[논문리뷰] Healthcare AI GYM for Medical Agents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Minbyul Jeong
1. Key Terms & Definitions (핵심 용어 및 정의)
- Healthcare AI GYM: 10개의 임상 도메인과 135개의 특화 툴을 갖춘 의료 에이전트 전용 강화학습 환경입니다.
- TT-OPD (Turn-level Truncated On-Policy Distillation): 에이전트의 턴 단위 학습 안정성을 높이기 위해 EMA(Exponential Moving Average) 기반 티처 모델이 결과 기반의 힌트를 제공하는 자기 증류(self-distillation) 프레임워크입니다.
- GRPO (Group Relative Policy Optimization): 학습된 가치 함수 대신 그룹 내 상대적 보상을 사용하여 에이전트의 정책을 최적화하는 강화학습 알고리즘입니다.
- Agentic-Textual Transfer Gap: 강화학습을 통해 에이전트의 절차적 능력은 향상되지만, 이 과정에서 포맷 보상의 희석(format-reward dilution) 등으로 인해 텍스트 기반 QA 벤치마크 성능은 오히려 저하되는 현상을 지칭합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 의료 AI 에이전트가 복잡한 다단계 임상 추론 환경에서 안정적인 툴 사용 정책을 학습하는 데 한계가 있다는 문제를 해결하고자 합니다. 기존의 단일 턴(single-turn) 기반 의료 QA 연구들은 실제 임상 환경의 핵심인 다단계 상호작용과 툴 활용 능력을 충분히 반영하지 못합니다. 더구나 의료 에이전트를 다단계 강화학습으로 학습시킬 경우 '응답 폭발(response explosion)', '다중 턴 붕괴(multi-turn collapse)', '증류 불안정성(distillation instability)'이라는 세 가지 병리적 현상이 발생합니다. 특히 기존의 GRPO는 에이전트의 다단계 궤적 전체에 희소한(sparse) 보상을 할당하여 학습 안정성을 크게 저해합니다 [Figure 1].
