[논문리뷰] HiMu: Hierarchical Multimodal Frame Selection for Long Video Question Answering
링크: 논문 PDF로 바로 열기
I have browsed the paper. Now I will extract the information needed for the summary and figure JSON.
Part 1: Summary
Authors: Dan Ben-Ami, Gabriele Serussi, Kobi Cohen, Chaim Baskin
Keywords: Video Question Answering, Frame Selection, Neuro-Symbolic Reasoning, Multimodal Understanding, Long Video
Key Terms & Definitions:
- LVLM (Large Vision-Language Models) : 비디오와 텍스트를 모두 이해하고 처리할 수 있는 대규모 모델. 긴 비디오의 경우 finite context windows 로 인해 전체 비디오를 처리하는 데 제약이 있다.
- Frame Selection : 긴 비디오에서 질문에 답하는 데 가장 관련성이 높은 프레임을 효율적으로 추출하는 과정. LVLM의 context window 한계를 극복하기 위해 필수적이다.
- Hierarchical Logic Tree : 자연어 질문(query)을 계층적이고 논리적인 구조로 분해한 트리 형태. 각 leaf node 는 atomic predicate 와 특정 modality-specific expert 에 할당된다.
- Modality-Specific Expert : CLIP (Visual), OVD (Open-Vocabulary Detection), OCR (On-Screen Text Recognition), ASR (Speech Recognition), CLAP (Environmental Audio Events)와 같이 특정 모달리티에 특화된 경량 모델.
- Fuzzy Logic Composition : 각 expert signal 을 continuous fuzzy-logic operators (And, Or, Seq, RightAfter)를 통해 통합하여 per-frame satisfaction curve 를 생성하는 과정.
- PASS (Peak-And-Spread Selection) : satisfaction curve 에서 가장 높은 점수를 얻은 프레임을 선택하되, local maxima 를 검출하고 각 peak 주변의 인접 프레임을 함께 선택하여 temporal diversity 와 short-term motion context 를 확보하는 전략.
Motivation & Problem Statement: Long-form video question answering (VideoQA)은 확장된 시간적 맥락에 대한 추론을 요구하지만, 현재 Large Vision-Language Models (LVLMs) 의 finite context windows 는 전체 비디오를 원시 프레임 속도로 처리하는 것을 불가능하게 만든다. 이로 인해 frame selection 이 결정적인 bottleneck 이 된다. 기존 frame selection 방법론들은 효율성과 추론 깊이 사이의 심각한 trade-off 에 직면한다. Similarity-based selectors 는 빠르지만 compositional queries 를 단일 dense vector 로 압축하여 sub-event ordering 이나 cross-modal bindings 정보를 손실한다. 예를 들어, *“After the narrator mentions the chemical reaction, what happens to the beaker on the left?”*와 같은 질문은 오디오와 비주얼 트랙 모두에 걸친 추론과 시간적 의존성을 요구하는데, 단일 모달리티 인코더로는 이를 포착하기 어렵다. 반대로, agent-based methods 는 반복적인 LVLM inference 를 통해 compositional understanding 을 달성하지만, 계산 비용이 매우 높고 latency 가 10-100배 더 길다. 이러한 한계점들은 정교한 compositional reasoning 이 값비싼 반복적 추론과 불가피하게 연결되어 있다는 기존의 가정을 초래한다.
