[논문리뷰] FrontierSmith: Synthesizing Open-Ended Coding Problems at Scale
링크: 논문 PDF로 바로 열기
메타데이터
저자: Runyuan He, Qiuyang Mang, Shang Zhou, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- FrontierSmith: 기존의 closed-ended 코딩 문제를 변형하여 확장 가능한 방식의 open-ended 코딩 문제로 자동 생성하는 시스템입니다.
- Idea Divergence: 문제 해결 과정에서 서로 다른 핵심 알고리즘 전략이 선택될 확률을 정량화한 지표로, open-ended 문제의 품질을 평가하는 핵심 필터입니다.
- GRPO (Group Relative Policy Optimization): 본 논문에서 모델 학습을 위해 사용한 RL 알고리즘으로, 여러 샘플 간의 상대적 보상을 통해 학습을 최적화합니다.
- Open-ended Coding: 정답이 고정된 binary 정오 판별이 불가능하며, 지속적인 품질(Continuous quality) 점수를 기반으로 평가되는 코딩 과업을 의미합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 open-ended 코딩 훈련을 위한 고품질 데이터의 부족 문제를 해결하기 위해 FrontierSmith를 제안합니다. 최근 LLM은 competitive programming과 같은 closed-ended 태스크에서 높은 성능을 보이지만, 실제 상황에서의 open-ended 과업은 최적해를 명확히 정의할 수 없어 학습 데이터 구축에 막대한 비용이 소요됩니다. 기존 연구들은 대규모 closed-ended 데이터셋을 활용하는 데 그치거나, open-ended 데이터를 수동으로 생성하는 것에 의존하여 확장성에 한계가 있었습니다. 따라서 저자들은 기존의 풍부한 closed-ended 문제를 변형하여 대규모 open-ended 문제를 자동 합성하는 프레임워크가 필요하다고 판단했습니다 [Figure 1].
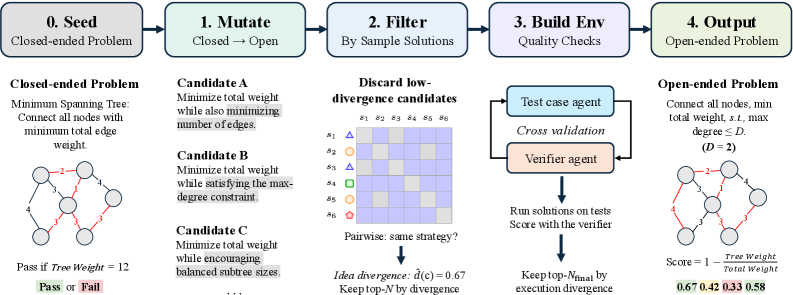
Figure 1 — FrontierSmith 파이프라인 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 closed-ended seed 문제에서 목표를 변경하거나, 출력을 제한하거나, 입력을 일반화하는 방식으로 문제를 변형하여 open-ended 변형(variants)을 생성합니다. 생성된 후보군 중에서는 idea divergence metric을 활용하여 실제 다양한 접근 방식을 유도할 수 있는 고품질 문제만을 필터링하며, 이를 위해 LLM-as-a-judge 기반 추정과 execution-grounded 추정을 병행합니다 [Figure 2]. 이후 테스트 케이스와 verifier 생성 agent를 통해 검증된 문제만을 최종 데이터셋에 포함하여 모델을 훈련합니다 [Figure 3]. Qwen3.5-9B 모델을 사용한 실험 결과, FrontierSmith 데이터로 훈련했을 때 FrontierCS 벤치마크에서 기존 대비 +8.82점, ALE-bench에서 +306.36점의 유의미한 성능 향상을 보였습니다. 또한, Qwen3.5-27B 모델에서도 각각 +12.12점, +309.12점의 성과를 거두며 수동으로 구축된 데이터셋과 대등하거나 더 뛰어난 성능을 입증하였습니다 [Table 1].