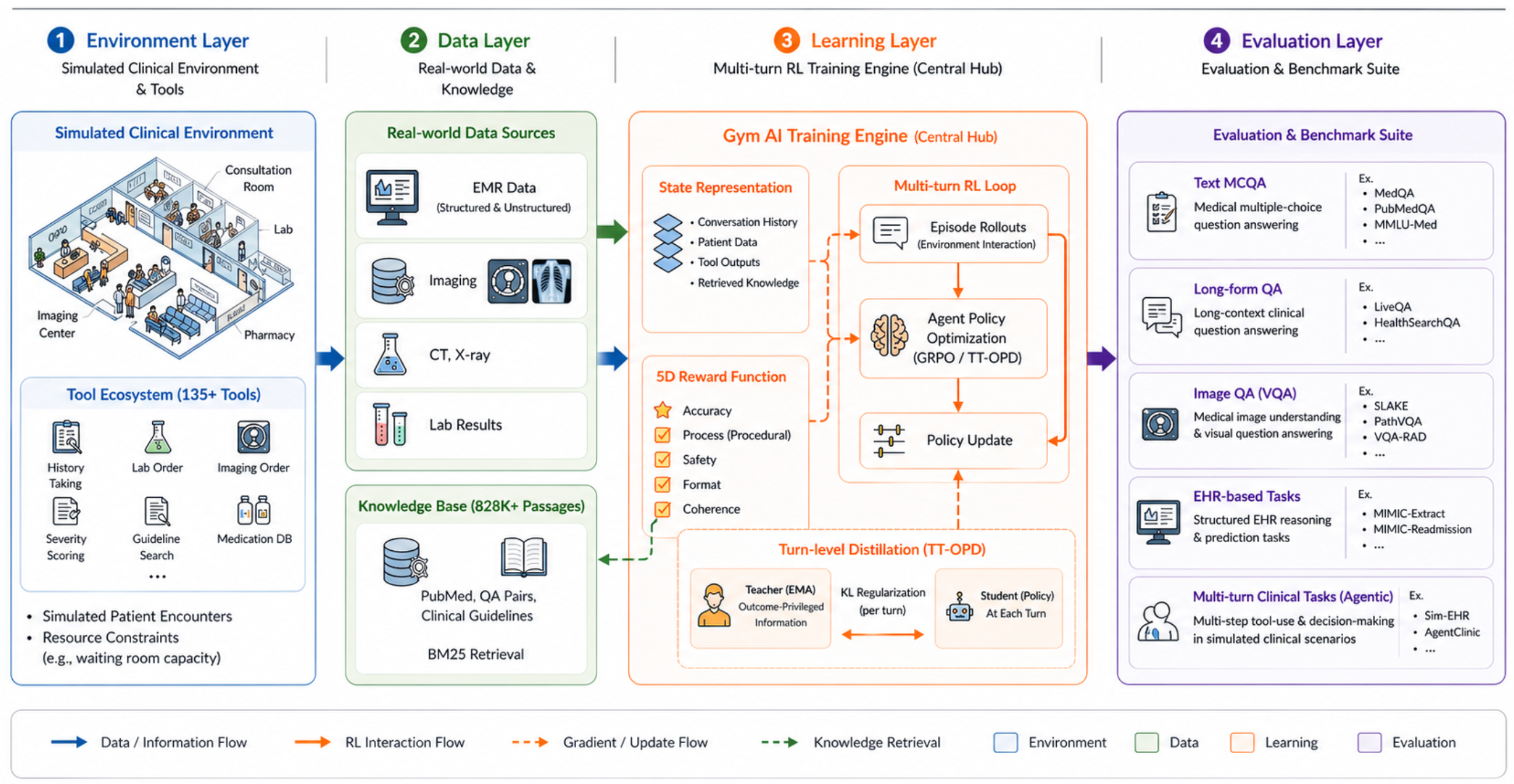
Figure 1 — Healthcare AI GYM 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 학습 효율성과 안정성을 높이기 위해 TT-OPD 방법론을 제안합니다. 이 방법론은 Gradient-free EMA 티처 모델을 활용하여 매 conversation 턴마다 결과 기반의 privileged 힌트를 통해 KL 규제(regularization)를 제공하고, 코사인 기반 길이 제어 보상(cosine length-controlled reward)을 도입하여 응답의 무분별한 길이 증가를 억제합니다 [Figure 2]. 주요 실험 결과, TT-OPD는 18개의 벤치마크 중 10개에서 최고의 성능을 달성하였습니다. 구체적으로 MedQA에서 87.1%(비 RL 베이스라인 대비 +16.4 pp), MedMCQA에서 66.2%의 정확도를 기록하며 기존 방법론 대비 우수한 임상 추론 능력을 입증했습니다. 또한 TT-OPD는 학습 과정에서 7.07.4 턴 수준의 일관된 다중 턴 툴 사용을 유지하며, 5.7K9.3K 토큰 범위의 제어된 응답 길이를 확보하여 GRPO baseline의 응답 길이 진동 현상을 해결하였습니다 [Figure 3].
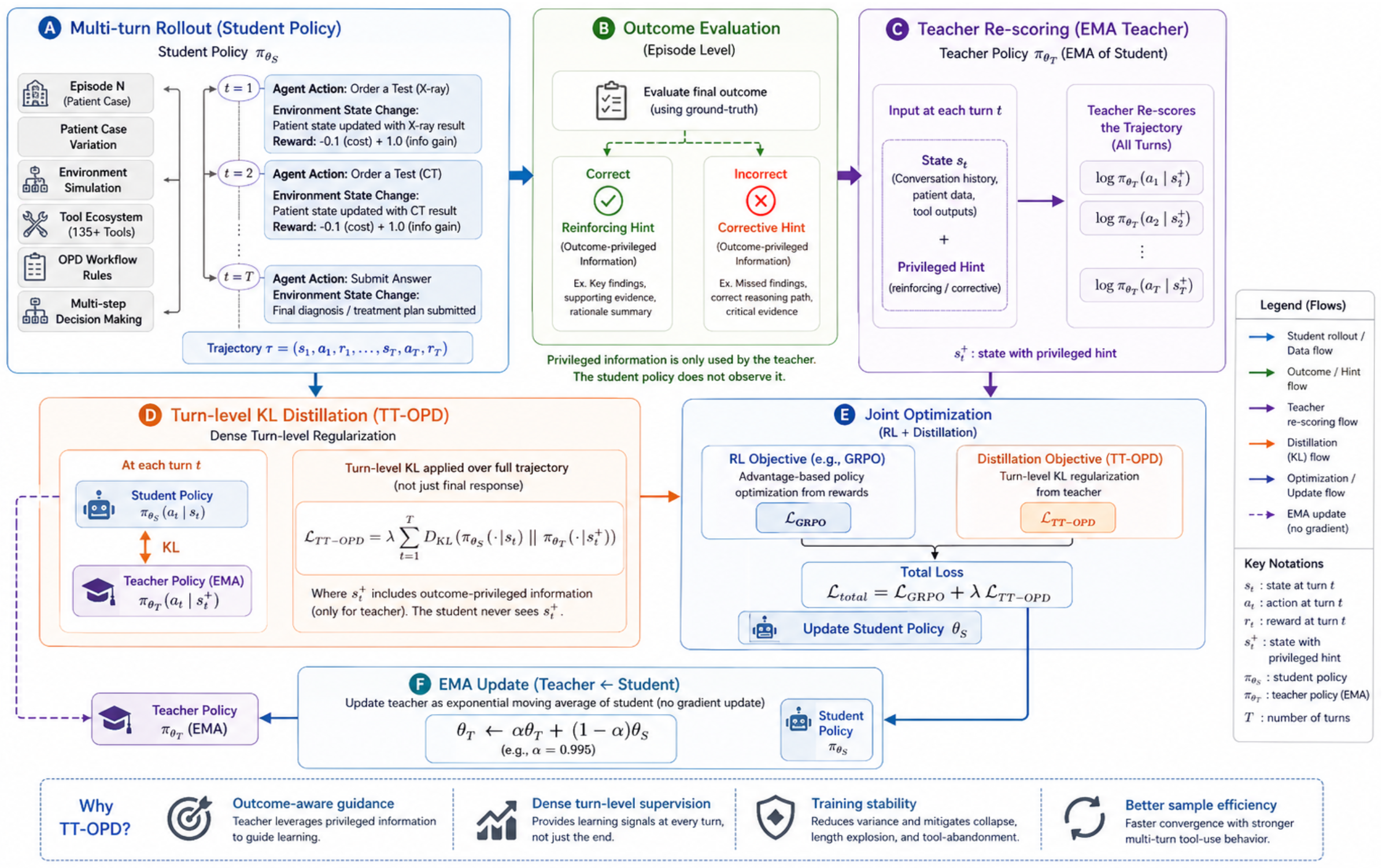
Figure 2 — TT-OPD 학습 구조
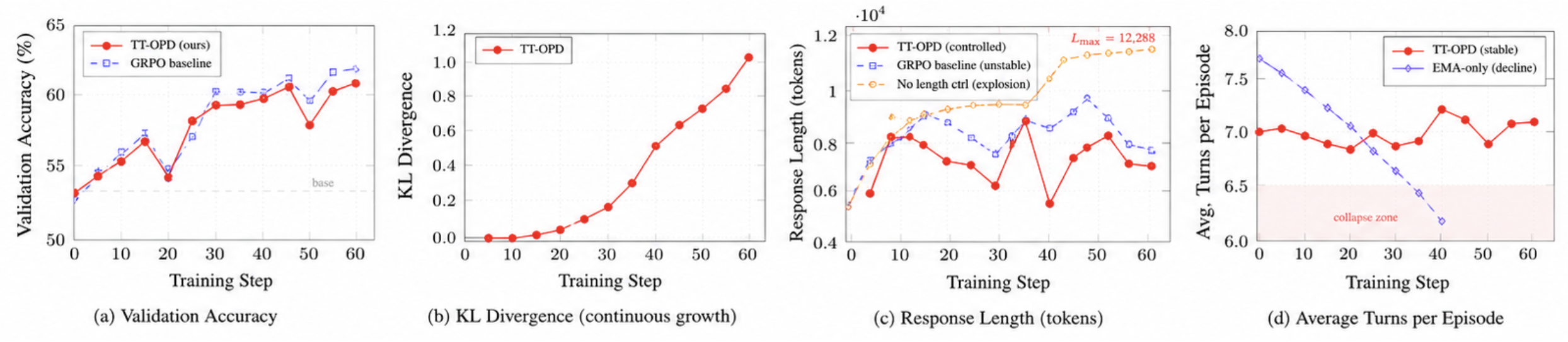
Figure 3 — TT-OPD 학습 동적 분석
4. Conclusion & Impact (결론 및 시사점)