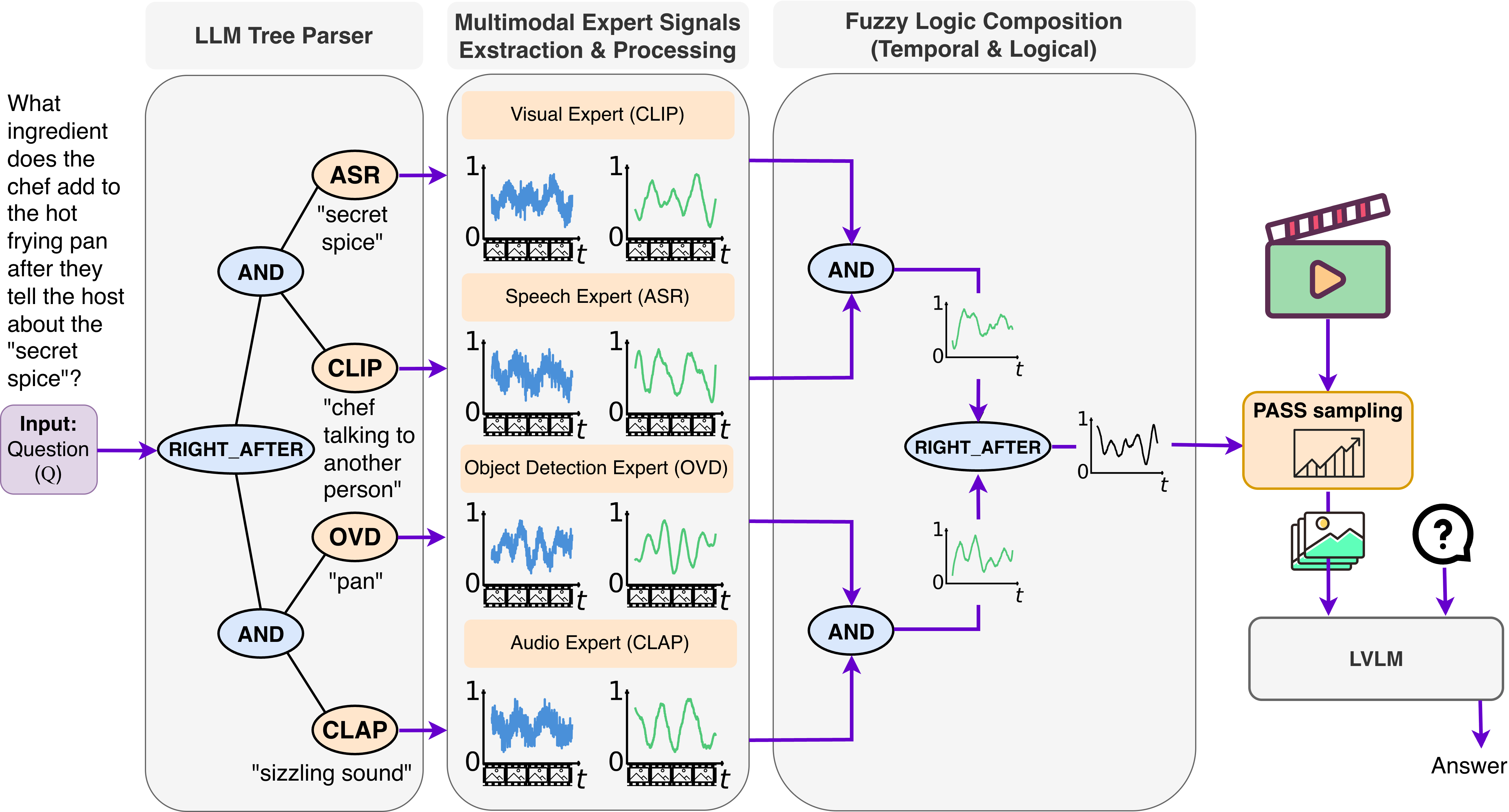
Method & Key Results: 저자들은 이러한 trade-off 를 해결하기 위해 HiMu (Hierarchical Multimodal Frame Selection) 프레임워크를 제안한다. HiMu 는 4단계로 구성된다 [Figure 3, cite: 1]: (i) text-only LLM 이 질문(Q)을 hierarchical logic tree (𝒯)로 분해한다. 이 트리의 leaf nodes 는 modality-specific expert (CLIP, OVD, OCR, ASR, CLAP)와 atomic predicate 를 지정한다. (ii) 각 leaf node 는 해당 expert 에 의해 per-frame raw relevance signal 을 생성하며, 이 신호들은 정규화되고 bandwidth-matched smoothing 을 거쳐 다른 모달리티의 시간적 비동기를 해결한다. (iii) 신호들은 fuzzy-logic operators (And, Or, Seq, RightAfter)를 통해 bottom-up 방식으로 통합되어 per-frame satisfaction curve 를 생성한다. (iv) 최종적으로 PASS (Peak-And-Spread Selection) 전략을 사용하여 top-K 프레임을 선택한다. 이 전체 과정은 단일 text-only LLM call 만 필요하며, 반복적인 LVLM inference 없이 compositional structure 를 효율적으로 해결한다.
