[논문리뷰] CiteVQA: Benchmarking Evidence Attribution for Trustworthy Document Intelligence
링크: 논문 PDF로 바로 열기
저자: Dongsheng Ma, Jiayu Li, Zhengren Wang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- CiteVQA: 고품질의 Element-level Bounding-box citation을 요구하여 모델의 추론 근거를 시각적으로 검증하는 새로운 Doc-VQA 벤치마크입니다.
- Strict Attributed Accuracy (SAA): 모델의 최종 답변(Answer)과 그 답변을 뒷받침하는 시각적 증거(Evidence)가 모두 정확할 때만 점수를 부여하는 핵심 평가 지표입니다.
- Attribution Hallucination: 모델이 올바른 답변을 생성하면서도 그 근거가 되는 시각적 영역은 잘못 참조하는 현상을 지칭합니다.
- Evidence Package Extraction: 복잡한 문서 내 흩어진 핵심 정보들을 MLLM Agent를 통해 식별하고 연결하여 시각적 증거 체인을 구성하는 기술적 파이프라인입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대 MLLM의 Doc-VQA 평가 방식이 최종 답변의 정답 여부에만 지나치게 의존하여, 실제 추론의 근거가 되는 시각적 증거의 정확성을 검증하지 못한다는 문제를 지적합니다. [Figure 1] 기존의 Answer-only 평가 방식은 모델이 배경지식으로 답변을 '추측'하거나, 잘못된 문서 영역을 근거로 삼아도 이를 걸러내지 못하는 한계를 지닙니다. 특히 법률, 금융, 의료와 같이 정확한 근거 추적(Evidence Attribution)이 필수적인 분야에서 이러한 '블랙박스'식 추론은 신뢰성에 치명적인 위협이 됩니다. 따라서 저자들은 답변의 정확성과 시각적 증거의 신뢰성을 동시에 평가하는 새로운 벤치마크인 CiteVQA를 제안합니다. [Figure 1]
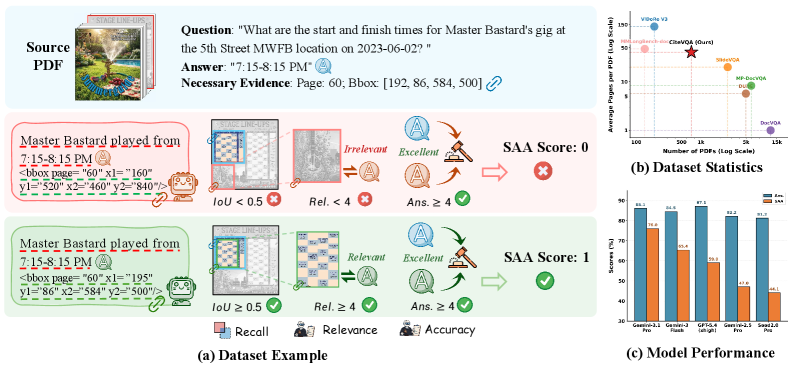
Figure 1 — CiteVQA 벤치마크 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 자동화된 Annotation 파이프라인을 통해 711개의 PDF 문서에서 1,897개의 고품질 QA 쌍을 구축했습니다. [Figure 2] 이 파이프라인은 다중 문서 연결(Multi-document linking), Agent 기반의 증거 패키지 추출, 그리고 마스킹 절차를 통한 핵심 증거 식별(Crucial Evidence Identification) 과정을 포함합니다. 