[논문리뷰] OpenSeeker-v2: Pushing the Limits of Search Agents with Informative and High-Difficulty Trajectories
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yuwen Du, Rui Ye, Shuo Tang, Keduan Huang, Xinyu Zhu, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- ReAct: LLM이 추론 과정(Reasoning)과 도구 호출(Acting)을 반복하며 복잡한 문제를 해결하는 패러다임입니다.
- SFT (Supervised Fine-Tuning): 사전에 수집된 고품질의 Trajectory 데이터를 사용하여 모델을 지도 학습 방식으로 미세 조정하는 기법입니다.
- Deep Search: 모델이 웹 브라우징과 같은 도구를 사용하여 다단계 정보를 탐색하고, 복잡한 질문에 대해 답변을 생성하는 핵심 역량입니다.
- Trajectory: 모델이 도구 호출(Tool call), 관측(Observation), 추론(Reasoning)을 통해 최종 답변에 도달하기까지 거치는 일련의 실행 경로입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 고성능 search agent 개발이 자본과 컴퓨팅 자원이 막대한 기업 주도의 CPT+SFT+RL 파이프라인에 종속된 현실을 비판적으로 접근합니다. 기존의 복잡한 학습 방식은 학계의 진입 장벽을 높이고 연구 생태계의 폐쇄성을 야기합니다. 본 논문은 이러한 복잡한 다단계 학습 없이, 오직 고품질의 데이터 합성을 통한 SFT만으로 최첨단 성능을 달성할 수 있는지 검증하고자 합니다. [Figure 1]
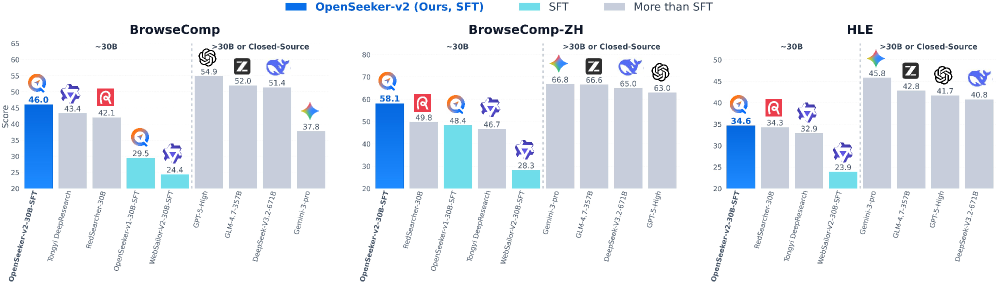
Figure 1 — 모델 성능 비교 요약
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 논문은 정보가 풍부하고 난도가 높은 Trajectory를 생성하는 세 가지 간단한 데이터 합성 기법을 제안합니다. 첫째, 지식 그래프(Knowledge Graph) 크기를 확장하여 다중 홉(Multi-hop) 탐색이 필수적인 복잡한 문맥을 구성합니다. 둘째, 가용 Tool set을 확장하여 모델의 도구 활용 다양성을 강화합니다. 셋째, Low-step filtering을 통해 도구 호출 단계가 적은 단순 질문을 필터링하여 최소한의 학습 난도를 보장합니다. [Figure 2] 이 방식을 통해 구축된 단 10.6k개의 데이터셋으로 학습된 OpenSeeker-v2-30B-SFT는 강력한 성능을 보여줍니다. 4개의 주요 벤치마크인 BrowseComp(46.0%), BrowseComp-ZH(58.1%), Humanity’s Last Exam(34.6%), xbench(78.0%)에서 SOTA 성능을 기록했습니다. 이는 Tongyi DeepResearch 등 복잡한 CPT+SFT+RL 파이프라인 기반 모델을 상회하는 수치이며, 순수 학계의 SFT 기반 모델이 산업계 모델을 능가할 수 있음을 입증합니다. [Table 1]
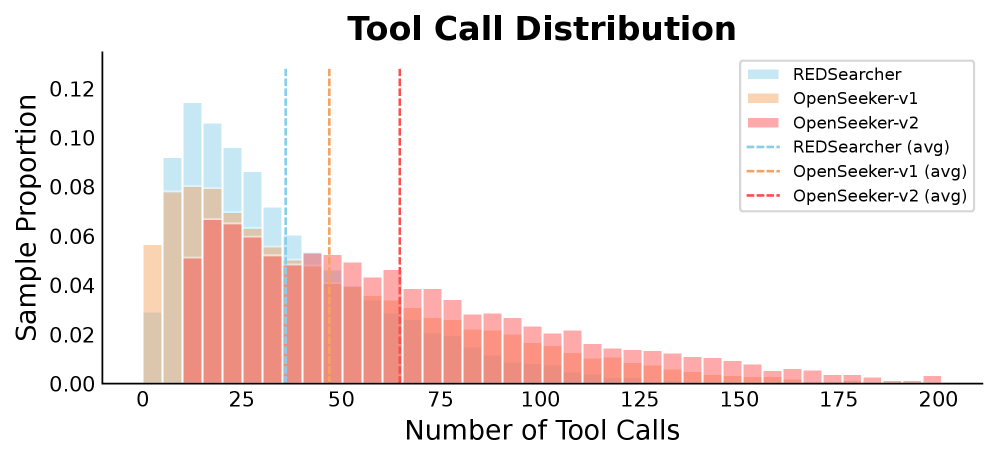
Figure 2 — 평균 도구 호출 단계 비교
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 데이터의 질과 난도가 search agent의 성능을 결정짓는 핵심 요소임을 강조하며, SFT 중심의 간소화된 학습 프레임워크를 제안합니다. 연구 결과는 학계에서도 제한된 자원으로 최첨단 검색 에이전트를 구축할 수 있는 길을 열어주며, 복잡한 multi-stage 파이프라인에 대한 재평가를 촉구합니다. 향후 본 연구의 방법론은 데이터 확장성 및 다양성 증대를 통해 에이전트의 long-horizon 탐색 역량을 더욱 극대화하는 기반이 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Marco DeepResearch: Unlocking Efficient Deep Research Agents via Verification-Centric Design
- [논문리뷰] SkillCoach: Self-Evolving Rubrics for Evaluating and Enhancing Agentic Skill-Use
- [논문리뷰] Advancing WordArt-Oriented Scene Text Recognition: Datasets and Methods
- [논문리뷰] RODS: Reward-Driven Online Data Synthesis for Multi-Turn Tool-Use Agents
- [논문리뷰] Guava: An Effective and Universal Harness for Embodied Manipulation
Review 의 다른글
- 이전글 [논문리뷰] HeavySkill: Heavy Thinking as the Inner Skill in Agentic Harness
- 현재글 : [논문리뷰] OpenSeeker-v2: Pushing the Limits of Search Agents with Informative and High-Difficulty Trajectories
- 다음글 [논문리뷰] PatRe: A Full-Stage Office Action and Rebuttal Generation Benchmark for Patent Examination
댓글