[논문리뷰] HyperEyes: Dual-Grained Efficiency-Aware Reinforcement Learning for Parallel Multimodal Search Agents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Guankai Li, Jiabin Chen, Yi Xu, Xichen Zhang, Yuan Lu
1. Key Terms & Definitions (핵심 용어 및 정의)
- Unified Grounded Search (UGS): 시각적 grounding(좌표 예측)과 외부 검색(retrieval)을 단일 원자적 액션으로 통합하여, 여러 엔티티에 대한 검색을 하나의 턴에서 병렬로 수행하는 방법론입니다.
- TRACE (Tool-use Reference-Adaptive Cost Efficiency): 훈련 중에 점진적으로 강화되는 효율성 레퍼런스를 통해, 에이전트의 툴 호출 횟수를 억제하고 최적의 효율성을 유도하는 보상 메커니즘입니다.
- On-Policy Distillation (OPD): 실패한 롤아웃(failed rollouts)에 대해 더 강력한 모델로부터 토큰 단위의 corrective signal을 주입하여 에이전트의 추론 정확도를 높이는 학습 기법입니다.
- IMEB (Image Multi-Entity Benchmark): 다중 엔티티 시각적 질문에 대해 정확도뿐만 아니라 툴 호출 효율성을 공동으로 평가하기 위해 구축된 300개의 인간 큐레이팅 데이터셋입니다.
- CAS (Cost-Aware Score): 정확도와 연산 효율성(툴 호출 라운드 및 토큰 소비량)을 결합하여 에이전트의 전반적인 성과를 종합 평가하는 핵심 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 Multimodal search agents가 다중 엔티티 검색 시 직면하는 비효율적인 순차적(sequential) 툴 호출 문제를 해결하기 위해 제안되었다. 기존 모델들은 쿼리를 분해할 수 있음에도 불구하고, 엔티티를 하나씩 처리하는 verbose한 방식 때문에 중복적인 상호작용 라운드가 발생하여 불필요한 지연시간과 노이즈를 야기한다. 이는 단순히 정확도 보상만을 최적화하기 때문에 발생하는 문제로, 연구자들은 에이전트가 "더 길게(longer)"가 아닌 "더 넓게(wider)" 검색할 수 있는 새로운 패러다임이 필요하다고 판단하였다 [Figure 1].
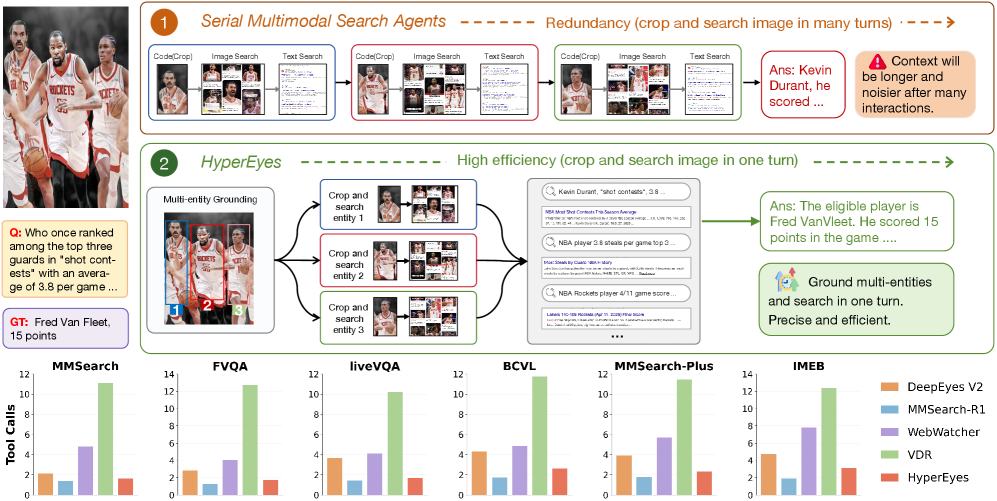
Figure 1 — 기존 에이전트와 HyperEyes 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 HyperEyes라는 효율성 중심의 병렬 멀티모달 검색 에이전트를 제안하며, 이는 2단계 훈련 프레임워크를 통해 최적화된다 [Figure 2]. 첫째, Parallel-Amenable Data Synthesis Pipeline을 통해 고품질의 효율성 중심 cold-start trajectory를 확보한다. 둘째, Dual-Grained Efficiency-Aware Reinforcement Learning 프레임워크를 통해 매크로 수준에서는 TRACE 보상으로 효율적인 툴 사용을 유도하고, 마이크로 수준에서는 OPD를 통해 토큰 단위의 정밀한 교정 신호를 주입한다. 주요 실험 결과, HyperEyes-30B는 비교 가능한 규모의 최신 오픈소스 에이전트 대비 9.9% 향상된 정확도를 기록하면서도 툴 호출 라운드는 5.3배 감소시키는 압도적 성능 우위를 입증하였다. 또한, IMEB 벤치마크상에서 제안한 CAS 지표를 기준으로 기존 경쟁 모델들보다 월등히 높은 효율성 점수를 달성하였다 [Table 3].
