[논문리뷰] KVPO: ODE-Native GRPO for Autoregressive Video Alignment via KV Semantic Exploration
링크: 논문 PDF로 바로 열기
저자: Ruicheng Zhang, Kaixi Cong, Jun Zhou, Zhizhou Zhong, Zunnan Xu, Shuiyang Mao, Wei Liu, Xiu Li
1. Key Terms & Definitions (핵심 용어 및 정의)
- KVPO (KV-Semantic Policy Optimization): Streaming AR 비디오 생성 모델의 정렬(alignment)을 위해 제안된 ODE-native online GRPO 프레임워크입니다.
- CHR (Causal History Routing): 무작위 노이즈 주입 대신, historical KV cache를 재구성하여 semantically 다양한 생성 브랜치를 생성하는 방법론입니다.
- TVE (Trajectory Velocity Energy): Flow-matching velocity-field 공간에서 각 생성 브랜치의 우도(likelihood)를 측정하기 위해 정의된 에너지 지표입니다.
- Streaming AR Video Generation: 과거 프레임과 KV cache를 조건으로 하여 실시간으로 비디오 블록을 생성하는 인퍼런스 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존의 비디오 생성 모델 정렬 기법들은 주로 노이즈 기반의 탐색(exploration)이나 SDE 기반의 surrogate policy를 사용하여, 결정론적(deterministic) ODEdynamics로 작동하는 distilled AR 모델의 특성과 상충하는 문제를 야기합니다 [Figure 1]. 기존의 노이즈 주입 방식은 주로 저수준의 appearance를 왜곡시키며, 모델의 근본적인 narrative coherence나 고수준의 semantic progression을 개선하는 데 한계를 보입니다. 또한, 기존의 NeighborGRPO와 같은 ODE 기반 정렬 방식은 latent 공간의 Euclidean 거리에 의존하여, 비대칭적인 비디오 생성 공간의 확률적 분포를 온전히 반영하지 못한다는 단점이 있습니다. 본 논문은 이러한 한계를 극복하기 위해 flow-matching velocity-field 내에서 작동하는 ODE-native 정렬 프레임워크인 KVPO를 제안합니다.

Figure 1 — 노이즈 vs 의미론적 탐색 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 KVPO를 통해 causal-semantic 탐색과 velocity-field 기반의 surrogate policy를 도입하여 효율적인 비디오 정렬을 수행합니다. CHR은 historcial KV cache를 stochastically 라우팅하여 데이터 매니폴드 위에서 의미적으로 다양한 브랜치를 생성하며, 이를 통해 고수준의 storyline progression을 보장합니다 [Figure 1]. 생성된 브랜치들은 TVE를 사용하여 언퍼터브(unperturbed) 환경에서의 생성 우도를 평가받으며, 이는 PPO 알고리즘이 contrasteive flow-matching objective를 통해 최적화를 수행할 수 있도록 합니다 [Figure 2]. 실험 결과, KVPO는 LongLive 및 MemFlow 모델에서 성능 향상을 입증하였습니다. 특히, 멀티 프롬프트 기반의 긴 비디오 생성 설정에서 LongLive 모델은 베이스라인 대비 VQ 성능이 28.4%, MQ가 6.4%, TA가 26.3% 개선되었습니다 [Table 1]. 이러한 정량적 성과는 비디오의 시각적 품질, 동작의 자연스러움, 그리고 텍스트와의 정렬 정도에서 우위를 점하며 [Figure 3, Figure 4], 휴먼 평가에서도 압도적인 선호도를 기록했습니다 [Figure 5].
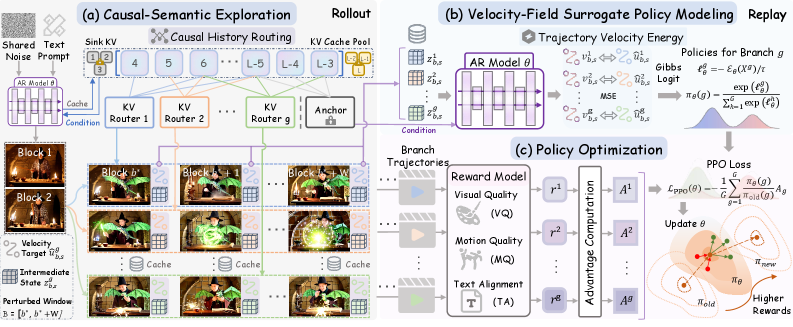
Figure 2 — KVPO 학습 파이프라인 개요
4. Conclusion & Impact (결론 및 시사점)
본 논문은 결정론적 ODE 환경에서의 AR 비디오 모델 정렬을 위한 KVPO 프레임워크를 정립하였습니다. 제안된 CHR과 TVE 기반의 surrogate policy는 모델의 native flow-matching dynamics를 보존하면서도 효과적으로 인간 선호도를 모델에 반영할 수 있음을 보여줍니다. 이 연구는 향후 ODE 기반의 생성 아키텍처 및 post-training alignment 연구에 있어 노이즈 기반 탐색을 대체할 수 있는 중요한 semantic-space 탐색의 시사점을 제공합니다.

Figure 3 — LongLive 성능 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] TREK: Distill to Explore, Reinforce to Refine
- [논문리뷰] The Mirage of Optimizing Training Policies: Monotonic Inference Policies as the Real Objective for LLM Reinforcement Learning
- [논문리뷰] Optimizing Visual Generative Models via Distribution-wise Rewards
- [논문리뷰] GD^2PO: Mitigating Multi-Reward Conflicts via Group-Dynamic reward-Decoupled Policy Optimization
- [논문리뷰] N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
Review 의 다른글
- 이전글 [논문리뷰] Incantation: Natural Language as the Action Interface for Multi-Entity Video World Models
- 현재글 : [논문리뷰] KVPO: ODE-Native GRPO for Autoregressive Video Alignment via KV Semantic Exploration
- 다음글 [논문리뷰] Lance: Unified Multimodal Modeling by Multi-Task Synergy
댓글