[논문리뷰] F-GRPO: Factorized Group-Relative Policy Optimization for Unified Candidate Generation and Ranking
링크: 논문 PDF로 바로 열기
메타데이터
저자: Rohan Surana, Gagan Mundada, Junda Wu, Xintong Li, Yizhu Jiao, Bowen Jin, Sizhe Zhou, Tong Yu, Ritwik Sinha, Jiawei Han, Jingbo Shang, Julian McAuley, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- F-GRPO: Slate generation(후보군 생성)과 Ranking(순위 결정)을 단일 autoregressive rollout 내에서 수행하고, 각 단계에 최적화된 개별 그룹 상대 이득(Group-Relative Advantages)을 할당하는 최적화 프레임워크.
- Slate Generation: 주어진 맥락(Context)을 바탕으로 관련 후보(Candidates)들의 집합(Slate)을 생성하는 과정.
- In-context Ranking: 생성된 후보군 내에서 utility를 최대화하기 위해 후보들을 재정렬(Ordering)하는 과정.
- Credit Assignment Gap: 단일 sequence-level reward가 후보 생성의 적절성과 순위 결정의 품질을 동시에 평가함에 따라 발생하는 학습 신호의 혼재 및 불안정성 문제.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM 기반의 검색 및 추천 시스템에서 발생하는 결합된 list-to-rank 최적화 문제를 해결하고자 한다. 기존의 Black-box LLM 접근법은 후보군 생성과 순위 결정을 단일 결과물로 출력하여 두 과정 간의 기여도를 명확히 구분하지 못하는 한계가 있다. 또한, 모듈을 분리하는 기존 파이프라인 방식은 end-to-end 최적화가 어렵고 분포 불일치(Distribution Mismatch) 문제를 유발한다 [Figure 1(a)]. 저자들은 생성과 순위 결정 과정이 독립적인 최적화 목표(포괄성 vs 위치 민감도)를 가짐에도 불구하고, 단일 reward로 학습할 경우 발생하는 cross-phase gradient contamination을 해결해야 할 핵심 문제로 정의한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 후보 생성과 순위 결정을 명시적으로 분리하되, 하나의 LLM 백본을 공유하여 end-to-end로 최적화하는 F-GRPO를 제안한다 [Figure 1(b)]. 제안 방법론은 slate content와 rank content를 delimiter 태그로 파싱한 후, 각 단계에 특화된 Group-Relative Advantages를 사용하여 독립적인 gradient 업데이트를 수행한다. 이를 통해 slate generator는 coverage 보상을, ranker는 position-aware utility 보상을 우선적으로 학습하게 된다 [Algorithm 1]. 