[논문리뷰] IntentGrasp: A Comprehensive Benchmark for Intent Understanding
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yuwei Yin, Chuyuan Li, Giuseppe Carenini, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- IntentGrasp: LLM의 의도 이해(Intent Understanding) 능력을 평가하기 위해 49개의 오픈 데이터셋을 통합하여 구축한 포괄적인 벤치마크입니다.
- Gem Set: IntentGrasp의 평가 셋 중 하나로, 기존 Frontier LLM들이 대다수 실패한 사례들을 추출하여 도메인별로 균형을 맞춘 고난도 평가 셋입니다.
- IFT (Intentional Fine-Tuning): IntentGrasp의 대규모 훈련 데이터를 사용하여 모델의 의도 이해 능력을 직접적으로 향상시키는 지도 미세 조정(Supervised Fine-Tuning) 방법론입니다.
- Lodo (Leave-one-domain-out): 특정 도메인을 훈련 과정에서 제외하고 나머지 도메인만으로 학습한 후, 제외했던 도메인에서의 일반화 성능을 검증하는 실험 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현재 LLM 생태계에서 사용자 의도를 정확히 파악하는 능력이 체계적으로 평가되지 않고 있다는 문제 의식에서 출발합니다. 기존 의도 분류(Intent Classification) 데이터셋들은 특정 도메인에 국한되어 있고 데이터 구조가 파편화되어 있으며, 레이블 또한 모호하여 LLM의 범용적인 의도 이해 능력을 측정하는 데 한계가 있습니다. 이러한 파편화된 리소스는 LLM이 의료, 금융, 법률 등 고위험군 도메인에서 잘못된 판단을 내리거나 악의적인 사용자 의도를 걸러내지 못하는 위험을 초래할 수 있습니다. 이를 해결하기 위해 저자들은 12개 도메인을 아우르는 통합된 벤치마크를 구축하고, 모델의 의도 이해 역량을 표준화하여 측정하고자 합니다 [Figure 1].

Figure 1 — IntentGrasp 구축 3단계
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 소스 데이터셋 큐레이션, 의도 레이블의 문맥화(Contextualization), 그리고 의도 이해를 위한 다중 선택 QA 포맷으로의 통합 과정을 통해 IntentGrasp를 구축하였습니다 [Figure 1]. 이 벤치마크는 262,759개의 학습 인스턴스와 12,909개의 All Set, 470개의 Gem Set 평가 셋으로 구성됩니다. 7개 패밀리, 20개의 Frontier LLM을 대상으로 평가한 결과, 모든 모델이 All Set에서 F1 Score 60% 미만, Gem Set에서 25% 미만의 저조한 성능을 보였으며, 17개 모델은 랜덤 추측 성능(15.2%)보다 낮은 결과를 기록했습니다 [Figure 2]. 이에 대한 해결책으로 제안된 IFT는 Qwen3 모델 기반 미세 조정을 통해 All Set에서 30점 이상의 F1 Score 향상과 Gem Set에서 20점 이상의 성능 향상을 달성하였습니다. 특히 Lodo 실험 결과, IFT는 훈련되지 않은 미지의 도메인에 대해서도 강력한 교차 도메인 일반화(Cross-domain Generalizability)를 입증하였습니다 [Figure 5].
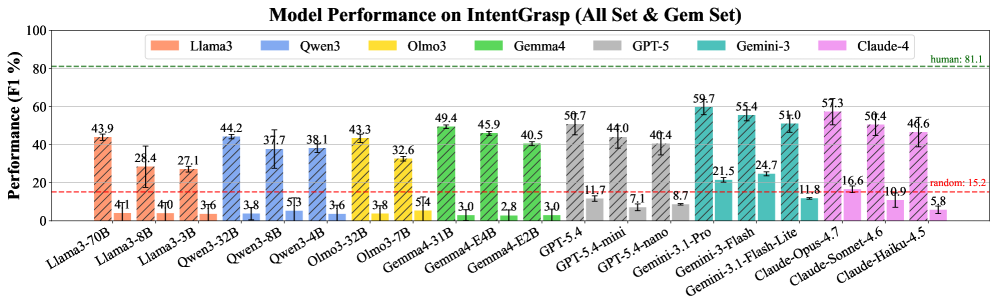
Figure 2 — LLM 모델 성능 비교
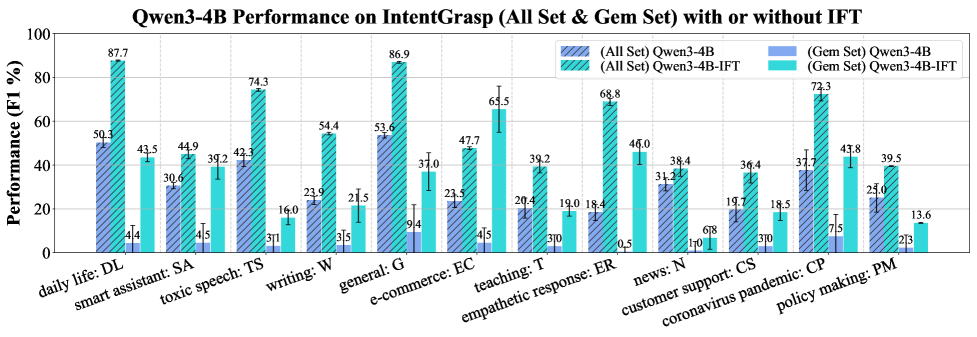
Figure 5 — IFT 도메인별 성능 향상
4. Conclusion & Impact (결론 및 시사점)
본 논문은 의도 이해를 위한 표준화된 평가 프레임워크인 IntentGrasp를 제시함으로써, LLM의 intentionality를 정량적으로 측정할 수 있는 토대를 마련했습니다. 실험 결과는 현존하는 SOTA 모델들조차 복잡한 의도 파악에 상당한 취약점을 가지고 있음을 시사하며, 제안된 IFT는 이러한 한계를 극복할 수 있는 실질적인 개선 방향을 제공합니다. 이 연구는 앞으로 더욱 안전하고 신뢰할 수 있는 AI 비서를 개발하는 데 있어 의도 이해 능력이 핵심적인 기술 지표로 자리매김하는 데 기여할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LoSoNA: A Benchmark for Local Social Norm Adaptation in Group Conversations
- [논문리뷰] HRBench: Benchmarking and Understanding Thinking-Mode Switch Strategies in Hybrid-Reasoning LLMs
- [논문리뷰] DeepResearchEval: An Automated Framework for Deep Research Task Construction and Agentic Evaluation
- [논문리뷰] AthenaBench: A Dynamic Benchmark for Evaluating LLMs in Cyber Threat Intelligence
- [논문리뷰] AutoIntent: AutoML for Text Classification
Review 의 다른글
- 이전글 [논문리뷰] HyperEyes: Dual-Grained Efficiency-Aware Reinforcement Learning for Parallel Multimodal Search Agents
- 현재글 : [논문리뷰] IntentGrasp: A Comprehensive Benchmark for Intent Understanding
- 다음글 [논문리뷰] InterLV-Search: Benchmarking Interleaved Multimodal Agentic Search
댓글