제안된 SAA 지표를 통해 20개의 최신 MLLM을 평가한 결과, 심각한 Attribution Hallucination 현상이 발견되었습니다. [Table 3] 특히 최상위 성능의 모델인 Gemini-3.1-Pro-Preview조차 SAA 점수는 76.0에 그쳤으며, 오픈소스 모델의 경우 최고 성능이 22.5에 불과했습니다. 실험 결과, 답변 정확도(Ans.)가 높음에도 불구하고 SAA 점수가 현저히 낮은 모델들이 다수 확인되어, 모델의 시각적 grounding 능력이 실제 추론의 정확성을 뒷받침하지 못하고 있음을 실증적으로 증명하였습니다. [Table 3]
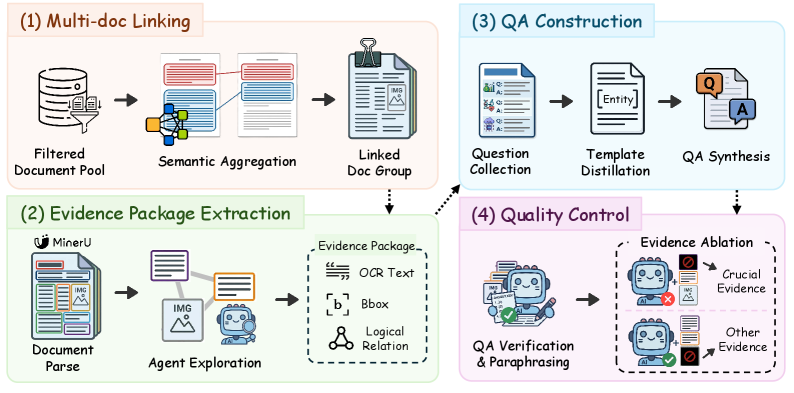
Figure 2 — CiteVQA 자동화 파이프라인
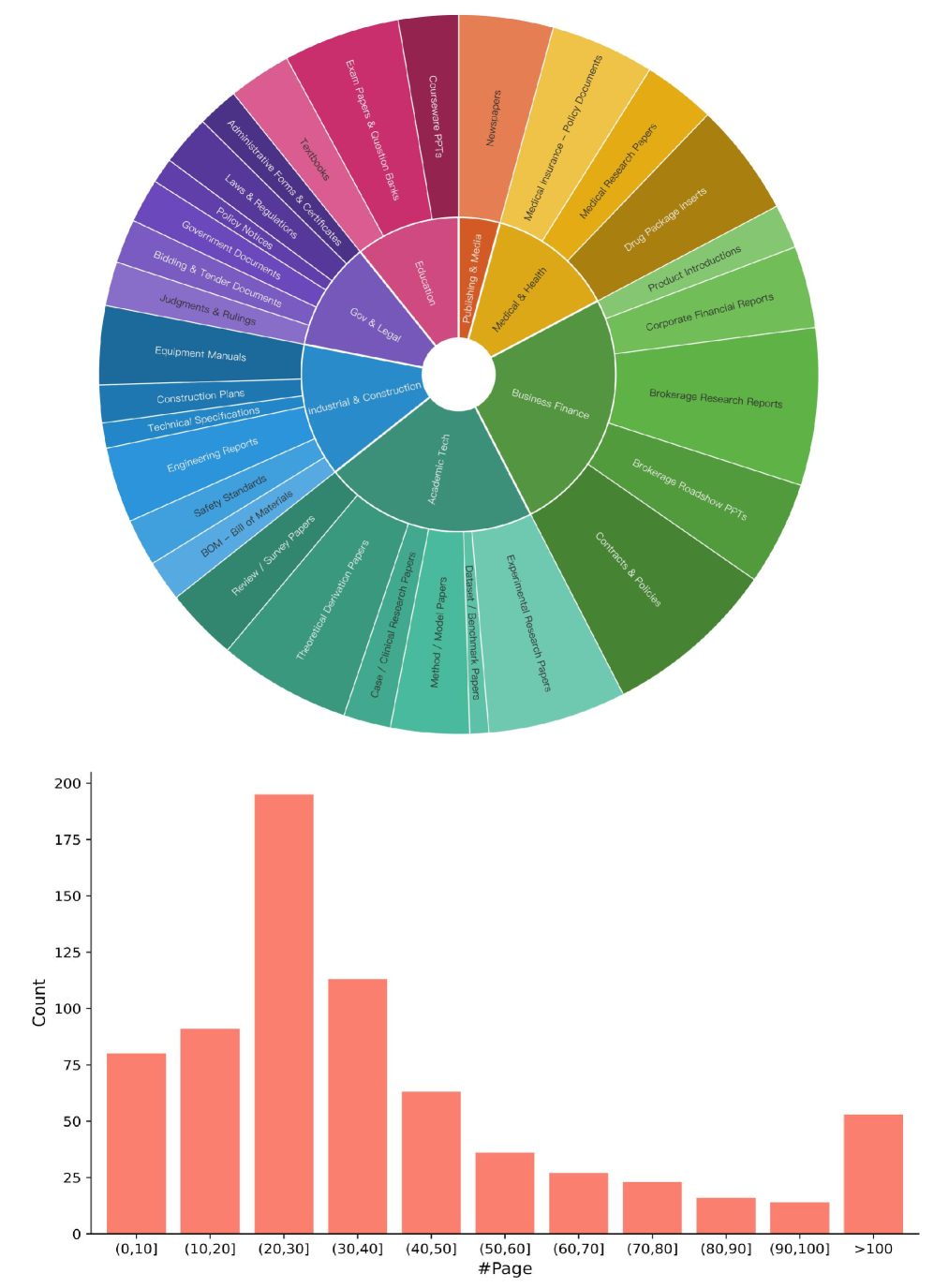
Table 3 — MLLM 모델별 실험 결과
4. Conclusion & Impact (결론 및 시사점)
본 연구는 CiteVQA를 통해 Doc-VQA 평가의 패러다임을 단순 정답 맞히기에서 '시각적 증거 기반의 신뢰성 검증'으로 전환할 것을 제안합니다. Attribution Hallucination의 정량적 발견은 MLLM의 배포 전 엄격한 신뢰성 audit이 필수적임을 시사합니다. 이 벤치마크는 향후 투명하고 설명 가능한(Explainable) AI 시스템을 개발하기 위한 핵심 instrumentation으로 활용될 것이며, 모델의 시각적 grounding 능력을 향상시키는 새로운 학습 방향성을 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] MuseBench: Benchmarking Intent-Level Audiovisual Arts Understanding in MLLMs
- [논문리뷰] Breaking Failure Cascades: Step-Aware Reinforcement Learning for Medical Multimodal Reasoning
- [논문리뷰] PixelEyes: Decoupling Perception and Reasoning for Pinpoint Visual Evidence Seeking
- [논문리뷰] PerceptionRubrics: Calibrating Multimodal Evaluation to Human Perception
Review 의 다른글
- 이전글 [논문리뷰] ChangeFlow -- Latent Rectified Flow for Change Detection in Remote Sensing
- 현재글 : [논문리뷰] CiteVQA: Benchmarking Evidence Attribution for Trustworthy Document Intelligence
- 다음글 [논문리뷰] DexJoCo: A Benchmark and Toolkit for Task-Oriented Dexterous Manipulation on MuJoCo
댓글