinforce to Refine
Review 의 다른글
- 이전글 [논문리뷰] Targeted Neuron Modulation via Contrastive Pair Search
- 현재글 : [논문리뷰] VideoSeeker: Incentivizing Instance-level Video Understanding via Native Agentic Tool Invocation
- 다음글 [논문리뷰] Where Should Diffusion Enter a Language Model? Geometry-Guided Hidden-State Replacement
댓글