[논문리뷰] Edit-Compass & EditReward-Compass: A Unified Benchmark for Image Editing and Reward Modeling
링크: 논문 PDF로 바로 열기
저자: Xuehai Bai, Yang Shi, Yi-Fan Zhang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Edit-Compass: 36개의 fine-grained 태스크와 2,388개의 인스턴스로 구성된 이미지 편집 평가용 벤치마크.
- EditReward-Compass: RL 기반 이미지 편집 최적화를 위한 2,251개의 preference pair로 구성된 리워드 모델 평가 벤치마크.
- FlowGRPO: 이미지 편집 모델을 온라인 RL로 학습시키기 위해 제안된 Flow-matching 기반 최적화 전략.
- MLLM-as-a-Judge: MLLM(Multimodal Large Language Models)을 사용하여 이미지 편집 결과물에 대해 구조화된 추론과 점수를 산출하는 평가 방식.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 최신 이미지 편집 모델의 발전 속도에 비해 기존 벤치마크가 갖는 평가 신뢰성 부족과 RL 최적화 설정의 비현실성 문제를 해결하고자 한다. 기존 연구들은 태스크 난이도가 낮거나 평가 방식이 지나치게 단편적이어서, frontier 모델들의 세밀한 성능 차이를 구분하는 데 한계가 있다. 또한, 이미지 편집 리워드 모델을 위한 기존 벤치마크들은 실제 RL 최적화 시나리오와 동떨어진 데이터 분포를 사용하여 모델의 품질을 정확하게 평가하지 못한다. 저자들은 이러한 한계를 극복하기 위해 더욱 도전적이고 인간의 판단과 정렬된 통합 평가 프레임워크를 제안한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 이미지 편집 모델과 리워드 모델을 체계적으로 평가하기 위해 Edit-Compass와 EditReward-Compass로 구성된 통합 벤치마크 제품군을 제안한다. Edit-Compass는 일반 편집부터 world knowledge reasoning, algorithmic visual reasoning, multi-image 이해 등 6개 범주의 36개 태스크를 포함하며, 구조화된 Chain-of-Thought 추론과 세밀한 scoring rubric을 도입하여 인간의 판단과 높은 정렬을 달성했다[3.1, 3.3]. EditReward-Compass는 FlowGRPO 기반의 실제 RL 시나리오를 시뮬레이션하여 2,251개의 preference pair를 구축하였다 [4.1]. 29개의 이미지 편집 모델과 21개의 리워드 모델을 대상으로 실험한 결과, 최고 성능의 proprietary 모델은 3.99점(5점 만점)을 기록한 반면, 최고의 오픈소스 모델인 Qwen-Image-Edit는 2.69점에 그쳐 유의미한 성능 격차를 보였다[5.2]. 또한, Qwen3.5와 같은 네이티브 멀티모달 모델들이 기존에 preference 데이터로 학습된 리워드 모델들보다 전반적으로 우수한 평가 성능을 보임을 확인하였다[5.2].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 frontier 이미지 편집 시스템과 리워드 모델을 평가하기 위한 포괄적이고 신뢰성 높은 벤치마크 환경을 제공한다. 실험 결과는 오픈소스와 폐쇄형 시스템 간의 성능 차이를 명확히 드러내며, 특히 reasoning-intensive한 태스크에서의 한계를 증명하였다. 이 벤치마크 제품군은 향후 이미지 편집 모델 개발의 지표가 될 것이며, 리워드 모델의 효과적인 훈련을 위한 실질적인 테스트베드 역할을 할 것으로 기대된다. 다만, 현재 API 기반의 평가 모델 사용에 의존하고 있다는 한계점이 있으며, 향후 자체적인 이미지 편집 judge 모델 개발을 통해 더욱 투명한 평가 환경을 구축할 예정이다 [6].

Figure 1 — Edit-Compass의 36개 태스크 분류
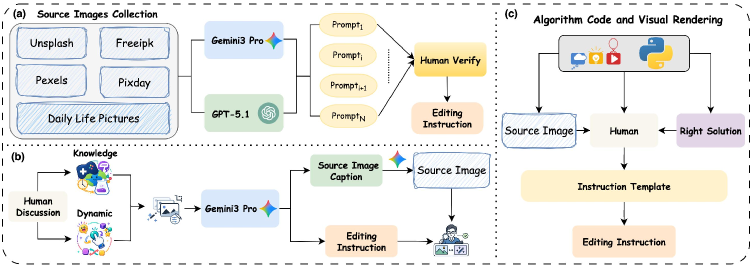
Figure 2 — 데이터 구축 파이프라인 개요
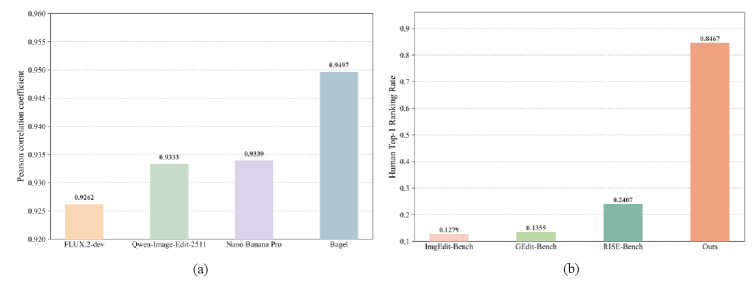
Figure 3 — 인간 정렬도 및 성능 지표 분석
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] EditScore: Unlocking Online RL for Image Editing via High-Fidelity Reward Modeling
- [논문리뷰] TRON: Targeted Rule-Verifiable Online Environments for Visual Reasoning RL
- [논문리뷰] Visual Reasoning through Tool-supervised Reinforcement Learning
- [논문리뷰] Exploring Spatial Intelligence from a Generative Perspective
- [논문리뷰] OpenVLThinkerV2: A Generalist Multimodal Reasoning Model for Multi-domain Visual Tasks
Review 의 다른글
- 이전글 [논문리뷰] Context Training with Active Information Seeking
- 현재글 : [논문리뷰] Edit-Compass & EditReward-Compass: A Unified Benchmark for Image Editing and Reward Modeling
- 다음글 [논문리뷰] F-GRPO: Factorized Group-Relative Policy Optimization for Unified Candidate Generation and Ranking
댓글