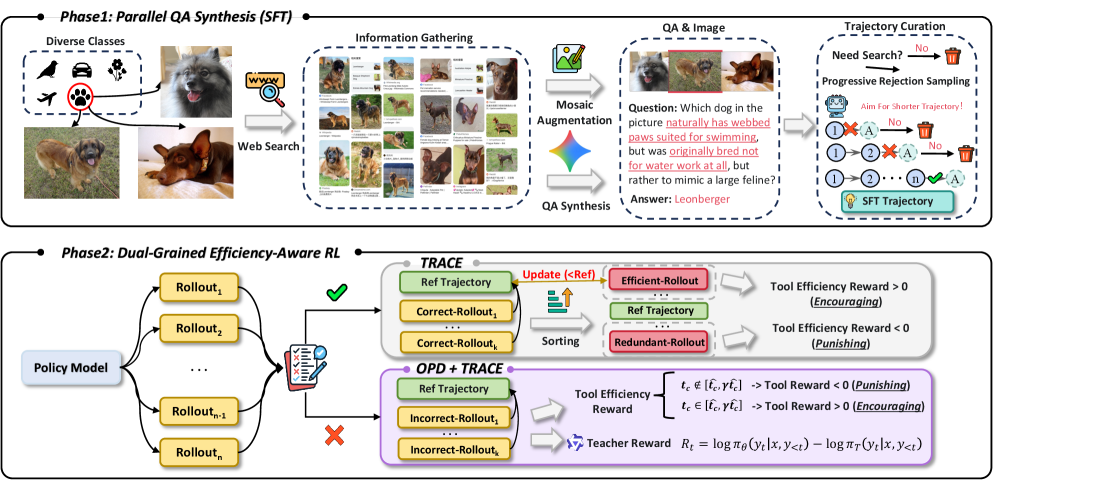
Figure 2 — HyperEyes 학습 프레임워크 개요
4. Conclusion & Impact (결론 및 시사점)
본 연구는 다중 엔티티 검색 환경에서 효율성과 정확도가 서로 상충되는 관계가 아니라 공동 최적화될 수 있음을 증명하였다. 제안된 HyperEyes와 IMEB 벤치마크는 에이전트의 검색 효율성을 학계와 산업계에서 핵심 평가 지표로 격상시키는 데 기여하였다. 향후 본 연구는 실시간 grounded 멀티모달 QA 시스템의 구축을 촉진하고, 연산 자원이 제한된 환경에서도 고성능 에이전트 서비스를 가능케 하는 표준적인 접근 방식을 제시할 것으로 기대된다.
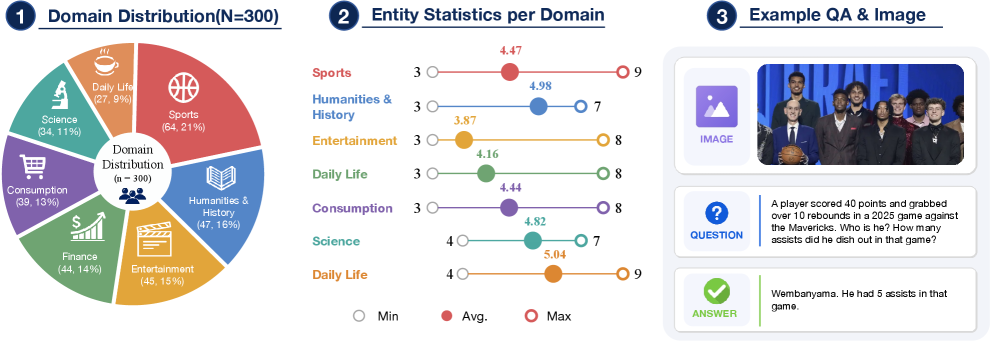
Figure 3 — IMEB 벤치마크 구조 및 통계
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] TurnOPD: Making On-Policy Distillation Turn-Aware for Efficient Long-Horizon Agent Training
- [논문리뷰] Flow-OPD: On-Policy Distillation for Flow Matching Models
- [논문리뷰] Healthcare AI GYM for Medical Agents
- [논문리뷰] Beyond SFT-to-RL: Pre-alignment via Black-Box On-Policy Distillation for Multimodal RL
- [논문리뷰] A Survey of On-Policy Distillation for Large Language Models
Review 의 다른글
- 이전글 [논문리뷰] Gated QKAN-FWP: Scalable Quantum-inspired Sequence Learning
- 현재글 : [논문리뷰] HyperEyes: Dual-Grained Efficiency-Aware Reinforcement Learning for Parallel Multimodal Search Agents
- 다음글 [논문리뷰] IntentGrasp: A Comprehensive Benchmark for Intent Understanding
댓글