[논문리뷰] Flow-OPD: On-Policy Distillation for Flow Matching Models
링크: 논문 PDF로 바로 열기
메타데이터
저자: Zhen Fang, Wenxuan Huang, Yu Zeng, Yiming Zhao, Shuang Chen, Kaituo Feng, Yunlong Lin, Lin Chen, Zehui Chen, Shaosheng Cao, Feng Zhao
1. Key Terms & Definitions (핵심 용어 및 정의)
- Flow Matching (FM): 연속 시간(continuous-time) 속도장(velocity field)을 학습하여 잡음 분포를 데이터 분포로 매핑하는 생성 모델링 패러다임입니다.
- On-Policy Distillation (OPD): 학생 모델이 생성한 실시간 궤적(trajectory)을 바탕으로, 교사 모델의 지도(supervision)를 통해 학생의 정책을 정교화하는 지식 증류 기법입니다.
- GRPO (Group Relative Policy Optimization): 여러 개의 출력물을 샘플링하여 그룹 내 상대적 이득(advantage)을 계산하고 정책을 업데이트하는 RL 알고리즘입니다.
- Manifold Anchor Regularization (MAR): 생성 과정을 고품질 매니폴드에 고정하여, 기능적 정렬 과정에서 발생할 수 있는 미적 품질 저하를 방지하는 정규화 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Flow Matching 모델의 다중 작업 정렬(multi-task alignment) 과정에서 발생하는 보상 희소성(reward sparsity)과 기울기 간섭(gradient interference) 문제를 해결하고자 합니다. 기존의 단일 보상 기반 GRPO 방식은 특정 메트릭을 최적화할 때 다른 능력이 퇴보하는 "시소 효과(seesaw effect)"를 유발하며, 이는 보상의 파편화와 무질서한 파라미터 업데이트에서 기인합니다 [Figure 2]. 단순한 보상 혼합 방식 또한 최적화 과정에서 파라미터 충돌을 일으켜 다중 도메인 성능을 동시에 달성하지 못하는 한계가 있습니다. 따라서 기능적 전문성을 유지하면서도 교사 모델들의 지식을 통합할 수 있는 새로운 다중 작업 학습 프레임워크가 절실히 요구됩니다.
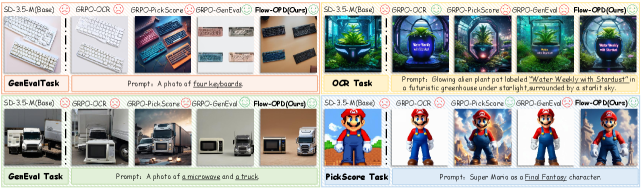
Figure 2 — 단일 보상 GRPO의 교차 작업 평가
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Flow-OPD를 제안하여, 도메인별 전문가 모델을 개별 학습시킨 후 On-Policy Distillation을 통해 학생 모델로 지식을 통합하는 2단계 정렬 전략을 수립합니다. 먼저 Cold Start 기법(SFT 또는 Model Merging)으로 초기 정책을 설정하고, 실시간 샘플링된 궤적을 전문가 교사 모델들에 라우팅하여 밀도 높은(dense) 지도 신호를 제공합니다. 이 과정에서 MAR를 적용해 작업 불가지론적(task-agnostic) 교사 모델로부터 전체적인 생성 품질을 유지하도록 강제합니다. 실험 결과, Flow-OPD는 Stable Diffusion 3.5 Medium 기반에서 GenEval 점수를 63에서 92로, OCR 정확도를 59에서 94로 크게 향상시켰습니다 [Table 2]. 이는 기존 GRPO baseline 대비 약 10포인트 높은 성능 개선치이며, 정성적으로도 교사 모델의 성능을 상회하는 "teacher-surpassing" 효과를 입증했습니다 [Figure 1], [Figure 3].
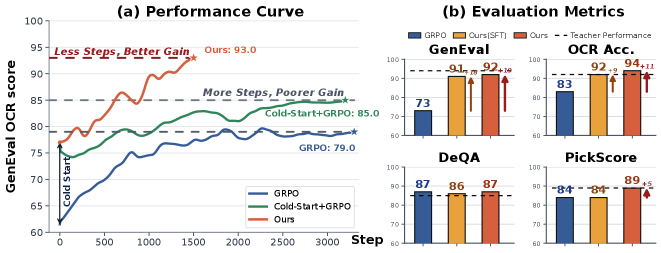
Figure 1 — 다중 작업 학습 성능 비교

Figure 3 — Flow-OPD 정성적 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Flow-OPD를 통해 Flow Matching 모델에 On-Policy Distillation을 성공적으로 도입함으로써, 보상 파편화와 기울기 간섭이라는 고질적인 다중 작업 정렬 문제를 해결했습니다. 특히 궤적 단위의 밀도 높은 supervision과 MAR를 통한 미적 품질 보호는 일반화된 생성 모델을 구축하기 위한 확장 가능한 패러다임을 제시합니다. 본 연구는 향후 고품질 다중 도메인 생성 AI 모델의 효율적인 훈련과 최적화에 중요한 기술적 토대를 마련할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] TempFlow-GRPO: When Timing Matters for GRPO in Flow Models
- [논문리뷰] TurnOPD: Making On-Policy Distillation Turn-Aware for Efficient Long-Horizon Agent Training
- [논문리뷰] Optimizing Visual Generative Models via Distribution-wise Rewards
- [논문리뷰] DanceOPD: On-Policy Generative Field Distillation
- [논문리뷰] Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
Review 의 다른글
- 이전글 [논문리뷰] Fast Byte Latent Transformer
- 현재글 : [논문리뷰] Flow-OPD: On-Policy Distillation for Flow Matching Models
- 다음글 [논문리뷰] From Storage to Experience: A Survey on the Evolution of LLM Agent Memory Mechanisms
댓글