[논문리뷰] VideoDetective: Clue Hunting via both Extrinsic Query and Intrinsic Relevance for Long Video Understanding
링크: 논문 PDF로 바로 열기
저자: Ruoliu Yang, Chu Wu, Caifeng Shan, Ran He, Chaoyou Fu et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- MLLM (Multimodal Large Language Model) : 텍스트와 비디오를 포함한 다양한 모달리티의 정보를 처리하고 이해하는 대규모 언어 모델. 긴 비디오의 방대한 정보 처리에서 한계가 있다.
- Visual-Temporal Affinity Graph : 비디오 세그먼트 간의 시각적 유사성(Visual Similarity)과 시간적 근접성(Temporal Proximity)을 통합하여 구성된 그래프. 비디오의 내재적 구조(Intrinsic Structure)를 모델링한다.
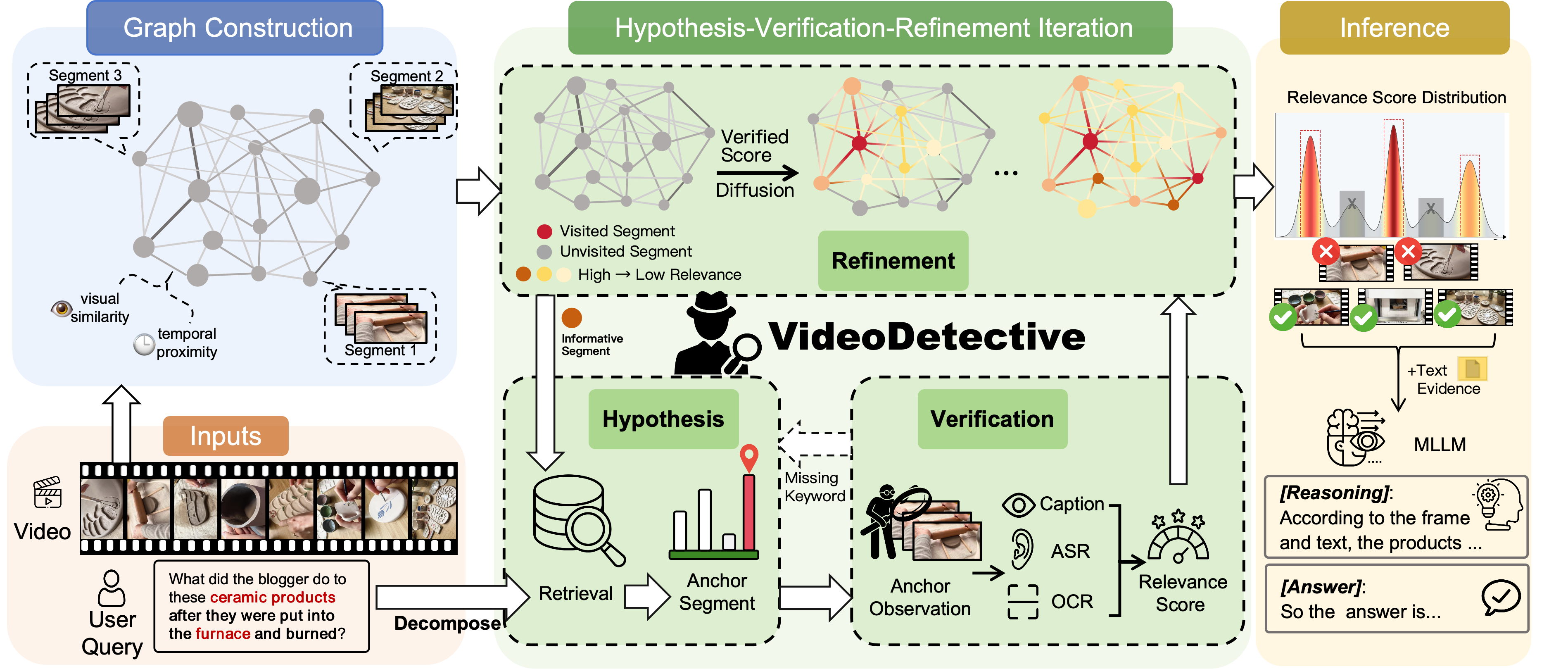
- Hypothesis-Verification-Refinement Loop : VideoDetective의 핵심적인 반복 추론 프로세스. 가설 설정(Hypothesis)을 통해 관찰할 세그먼트를 선택하고, 다중 모달 증거(Multimodal Evidence)를 통해 관련성(Relevance)을 검증(Verification)하며, 그래프 확산(Graph Diffusion)을 통해 전역 신념 필드(Global Belief Field)를 업데이트(Refinement)한다.
