[논문리뷰] HopChain: Multi-Hop Data Synthesis for Generalizable Vision-Language Reasoning
링크: 논문 PDF로 바로 열기
저자: Shenzhi Wang, Shixuan Liu, Jing Zhou, Chang Gao, Xiong-Hui Chen, Binghai Wang, An Yang, Shiji Song, Bowen Yu, Gao Huang, Junyang Lin, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Multi-Hop Vision-Language Reasoning : 여러 단계의 추론이 시각적 증거에 지속적으로 의존하며, 이전 단계에서 설정된 인스턴스, 집합 또는 조건을 기반으로 다음 단계가 논리적으로 이어지는 추론 과정.
- Reinforcement Learning with Verifiable Rewards (RLVR) : 객관적으로 검증 가능한 답변을 통해 보상을 제공하여 모델이 단계별 Chain-of-Thought (CoT) 솔루션을 생성하도록 훈련하는 강화 학습 프레임워크.
- Chain-of-Thought (CoT) : 복잡한 추론 문제를 해결하기 위해 모델이 중간 단계를 순차적으로 생성하며 최종 답변에 도달하는 방식.
- Perception-level Hop : 단일 객체 인지 (Level 1)와 다중 객체 관계 추론 (Level 2) 사이를 전환하며, 이전 홉에서 확립된 인스턴스, 집합 또는 조건에 기반하는 홉 유형.
- Instance-chain Hop : 이전 홉에서 확립된 인스턴스, 집합 또는 조건을 통해서만 다음 인스턴스를 식별할 수 있는 명시적인 인스턴스 의존성 체인을 따르는 홉 유형.
- Soft Adaptive Policy Optimization (SAPO) : RLVR 알고리즘에서 발생하는 불안정성을 완화하기 위해 hard clipping 대신 temperature-controlled soft gate를 사용하는 최적화 알고리즘.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
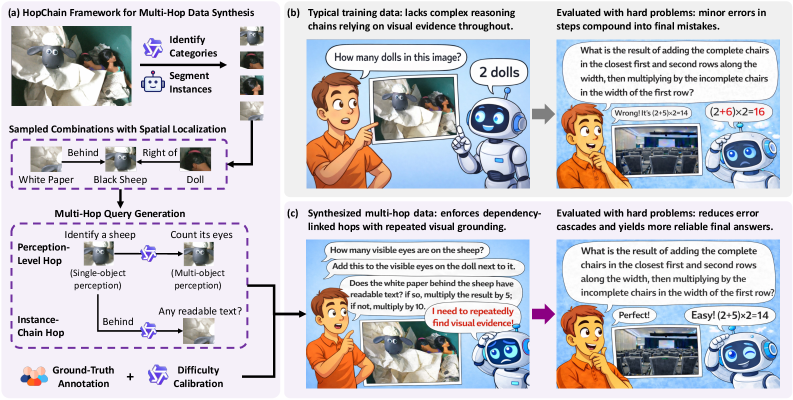
Vision-language Models (VLMs)는 fine-grained하고 multi-step의 복잡한 시각-언어 추론 Task에서 여전히 어려움을 겪고 있다. 특히, 긴 Chain-of-Thought (CoT) 추론 과정은 Perception, Reasoning, Knowledge, 그리고 Hallucination 오류를 포함한 다양한 실패 모드를 유발하며, 이러한 오류는 중간 단계에서 누적되어 최종적으로 잘못된 답변으로 이어질 수 있다. 기존의 Reinforcement Learning with Verifiable Rewards (RLVR) 훈련 데이터는 대부분 이러한 복잡한 추론 체인을 효과적으로 반영하지 못하며, 시각적 증거에 지속적으로 의존하는 경우가 드물어 VLM의 이러한 근본적인 약점을 훈련 중에 충분히 노출시키지 못한다 [cite: 1, Figure 1b]. 따라서, 저자들은 모델이 긴 CoT 추론의 각 단계에서 시각적 증거를 반복적으로 탐색하도록 구조적으로 유도하여, 단계별 시각-언어 추론 능력을 강화하고 다양한 시나리오에 대한 Generalization 성능을 향상시킬 수 있는 새로운 훈련 데이터의 필요성을 제기한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 VLM의 Generalization 능력을 향상시키기 위해 HopChain 이라는 Multi-Hop 데이터 합성 프레임워크를 제안한다 [cite: 1, Figure 1a]. HopChain은 합성된 각 Multi-Hop 쿼리가 논리적으로 의존적인 Instance-grounded Hops의 체인을 형성하도록 설계되었다 [cite: 1, Figure 1c]. 이 체인에서, 이전 홉의 결과는 다음 홉에 필요한 인스턴스, 집합 또는 조건을 설정하며, 이는 모델에게 훈련 과정 전반에 걸쳐 반복적인 visual re-grounding을 강제한다. 모든 쿼리는 RLVR에 쉽게 검증 가능한 특정하고 모호하지 않은 숫자 답변으로 귀결된다. HopChain의 데이터 합성 파이프라인은 (1) Qwen3-VL-235B-A22B-Thinking을 이용한 category identification , (2) SAM3를 이용한 instance segmentation , (3) Qwen3-VL-235B-A22B-Thinking을 이용한 multi-hop query generation , 마지막으로 (4) 인간 검증 및 난이도 조정을 포함하는 human-in-the-loop verification 의 네 단계로 구성된다 [cite: 1, Figure 1a].
