[논문리뷰] HeavySkill: Heavy Thinking as the Inner Skill in Agentic Harness
링크: 논문 PDF로 바로 열기
메타데이터
저자: Jianing Wang, Linsen Guo, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Agentic Harness: 여러 서브 에이전트, 메모리, 스킬, 도구 사용을 통합하여 복잡한 추론 작업을 수행하도록 모델을 조정하는 오케스트레이션 프레임워크입니다.
- Heavy Thinking: 문제 해결을 위해 대규모의 병렬 추론과 이후의 순차적 숙고(Sequential Deliberation) 단계를 거치는 추론 과정으로, LLM의 내재적 기술(Inner Skill)로 간주합니다.
- Sequential Deliberation: 병렬로 생성된 여러 추론 궤적(Reasoning Trajectories)을 입력으로 받아 이를 종합하고 재추론하여 최종 답변을 도출하는 2단계 추론 방식입니다.
- Serialized Memory Cache: 병렬 추론 단계에서 생성된 여러 궤적들을 프롬프트 문맥에 맞게 직렬화하여 순차적 숙고 단계의 입력으로 전달하는 메커니즘입니다.
- RLVR (Reinforcement Learning from Verifiable Rewards): 결과 기반의 자동 검증 가능한 보상 신호를 사용하여 모델의 추론 능력 및 전략을 최적화하는 학습 방식입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 복잡한 Agentic Harness 설계 이면에 숨겨진 실질적인 성능 구동 메커니즘을 규명하고 이를 단순화하고자 한다. 기존의 오케스트레이션 설계는 시스템이 매우 복잡하여 실질적인 추론 메커니즘을 파악하기 어렵다는 한계가 있었다. 저자들은 이를 '병렬 추론'과 '요약(숙고)'이라는 두 단계의 워크플로우로 추상화하여, 복잡한 인프라 의존성 없이도 LLM의 내재적 능력으로 활용 가능한 HeavySkill 프레임워크를 제안한다 [Figure 1].
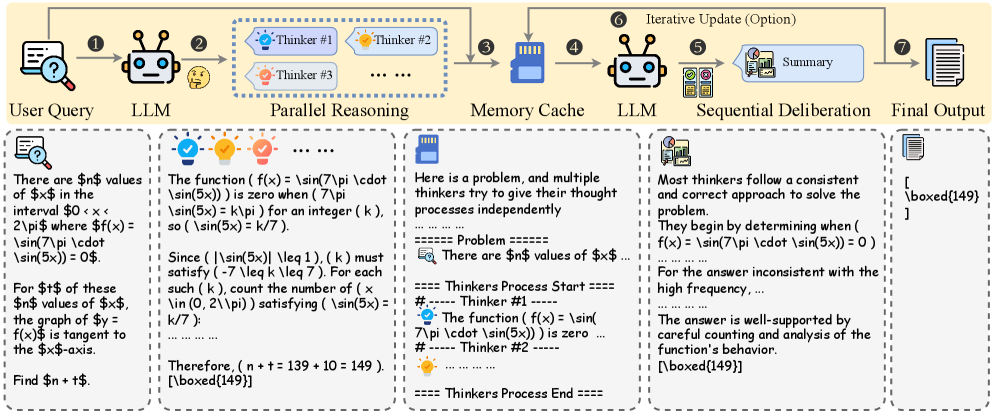
Figure 1 — Heavy Thinking 전체 프레임워크
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Heavy Thinking 과정을 병렬 추론 단계와 순차적 숙고 단계로 분리하고 이를 가독성 있는 Skill 형태로 캡슐화하여 어떠한 Harness에서도 즉시 적용 가능하도록 설계하였다. 첫 단계인 병렬 추론에서 독립적인 궤적을 생성하고, 이를 Serialized Memory Cache를 통해 전달받은 뒤, 숙고 모델이 이를 종합하여 최종 답변을 생성한다 [Figure 1]. 실험 결과, STEM 기반의 벤치마크(AIME25, GPQA-Diamond 등)에서 Heavy-Mean@4 (HM@4) 지표가 기존의 Best-of-N (BoN) 전략인 Majority Voting을 일관되게 상회함을 확인하였다. 또한, 모델의 내재적 추론 능력이 뛰어날 경우, Heavy-Pass@k가 해당 모델의 이론적 한계인 Pass@k를 돌파하는 현상을 확인하였다 [Table 1, Table 2]. 특히, RLVR을 적용한 학습 시 HM@4 성능이 약 10% 추가 향상되어 자가 진화하는 LLM으로의 확장 가능성을 입증하였다 [Figure 6].