- Global Belief Field (GBF) : 비디오의 모든 세그먼트에 대한 쿼리 관련성 점수 분포를 나타내는 조밀한 전역 벡터. 이 필드는 관찰되지 않은 세그먼트의 관련성까지 추정하여 다음 관찰을 안내한다.
- Graph-NMS (Graph Non-Maximum Suppression) : 최종 단계에서 전역 신념 필드에서 가장 신뢰도가 높은 세그먼트를 선택하되, 인접한 중복 세그먼트를 억제하여 다양하고 대표적인 핵심 증거 세트(Evidence Set)를 추출하는 메커니즘.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
긴 비디오 이해(Long Video Understanding)는 MLLM의 제한된 Context Window 때문에 여전히 어려운 과제이며, 이는 쿼리 관련성이 높은 희소한 비디오 세그먼트를 식별해야 할 필요성을 야기합니다. 기존의 방법론들은 주로 쿼리에만 의존하여 단서를 찾아내고, 비디오의 내재적 구조(Intrinsic Structure)와 세그먼트 간의 다양한 관련성(Varying Relevance)을 간과하는 한계점이 있습니다. 예를 들어, Keyframe Sampling, Retrieval-Augmented, Agent-based Methods는 Query-to-Content 매칭에 중점을 두지만, 비디오의 시간적 역동성(Temporal Dynamics)과 인과적 연속성(Causal Continuity) 같은 내부 구조를 충분히 활용하지 못합니다. 이러한 기존 접근 방식들은 전체 비디오를 완벽하게 이해하지 않고는 중요한 단서를 안정적으로 찾기 어렵고, 복잡한 추론을 요구하는 질문에 취약합니다. 저자들은 이러한 한계를 극복하기 위해 Query-to-Segment Relevance와 Inter-Segment Affinity를 통합하여 효과적인 단서 탐색(Clue Hunting)을 가능하게 하는 새로운 프레임워크인 VideoDetective 를 제안합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 긴 비디오 질문 응답(Long-Video QA)을 extrinsic Query Relevance와 intrinsic Video Correlations를 통합하여 Query-relevant 비디오 세그먼트를 효율적으로 찾아내는 반복적인 Relevance State Estimation 문제로 공식화합니다. 