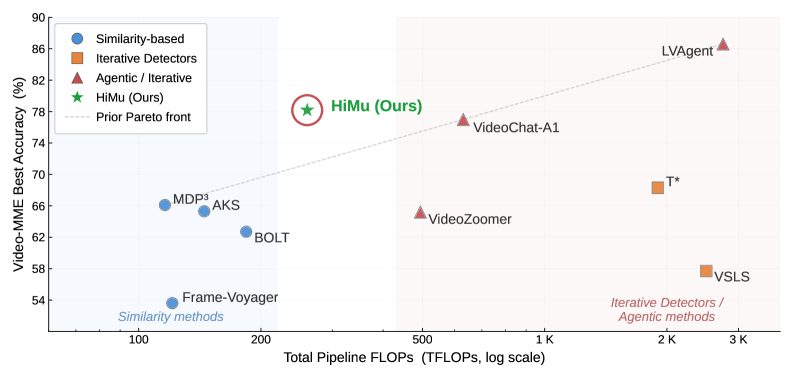
실험 결과, HiMu 는 Video-MME, LongVideoBench, HERBench-Lite 벤치마크에서 기존 방법론들을 능가하며 efficiency-accuracy Pareto front 를 재정의했다 [Figure 2, cite: 1]. Qwen3-VL 8B 모델과 K=16 프레임 예산에서, HiMu 는 모든 경쟁 selector 보다 우수한 성능을 보였다. 특히, Video-MME에서 73.22% 의 accuracy 를 달성하여 Uniform Sampling (66.36%) , BOLT (68.74%) , T* (69.77%), AKS (67.98%)를 앞섰다 [Table 2, cite: 1]. GPT-4o와 결합했을 때, HiMu는 16프레임으로 78.18%의 accuracy를 기록하며 32-512프레임을 사용하는 agentic systems (VSLS 67.09% at 32 frames, VideoChat-A1 62.99% at 384 frames)을 넘어섰으며, 약 10배 적은 FLOPs를 요구한다. Ablation study는 compositional structure가 HiMu 성능에 가장 크게 기여하며 (Flat Fusion 대비 -5.49pp 하락), ASR (-1.99pp)과 CLIP (-1.43pp) 모달리티가 주요 기여자임을 보여준다 [Table 3, cite: 1]. 또한, HiMu는 K=16 프레임에서 K=64 프레임의 Uniform Sampling을 능가하며, 필요한 프레임 예산을 4배 절감하면서도 유사한 accuracy를 달성한다 [Table 3, cite: 1].
Conclusion & Impact: HiMu는 long video question answering을 위한 compositional frame selection이 반복적인 LVLM inference 없이도 가능하다는 것을 입증했다. 질문을 hierarchical logic tree로 분해하고, modality-specific experts를 활용하여 single shot으로 가장 유용한 프레임을 식별함으로써, 기존 similarity-based selectors를 능가하고 agent-based systems와 동등하거나 더 우수한 성능을 훨씬 적은 비용으로 달성한다. 이 연구는 frame selection의 bottleneck이 query representation 방식에 더 크게 의존하며, 모델 호출 횟수에는 덜 의존한다는 것을 시사한다. HiMu의 neuro-symbolic design은 모든 frame-selection decision을 fully auditable하게 만들어, 각 프레임이 어떤 expert-predicate pair에 의해 선택되었는지 명확한 trace를 제공한다. 이러한 interpretability는 시스템의 진단 및 개선에 직접적인 실질적 가치를 제공하며, frame selection 방법론의 새로운 Pareto front를 제시하여 해당 분야의 연구 방향에 중요한 시사점을 제공한다.
Part 2: Important Figure Information
I need to find the image URLs and create short Korean captions. Looking at the HTML content and identified figures:
- Figure 1:
2603.18558v1/figures/teaser_plot3.png(Paradigm comparison) - Figure 2:
2603.18558v1/x1.png(Accuracy vs. computational cost) - Figure 3:
2603.18558v1/figures/himu_pipe3_with_vid_streams2.png(HiMu pipeline) - Figure 4:
2603.18558v1/figures/trees_examples2.png(Logic tree examples) - Figure 5:
2603.18558v1/figures/HiMu_teaser.jpg(HiMu pipeline overview - seems similar to Figure 3, but simpler, maybe for introduction) - Figure 6:
2603.18558v1/figures/PASS.jpg(PASS vs. naive top-KK selection) - Figure 7:
2603.18558v1/figures/himu_interpretability_updated_sec.png(Per-leaf activation heatmap)
I will select Figure 3 (main pipeline), Figure 2 (key results on Pareto front), and Figure 7 (interpretability, a unique feature). Figure 1 is also good but Figure 2 captures the "advances the Pareto front" better with quantitative results. Figure 5 is similar to Figure 3. Figure 4 is good but Figure 3 already shows the tree concept. Figure 6 is about PASS, which is a component of the method but less "overall important" than the full pipeline or key results.