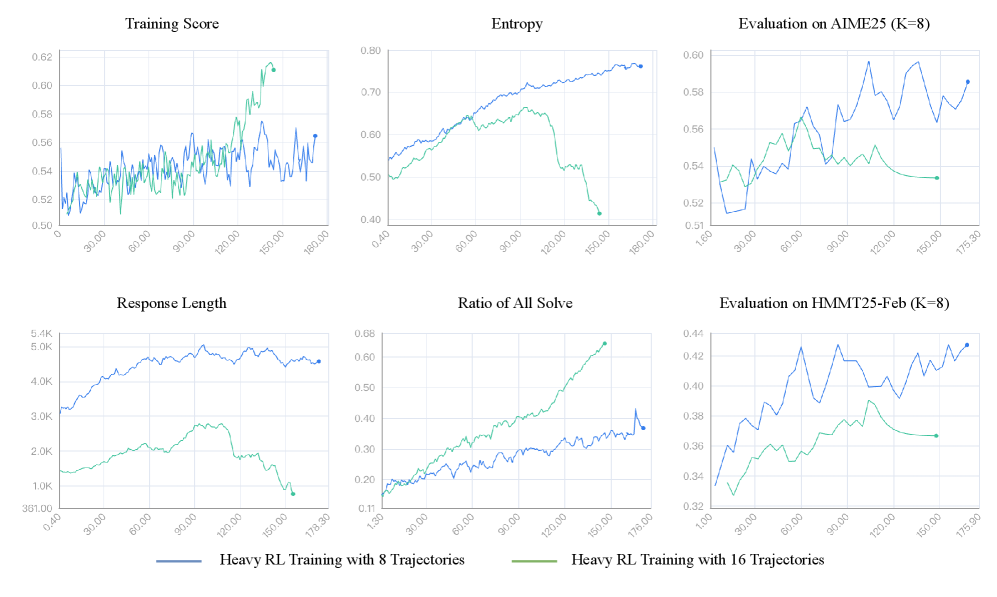
Figure 6 — RLVR 학습에 따른 성능 변화
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Heavy Thinking이 특정 시스템의 부산물이 아닌, LLM이 내재화할 수 있는 강력한 추론 기술임을 증명하고 이를 Readable Skill로 정형화하였다. 이 연구는 복잡한 오케스트레이션 계층에 대한 의존도를 낮추고, 추론 성능을 향상시키기 위해 모델의 파라미터 내부에 숙고 과정을 내재화하는 방향을 제시한다. 결과적으로 본 접근 방식은 학계와 산업계 전반에서 LLM의 Test-Time Scaling 전략을 보다 체계적이고 효율적으로 최적화하는 데 중요한 기여를 할 것으로 기대된다.
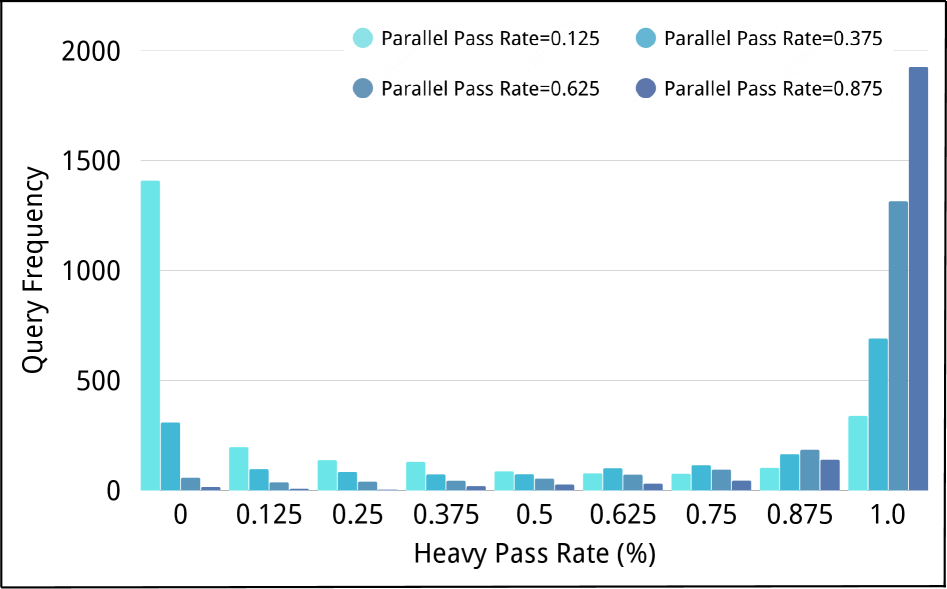
Figure 2 — 추론 패스율 분포 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Infinite Worlds with Versatile Interactions
- [논문리뷰] The Mirage of Optimizing Training Policies: Monotonic Inference Policies as the Real Objective for LLM Reinforcement Learning
- [논문리뷰] Transferability for General Reasoning: An Automated Curriculum for Multi-Domain RLVR
- [논문리뷰] DOPD: Dual On-policy Distillation
- [논문리뷰] AsyncOPD: How Stale Can On-Policy Distillation Be?
Review 의 다른글
- 이전글 [논문리뷰] Healthcare AI GYM for Medical Agents
- 현재글 : [논문리뷰] HeavySkill: Heavy Thinking as the Inner Skill in Agentic Harness
- 다음글 [논문리뷰] OpenSeeker-v2: Pushing the Limits of Search Agents with Informative and High-Difficulty Trajectories
댓글