제안하는 VideoDetective 프레임워크는 (1) 비디오를 시각적 유사성(Visual Similarity)과 시간적 근접성(Temporal Proximity)을 기반으로 Visual-Temporal Affinity Graph로 모델링하고, (2) Query-guided Prior Similarity에 따라 Anchor Segment를 선택하여 Hypothesis를 생성하고, (3) 멀티모달 증거(Visual Caption, OCR, ASR)를 추출하여 Relevance Score를 계산하는 Verification을 수행하며, (4) 그래프 확산(Graph Diffusion)을 통해 관찰된 세그먼트의 관련성(Relevance)을 미방문 세그먼트로 전파하여 Global Belief Field를 업데이트하는 Refinement를 반복적으로 수행합니다. 이 Hypothesis-Verification-Refinement 루프를 통해 모델은 희소한 관찰(Sparse Observations)로부터 전역 의미 정보(Global Semantic Information)를 점진적으로 복구합니다. 최종적으로, Graph-NMS를 사용하여 Global Belief Field에서 상위 랭크된 세그먼트들을 추출하여 MLLM에 입력하여 답변을 생성합니다.
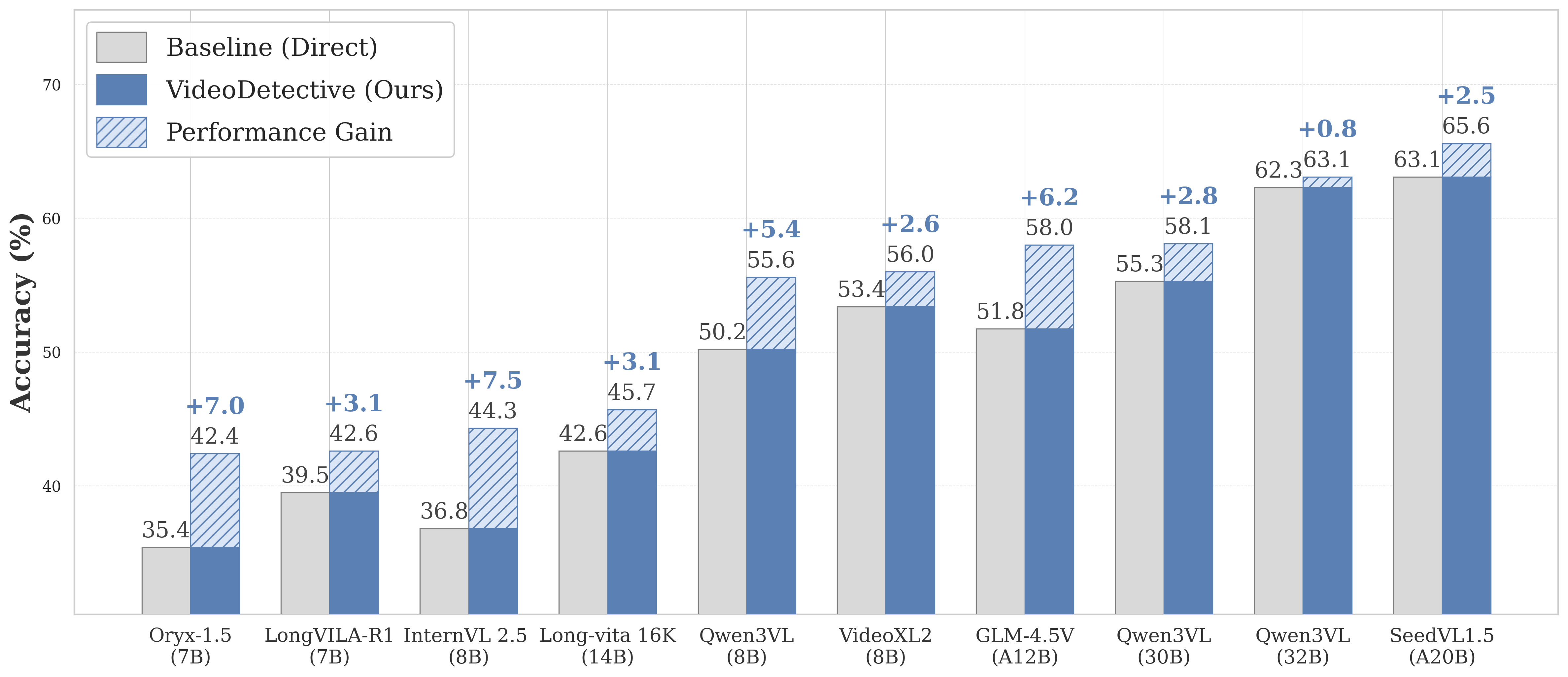
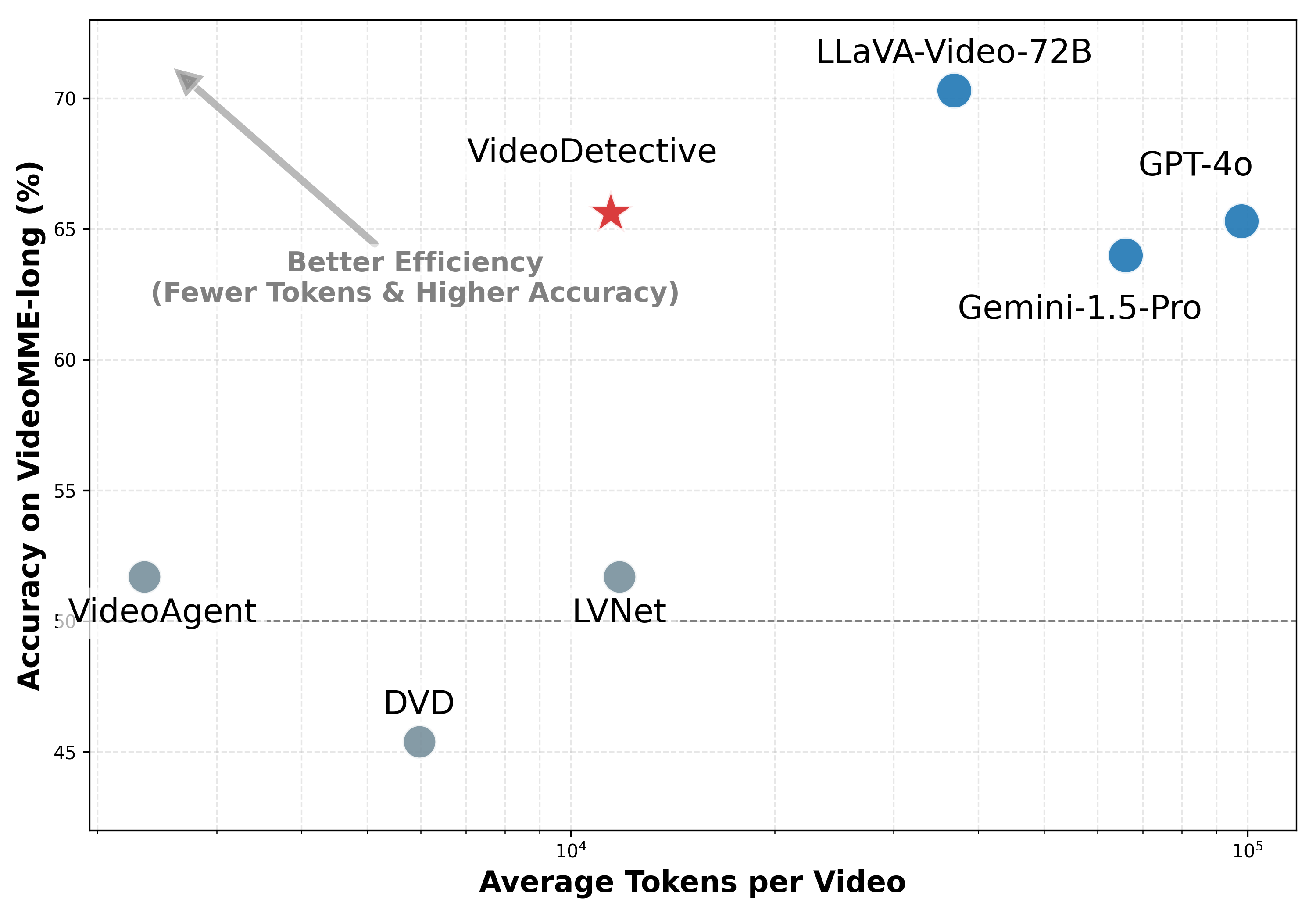
실험 결과, VideoDetective는 다양한 MLLM 백본에서 일관된 성능 향상을 보여줍니다 [cite: 1, Figure 2]. 특히 VideoMME-long 벤치마크에서 InternVL-2.5 (8B) 에 대해 7.5% , Oryx-1.5 (7B) 에 대해 7.0% 의 정확도(Accuracy) 향상을 달성했습니다. SeedVL-1.5 (20B) 와 통합 시, LongVideoBench (Val) 에서 67.9% 의 정확도를 기록하며 GPT-4o (66.7%) 및 Gemini-1.5-Pro (64.0%) 와 같은 대규모 독점 모델들을 능가하는 State-of-the-Art 성능을 입증했습니다 [cite: 1, Table 2]. 또한, Token Efficiency 분석에서 VideoDetective는 모든 비교 방법론 중에서 가장 높은 Token Efficiency를 달성하며 Efficiency-Accuracy Pareto Frontier에서 최적의 위치를 보여주었습니다 [cite: 1, Figure 3]. 예를 들어, VideoDetective는 약 10k 토큰 소비로 65.6% 의 정확도를 달성하는 반면, GPT-4o는 유사한 정확도(65.3%)를 위해 약 10배 많은 토큰을 필요로 합니다. Ablation Study를 통해 그래프 전파(Graph Propagation), Query Semantic Decomposition, Iterative Active Loop, Multimodal Evidence의 각 구성 요소가 성능 향상에 필수적임을 확인했습니다 [cite: 1, Table 3].
4. Conclusion & Impact (결론 및 시사점)