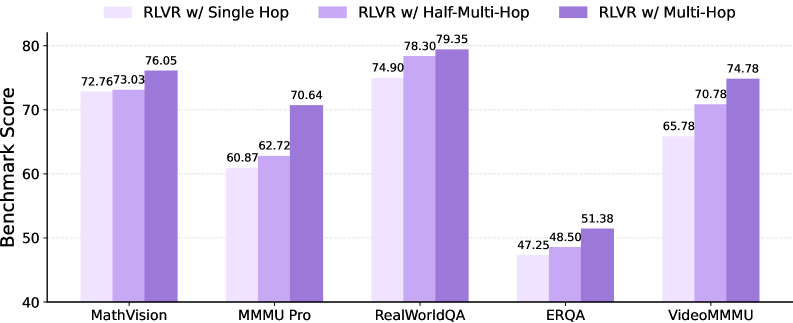
HopChain으로 합성된 Multi-Hop 데이터는 Qwen3.5-35B-A3B 및 Qwen3.5-397B-A17B 모델의 RLVR 훈련에 Soft Adaptive Policy Optimization (SAPO) 알고리즘과 함께 적용되었다. 실험 결과, Multi-Hop 데이터를 추가한 경우 기존 RLVR 데이터만 사용한 baseline 대비 두 모델 모두에서 24개 벤치마크 중 20개 에서 성능 향상을 보였다. 특히, Qwen3.5-35B-A3B 모델의 평균 점수는 5개 대표 벤치마크에서 Multi-Hop 설정이 70.4점 을 달성하며, Single-Hop (64.3점) 및 Half-Multi-Hop (66.7점) 변형보다 우수함을 입증했다 [cite: 1, Figure 5]. 이는 전체 체인 쿼리의 보존이 중요함을 보여준다. 또한, Qwen3.5-397B-A17B의 ultra-long-CoT 추론 영역에서는 정확도가 50점 이상 크게 향상되어, Multi-Hop 훈련이 긴 CoT 시각-언어 추론을 실질적으로 강화함을 입증했다. 이처럼 합성된 데이터는 특정 벤치마크에 맞춰 설계되지 않았음에도 불구하고, 다양한 시나리오에 대한 Generalizable VLM Reasoning 능력을 광범위하게 개선함을 보여주었다 [cite: 1, Figure 4]. 추가 분석에 따르면, 합성된 Multi-Hop 데이터는 넓은 난이도 범위를 커버하며, Perception, Reasoning, Knowledge, Hallucination 등 다양한 실패 모드의 개선에 기여했다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 긴 Chain-of-Thought (CoT) 추론 과정에서 발생하는 다양하고 복합적인 실패 모드가 Vision-language Models (VLMs)의 견고한 시각-언어 추론 능력 개발에 핵심적인 장애물임을 식별했다. 이러한 문제에 대응하기 위해, 저자들은 HopChain이라는 확장 가능한 프레임워크를 제안하여 Multi-Hop Vision-Language Reasoning 데이터를 합성했다. HopChain이 생성하는 쿼리는 이전 홉이 다음 홉에 필요한 인스턴스, 집합 또는 조건을 설정하여 반복적인 시각적 재확인(visual re-grounding)을 강제하며, 검증 가능한 보상에 적합한 특정하고 모호하지 않은 숫자 답변으로 귀결된다. HopChain으로 합성된 Multi-Hop 데이터를 기존 Reinforcement Learning with Verifiable Rewards (RLVR) 훈련 데이터와 함께 사용함으로써, Qwen3.5-35B-A3B 및 Qwen3.5-397B-A17B 두 모델 모두 24개 벤치마크 중 20개에서 광범위하고 일반화 가능한 성능 향상을 달성했다. 이러한 결과는 합성된 데이터가 특정 벤치마크에 국한되지 않고 일반적인 VLM 추론 능력을 향상시키는 데 효과적이며 확장 가능하다는 점을 입증한다. HopChain은 VLM의 장기적인 CoT 추론의 견고성과 일반화 능력을 크게 개선하여, 향후 더욱 신뢰성 높은 멀티모달 AI 시스템 개발에 중요한 기여를 할 것으로 기대된다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Long Grounded Thoughts: Distilling Compositional Visual Reasoning Chains at Scale
- [논문리뷰] LLaTiSA: Towards Difficulty-Stratified Time Series Reasoning from Visual Perception to Semantics
- [논문리뷰] Learning Adaptive Reasoning Paths for Efficient Visual Reasoning
- [논문리뷰] Vero: An Open RL Recipe for General Visual Reasoning
- [논문리뷰] InternVL-U: Democratizing Unified Multimodal Models for Understanding, Reasoning, Generation and Editing
Review 의 다른글
- 이전글 [논문리뷰] HiMu: Hierarchical Multimodal Frame Selection for Long Video Question Answering
- 현재글 : [논문리뷰] HopChain: Multi-Hop Data Synthesis for Generalizable Vision-Language Reasoning
- 다음글 [논문리뷰] How Well Does Generative Recommendation Generalize?
댓글