[논문리뷰] FrameSkip: Learning from Fewer but More Informative Frames in VLA Training
링크: 논문 PDF로 바로 열기
메타데이터
저자: Bin Yu, Shijie Lian, Xiaopeng Lin, Zhaolong Shen, Yuliang Wei, Changti Wu, Hang Yuan, Haishan Liu, Bailing Wang, Cong Huang, Kai Chen
1. Key Terms & Definitions (핵심 용어 및 정의)
- VLA (Vision-Language-Action): 시각적 관찰, 언어 지시어, 그리고 로봇의 동작 생성을 하나의 정책 모델로 통합한 학습 패러다임입니다.
- FrameSkip: Trajectory 내의 중요도 점수를 기반으로 Informative frames를 선택하고, 학습 과정에서 Temporal supervision을 재배분하는 데이터 계층 프레임워크입니다.
- AVI (Action Variation Importance): 인접 프레임 간의 Action 변화량과 단기적 움직임을 측정하여, 정밀한 조작이 필요한 핵심 구간을 식별하는 지표입니다.
- VAC (Visual-Action Coherence): Visual feature 변화와 Action 변화의 비율을 통해, 단순히 행동뿐만 아니라 환경과의 시각적 상호작용이 중요한 구간을 포착하는 지표입니다.
- TPI (Task Progress Importance): Manipulation-critical stage의 위치 정보를 사전(Prior)으로 활용하여, 과업 흐름상 중요한 시점을 식별하는 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 VLA 모델 학습 과정에서 무분별하게 모든 프레임을 동일한 비중으로 사용하는 'Temporal supervision imbalance' 문제를 해결하고자 합니다. 대다수의 로봇 시연 데이터는 Approach나 대기 상태와 같은 중복적인 구간이 길게 차지하는 반면, Grasping이나 Alignment와 같은 결정적인 상호작용 구간은 매우 희소합니다. 결과적으로, 모델은 전체적으로는 적응하지만 실제 조작이 필요한 국소 구간에서 취약한 성능을 보이게 됩니다 [Figure 1]. 이러한 학습 효율성 문제를 해결하기 위해, 모든 프레임을 학습에 활용하는 기존 방식을 탈피하여 정보량이 높은 프레임에 자원을 집중하는 새로운 접근법이 요구됩니다 [Figure 2].
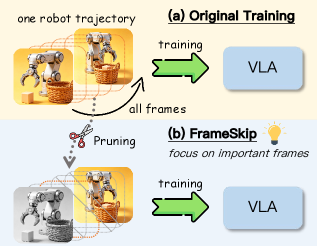
Figure 1 — Temporal supervision imbalance

Figure 2 — 프레임 중요도 재배분 동기
3. Method & Key Results (제안 방법론 및 핵심 결과)
제안하는 FrameSkip은 학습 과정에서 VLA 아키텍처나 손실 함수를 전혀 수정하지 않고, 데이터로더(Dataloader) 계층에서 중요도가 높은 프레임만을 동적으로 선택하는 프레임워크입니다 [Figure 3]. 저자들은 AVI, VAC, TPI를 결합한 스코어링 함수를 통해 각 프레임의 중요도를 계산하고, 지정된 Retention ratio(메인 실험에서 20%)에 따라 학습 데이터의 Index를 재매핑합니다. 학습 안정성을 위해 초기 Warmup 단계에서는 전체 프레임을 사용하고, 이후 pruned mini-batch와 전체 프레임 기반 anchor mini-batch를 혼합하여 학습을 진행합니다.
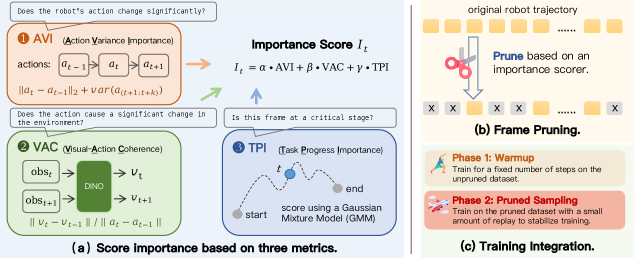
Figure 3 — FrameSkip 전체 파이프라인
정량적 실험 결과, FrameSkip은 RoboCasa-GR1, SimplerEnv, LIBERO 벤치마크 전반에서 기존 Full-frame 학습 대비 압도적인 성능 향상을 보였습니다. 특히 3개 벤치마크의 Macro-average 성공률이 기존 66.50%에서 76.15%로 대폭 상승하였으며, 이는 무작위 프레임 샘플링(Random pruning)보다 유의미하게 높은 수치입니다 [Table 1], [Table 2], [Table 3]. 또한 Retention ratio에 대한 Ablation study를 통해 20~30% 수준의 압축률이 학습 효율과 성능 사이에서 최적의 균형점을 제공함을 확인하였습니다 [Table 4].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 로봇 학습 데이터 내의 구조적 중복성을 제거하고 고정보량 프레임에 학습 자원을 재배분하는 것이 VLA 성능 향상에 필수적임을 입증했습니다. FrameSkip은 아키텍처 의존성 없이 간편하게 적용 가능한 데이터 계층 인터벤션으로서, 향후 embodied multimodal learning 분야에서 데이터 큐레이션의 표준적인 고려 사항으로 자리 잡을 것으로 기대됩니다. 본 프레임워크는 대규모 데이터셋을 활용하는 모델 학습에서 연산 효율성을 극대화하면서도 정책의 정밀도를 유지하는 강력한 전략을 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ABot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold Learning
- [논문리뷰] From Spatial to Actions: Grounding Vision-Language-Action Model in Spatial Foundation Priors
- [논문리뷰] EVA-Client: A Unified Data Collection, Inference, and Deployment Framework for Embodied Policies on Real Robots
- [논문리뷰] ImageWAM: Do World Action Models Really Need Video Generation, or Just Image Editing?
- [논문리뷰] ACE-Ego-0: Unifying Egocentric Human and Robotic Data for VLA Pretraining
Review 의 다른글
- 이전글 [논문리뷰] FeatCal: Feature Calibration for Post-Merging Models
- 현재글 : [논문리뷰] FrameSkip: Learning from Fewer but More Informative Frames in VLA Training
- 다음글 [논문리뷰] Frequency Bias and OOD Generalization in Neural Operators under a Variable-Coefficient Wave Equation
댓글