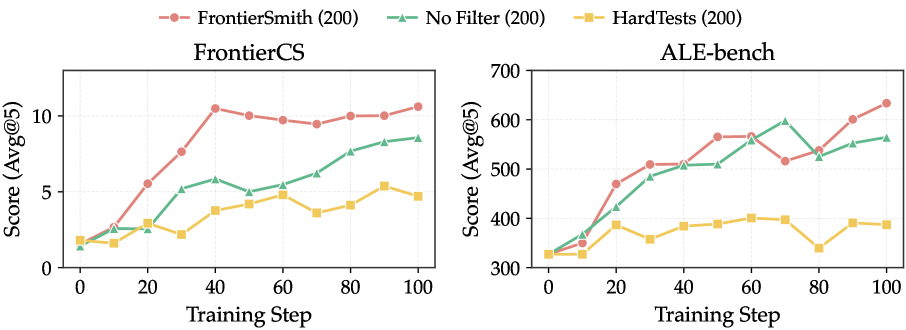
Figure 2 — Idea divergence 추정 방식
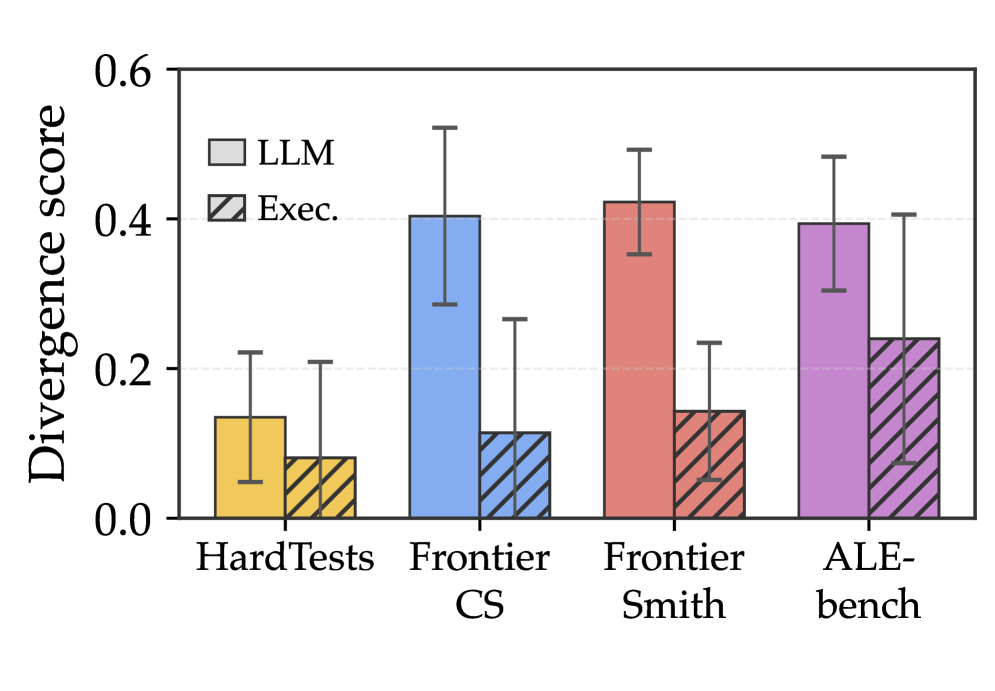
Figure 3 — 테스트 케이스 및 검증자 합성
4. Conclusion & Impact (결론 및 시사점)
본 연구는 자동화된 데이터 합성 파이프라인인 FrontierSmith를 통해 비용 효율적인 방식으로 고품질의 open-ended 코딩 훈련 데이터를 생성할 수 있음을 입증했습니다. 제안된 idea divergence 지표는 open-ended 문제의 품질을 판별하는 신뢰할 수 있는 척도로서 학계와 산업계에 기여할 수 있습니다. 또한, 합성된 문제는 에이전트에게 더 많은 Turn과 토큰 사용을 유도하는 long-horizon 행동을 이끌어내어, 향후 복잡한 에이전트 훈련의 토대가 될 것으로 기대됩니다. 이 연구는 인공지능이 실제 소프트웨어 엔지니어링이나 복잡한 최적화 과업과 같은 더 넓은 영역으로 확장되는 데 중요한 발판을 마련했습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Reinforcement Learning with Metacognitive Feedback Elicits Faithful Uncertainty Expression in LLMs
- [논문리뷰] The Hitchhiker's Guide to Agentic AI: From Foundations to Systems
- [논문리뷰] Zone of Proximal Policy Optimization: Teacher in Prompts, Not Gradients
- [논문리뷰] Anti-Self-Distillation for Reasoning RL via Pointwise Mutual Information
- [논문리뷰] F-GRPO: Factorized Group-Relative Policy Optimization for Unified Candidate Generation and Ranking
Review 의 다른글
- 이전글 [논문리뷰] Forcing-KV: Hybrid KV Cache Compression for Efficient Autoregressive Video Diffusion Models
- 현재글 : [논문리뷰] FrontierSmith: Synthesizing Open-Ended Coding Problems at Scale
- 다음글 [논문리뷰] FutureSim: Replaying World Events to Evaluate Adaptive Agents
댓글