실험 결과, F-GRPO는 Sequential Recommendation 및 Multi-hop QA 벤치마크에서 기존의 GRPO 베이스라인과 Decoupled SFT 방식을 크게 상회하는 성능을 보였다 [Table 1, Table 2]. 특히, LastFM 데이터셋에서 Recall@5 기준 GRPO 대비 +10.6%의 상대적 성능 향상을 달성했으며, 후보군 생성 품질이 중요한 환경에서 더욱 강력한 우위를 점하는 것으로 확인되었다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 LLM의 generation과 ranking을 factorized policy로 공식화하여 두 단계의 최적화 결합을 성공적으로 달성했다. F-GRPO는 기존의 단일 보상 체계가 가진 credit assignment 문제를 해결함으로써 훨씬 효율적이고 안정적인 학습을 가능하게 한다. 이 연구는 정보 검색 및 추천 시스템 분야에서 복잡한 구조적 의사결정을 자동화하려는 LLM의 적용 가능성을 높였으며, 향후 다양한 multi-stage task에 범용적으로 적용될 수 있는 이론적 기반을 제공한다.
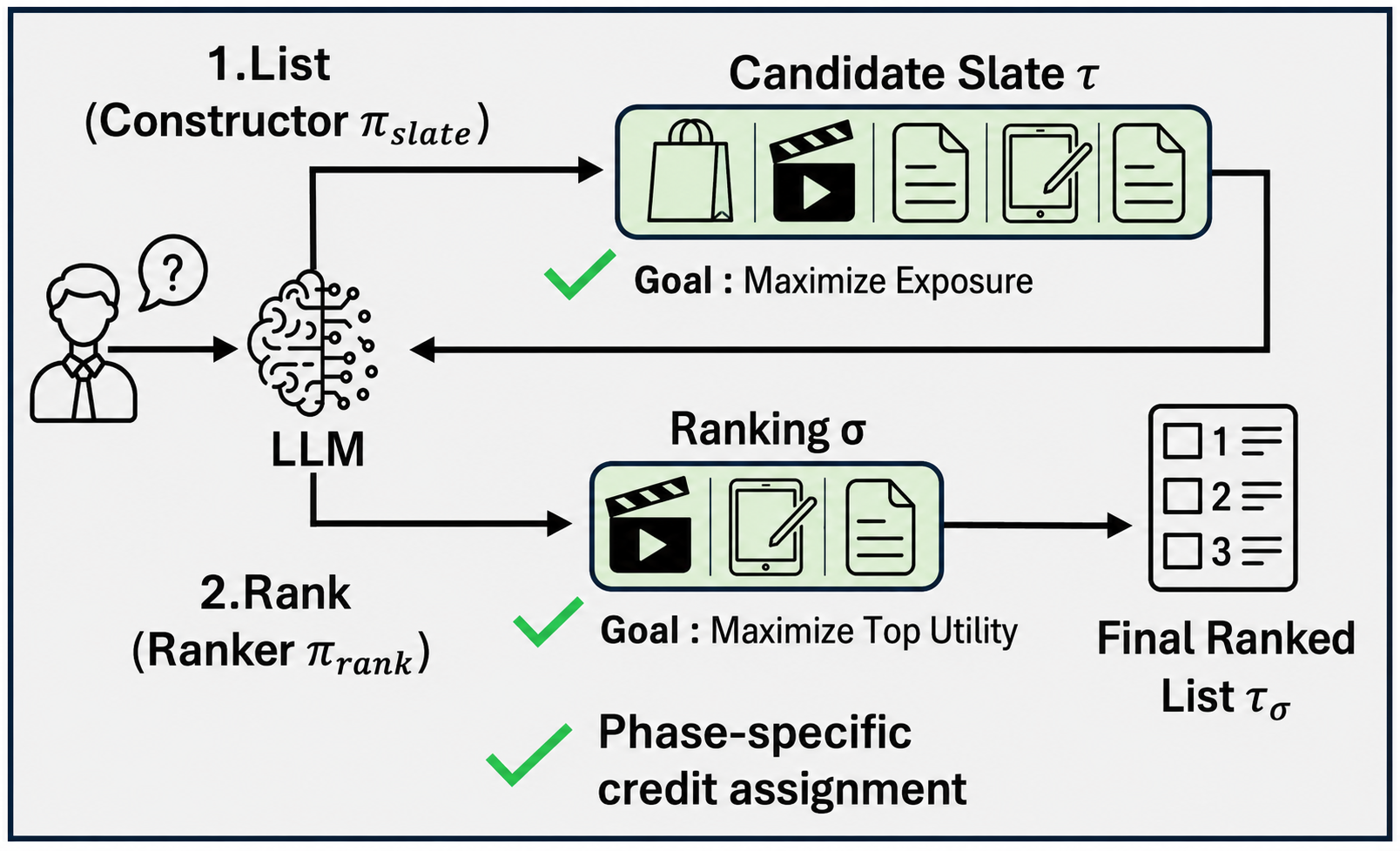
Figure 1 — F-GRPO의 아키텍처 및 분리 구조
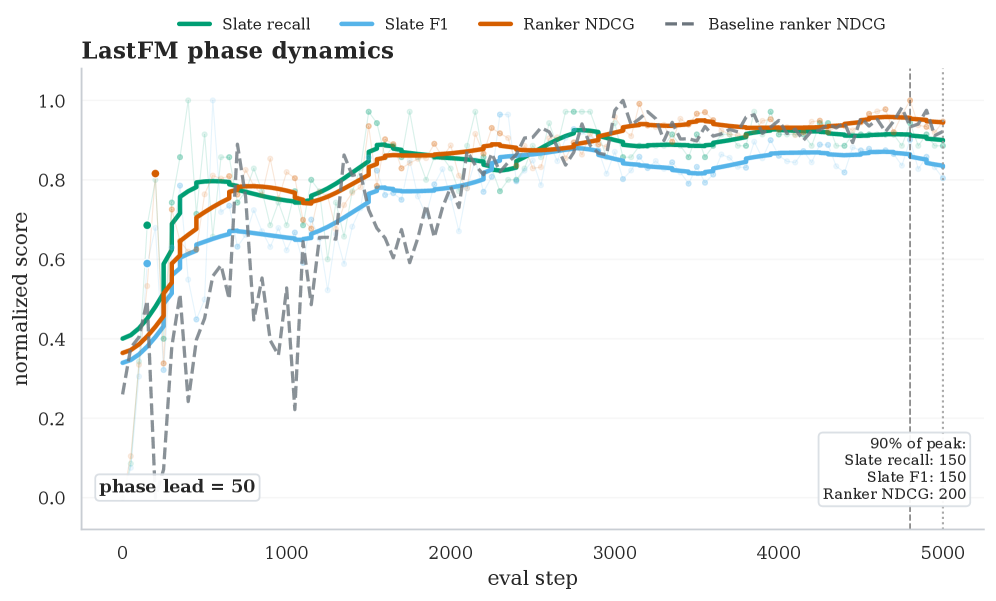
Figure 2 — 학습 단계별 모델 성숙도 분석
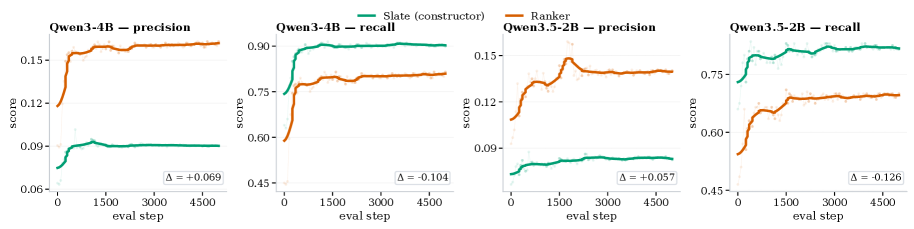
Figure 3 — 생성 및 순위 결정 간의 P-R 분포
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Anti-Self-Distillation for Reasoning RL via Pointwise Mutual Information
- [논문리뷰] RelayLLM: Efficient Reasoning via Collaborative Decoding
- [논문리뷰] SofT-GRPO: Surpassing Discrete-Token LLM Reinforcement Learning via Gumbel-Reparameterized Soft-Thinking Policy Optimization
- [논문리뷰] Compressing Chain-of-Thought in LLMs via Step Entropy
- [논문리뷰] TREK: Distill to Explore, Reinforce to Refine
Review 의 다른글
- 이전글 [논문리뷰] Edit-Compass & EditReward-Compass: A Unified Benchmark for Image Editing and Reward Modeling
- 현재글 : [논문리뷰] F-GRPO: Factorized Group-Relative Policy Optimization for Unified Candidate Generation and Ranking
- 다음글 [논문리뷰] FeatCal: Feature Calibration for Post-Merging Models
댓글