본 연구는 의료 AI 에이전트의 학습 과정에서 발생하는 에이전트 고유의 붕괴 현상을 규명하고 이를 해결하기 위한 TT-OPD 프레임워크를 성공적으로 구축하였습니다. 이 연구는 강화학습이 절차적 임상 업무에는 효과적이지만 텍스트 QA 성능과는 Trade-off 관계가 있다는 '에이전트-텍스트 전이 간극'을 학계에 처음으로 체계적으로 제시하였습니다. 개발된 Healthcare AI GYM 환경과 학습 파이프라인은 오픈소스로 공개되어, 향후 의료 안전성과 전문성을 갖춘 일반화 가능한 의료 에이전트 연구의 표준화된 기반이 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] TurnOPD: Making On-Policy Distillation Turn-Aware for Efficient Long-Horizon Agent Training
- [논문리뷰] HyperEyes: Dual-Grained Efficiency-Aware Reinforcement Learning for Parallel Multimodal Search Agents
- [논문리뷰] Flow-OPD: On-Policy Distillation for Flow Matching Models
- [논문리뷰] Beyond SFT-to-RL: Pre-alignment via Black-Box On-Policy Distillation for Multimodal RL
- [논문리뷰] A Survey of On-Policy Distillation for Large Language Models
Review 의 다른글
- 이전글 [논문리뷰] ESARBench: A Benchmark for Agentic UAV Embodied Search and Rescue
- 현재글 : [논문리뷰] Healthcare AI GYM for Medical Agents
- 다음글 [논문리뷰] HeavySkill: Heavy Thinking as the Inner Skill in Agentic Harness
댓글