저자들은 extrinsic Query Relevance와 intrinsic Video Correlations를 통합하는 추론 프레임워크인 VideoDetective 를 제안합니다. 이 프레임워크는 긴 비디오를 Visual-Temporal Affinity Graph로 모델링하고 Hypothesis-Verification-Refinement Inference Loop를 수행하여, 희소한 지역적 관찰(Sparse Local Observations)로부터 쿼리 관련성 신호(Query-Relevance Signals)를 전체 비디오로 전파함으로써 긴 비디오 질문 응답을 위한 중요한 단서(Critical Clues)를 찾아냅니다. 광범위한 실험을 통해 VideoDetective가 강력한 MLLM들에 비해 경쟁력 있는 성능을 달성하고 기존의 Baseline들을 일관되게 능가하며, 희소 샘플링(Sparse Sampling)을 통해 계산 효율성(Computational Efficiency)을 유지함을 입증했습니다. 이 연구는 복잡한 추론 작업을 수행하는 데 있어 Open-Source 모델들이 Proprietary 모델들과 경쟁할 수 있음을 보여주며, 긴 비디오 이해 분야의 학계 및 산업계 연구에 중요한 영향을 미칠 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Small Vision-Language Models are Smart Compressors for Long Video Understanding
- [논문리뷰] LongVideoAgent: Multi-Agent Reasoning with Long Videos
- [논문리뷰] LongVT: Incentivizing 'Thinking with Long Videos' via Native Tool Calling
- [논문리뷰] When and What: Diffusion-Grounded VideoLLM with Entity Aware Segmentation for Long Video Understanding
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
Review 의 다른글
- 이전글 [논문리뷰] Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model
- 현재글 : [논문리뷰] VideoDetective: Clue Hunting via both Extrinsic Query and Intrinsic Relevance for Long Video Understanding
- 다음글 [논문리뷰] WorldCache: Content-Aware Caching for Accelerated Video World Models
댓글