Figure URLs must be absolute: https://arxiv.org/html/ + relative path.
- Figure 3:
https://arxiv.org/html/2603.18558v1/figures/himu_pipe3_with_vid_streams2.pngCaption: 제안 모델의 전체 파이프라인 - Figure 2:
https://arxiv.org/html/2603.18558v1/x1.pngCaption: 정확도 및 계산 비용 비교 - Figure 7:
https://arxiv.org/html/2603.18558v1/figures/himu_interpretability_updated_sec.pngCaption: 프레임 선택 해석 가능성
저자: Dan Ben-Ami, Gabriele Serussi, Kobi Cohen, Chaim Baskin, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- LVLM (Large Vision-Language Models): 비디오와 텍스트를 모두 이해하고 처리할 수 있는 대규모 모델. 긴 비디오의 경우 finite context windows로 인해 전체 비디오를 처리하는 데 제약이 있다.
- Frame Selection: 긴 비디오에서 질문에 답하는 데 가장 관련성이 높은 프레임을 효율적으로 추출하는 과정. LVLM의 context window 한계를 극복하기 위해 필수적이다.
- Hierarchical Logic Tree: 자연어 질문(query)을 계층적이고 논리적인 구조로 분해한 트리 형태. 각 leaf node는 atomic predicate와 특정 modality-specific expert에 할당된다.
- Modality-Specific Expert: CLIP (Visual), OVD (Open-Vocabulary Detection), OCR (On-Screen Text Recognition), ASR (Speech Recognition), CLAP (Environmental Audio Events)와 같이 특정 모달리티에 특화된 경량 모델.
- Fuzzy Logic Composition: 각 expert signal을 continuous fuzzy-logic operators (And, Or, Seq, RightAfter)를 통해 통합하여 per-frame satisfaction curve를 생성하는 과정.
- PASS (Peak-And-Spread Selection): satisfaction curve에서 가장 높은 점수를 얻은 프레임을 선택하되, local maxima를 검출하고 각 peak 주변의 인접 프레임을 함께 선택하여 temporal diversity와 short-term motion context를 확보하는 전략.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Long-form video question answering (VideoQA)은 확장된 시간적 맥락에 대한 추론을 요구하지만, 현재 Large Vision-Language Models (LVLMs)의 finite context windows는 전체 비디오를 원시 프레임 속도로 처리하는 것을 불가능하게 만든다. 이로 인해 frame selection이 결정적인 bottleneck이 된다. 기존 frame selection 방법론들은 효율성과 추론 깊이 사이의 심각한 trade-off에 직면한다. Similarity-based selectors는 빠르지만 compositional queries를 단일 dense vector로 압축하여 sub-event ordering이나 cross-modal bindings 정보를 손실한다. 예를 들어, *“After the narrator mentions the chemical reaction, what happens to the beaker on the left?”*와 같은 질문은 오디오와 비주얼 트랙 모두에 걸친 추론과 시간적 의존성을 요구하는데, 단일 모달리티 인코더로는 이를 포착하기 어렵다. 반대로, agent-based methods 는 반복적인 LVLM inference 를 통해 compositional understanding 을 달성하지만, 계산 비용이 매우 높고 latency 가 10-100배 더 길다. 이러한 한계점들은 정교한 compositional reasoning 이 값비싼 반복적 추론과 불가피하게 연결되어 있다는 기존의 가정을 초래한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 이러한 trade-off 를 해결하기 위해 HiMu (Hierarchical Multimodal Frame Selection) 프레임워크를 제안한다. HiMu 는 4단계로 구성된다 [Figure 3, cite: 1]: (i) text-only LLM 이 질문(Q)을 hierarchical logic tree (𝒯)로 분해한다. 이 트리의 leaf nodes 는 modality-specific expert (CLIP, OVD, OCR, ASR, CLAP)와 atomic predicate 를 지정한다. (ii) 각 leaf node 는 해당 expert 에 의해 per-frame raw relevance signal 을 생성하며, 이 신호들은 정규화되고 bandwidth-matched smoothing 을 거쳐 다른 모달리티의 시간적 비동기를 해결한다. (iii) 신호들은 fuzzy-logic operators (And, Or, Seq, RightAfter)를 통해 bottom-up 방식으로 통합되어 per-frame satisfaction curve 를 생성한다. (iv) 최종적으로 PASS (Peak-And-Spread Selection) 전략을 사용하여 top-K 프레임을 선택한다. 이 전체 과정은 단일 text-only LLM call 만 필요하며, 반복적인 LVLM inference 없이 compositional structure 를 효율적으로 해결한다.
실험 결과, HiMu 는 Video-MME, LongVideoBench, HERBench-Lite 벤치마크에서 기존 방법론들을 능가하며 efficiency-accuracy Pareto front 를 재정의했다 [Figure 2, cite: 1]. Qwen3-VL 8B 모델과 K=16 프레임 예산에서, HiMu 는 모든 경쟁 selector 보다 우수한 성능을 보였다. 특히, Video-MME에서 73.22% 의 accuracy 를 달성하여 Uniform Sampling (66.36%) , BOLT (68.74%) , T* (69.77%), AKS (67.98%)를 앞섰다 [Table 2, cite: 1]. GPT-4o와 결합했을 때, HiMu는 16프레임으로 78.18%의 accuracy를 기록하며 32-512프레임을 사용하는 agentic systems (VSLS 67.09% with 32 frames, VideoChat-A1 62.99% with 384 frames)을 넘어섰으며, 약 10배 적은 FLOPs를 요구한다. Ablation study는 compositional structure가 HiMu 성능에 가장 크게 기여하며 (Flat Fusion 대비 -5.49pp 하락), ASR (-1.99pp)과 CLIP (-1.43pp) 모달리티가 주요 기여자임을 보여준다 [Table 3, cite: 1]. 또한, HiMu는 K=16 프레임에서 K=64 프레임의 Uniform Sampling을 능가하며, 필요한 프레임 예산을 4배 절감하면서도 유사한 accuracy를 달성한다 [Table 3, cite: 1].
4. Conclusion & Impact (결론 및 시사점)
HiMu는 long video question answering을 위한 compositional frame selection이 반복적인 LVLM inference 없이도 가능하다는 것을 입증했다. 질문을 hierarchical logic tree로 분해하고, modality-specific experts를 활용하여 single shot으로 가장 유용한 프레임을 식별함으로써, 기존 similarity-based selectors를 능가하고 agent-based systems와 동등하거나 더 우수한 성능을 훨씬 적은 비용으로 달성한다. 이 연구는 frame selection의 bottleneck이 query representation 방식에 더 크게 의존하며, 모델 호출 횟수에는 덜 의존한다는 것을 시사한다. HiMu의 neuro-symbolic design은 모든 frame-selection decision을 fully auditable하게 만들어, 각 프레임이 어떤 expert-predicate pair에 의해 선택되었는지 명확한 trace를 제공한다 [Figure 7, cite: 1]. 이러한 interpretability는 시스템의 진단 및 개선에 직접적인 실질적 가치를 제공하며, frame selection 방법론의 새로운 Pareto front를 제시하여 해당 분야의 연구 방향에 중요한 시사점을 제공한다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] HERBench: A Benchmark for Multi-Evidence Integration in Video Question Answering
- [논문리뷰] Confidence-Aware Tool Orchestration for Robust Video Understanding
- [논문리뷰] UniDDT: Unifying Multimodal Understanding and Generation with Decoupled Diffusion Transformer
- [논문리뷰] CogOmniControl: Reasoning-Driven Controllable Video Generation via Creative Intent Cognition
- [논문리뷰] FrameSkip: Learning from Fewer but More Informative Frames in VLA Training
Review 의 다른글
- 이전글 [논문리뷰] FlowScene: Style-Consistent Indoor Scene Generation with Multimodal Graph Rectified Flow
- 현재글 : [논문리뷰] HiMu: Hierarchical Multimodal Frame Selection for Long Video Question Answering
- 다음글 [논문리뷰] HopChain: Multi-Hop Data Synthesis for Generalizable Vision-Language Reasoning
댓글