[논문리뷰] Forcing-KV: Hybrid KV Cache Compression for Efficient Autoregressive Video Diffusion Models
링크: 논문 PDF로 바로 열기
저자: Yicheng Ji, Zhizhou Zhong, Jun Zhang, Qin Yang, XiTai Jin, Ying Qin, Wenhan Luo, Shuiyang Mao, Wei Liu, Huan Li
1. Key Terms & Definitions (핵심 용어 및 정의)
- AR (Autoregressive) Video Diffusion Models: 비디오 프레임을 한 번에 생성하지 않고, chunk 단위로 순차적으로 생성하며 이전 생성 결과를 KV Cache에 저장하여 조건으로 활용하는 생성 모델 프레임워크입니다.
- KV Cache: 이전 프레임들의 연산 정보를 담고 있는 핵심 메모리 공간으로, 생성된 영상이 길어질수록 메모리 점유율과 연산 복잡도가 비약적으로 상승하는 원인이 됩니다.
- Static Heads: 현재 생성 중인 chunk와 가장 최근 프레임인 Transition Anchor Frame에 주로 집중하여 프레임 내부의 일관성 및 chunk 간 전환을 담당하는 어텐션 헤드입니다.
- Dynamic Heads: 동일한 공간적 영역의 프레임 간 상관관계를 학습하여 모션 역학(Motion Dynamics) 및 객체 일관성을 담당하는 어텐션 헤드입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 AR 비디오 확산 모델에서 발생하는 과도한 어텐션 연산 복잡도와 메모리 오버헤드 문제를 해결하고자 합니다. 기존 모델들은 생성된 프레임이 축적될수록 전체 KV Cache를 참조하도록 강제되어, 고해상도 및 장기 비디오 생성 시 효율성이 극도로 저하되는 한계가 있습니다 [Figure 1]. 또한, 기존의 단순한 sparse attention이나 전체 캐시 유지 방식은 비디오 생성 시 필요한 시간적 연속성(temporal continuity)을 희생시키거나, chunk 간 경계에서 불연속성(flickering)을 야기합니다. 따라서, 모델의 성능을 유지하면서도 효율적으로 캐시를 압축할 수 있는 새로운 메커니즘의 도입이 필수적입니다.
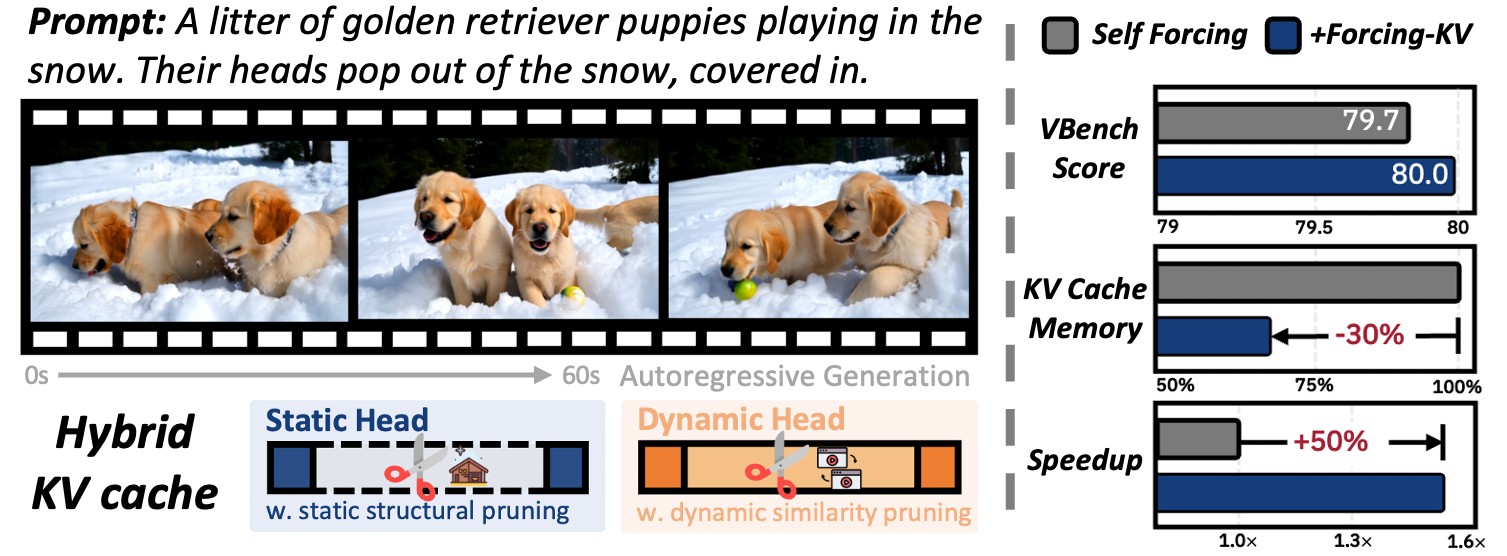
Figure 1 — Forcing-KV 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 어텐션 헤드의 기능적 차이를 기반으로 한 하이브리드 압축 프레임워크인 Forcing-KV를 제안합니다. 저자들은 실험을 통해 어텐션 헤드가 Static과 Dynamic으로 뚜렷하게 구분되며, 이러한 특성이 샘플 및 디노이징 단계 전반에 걸쳐 안정적임을 발견했습니다 [Figure 2], [Figure 3]. Forcing-KV는 Offline Head Profiling을 통해 헤드를 분류한 뒤, Static Heads에는 캐시의 구조적 특징을 활용한 Static Structural Pruning을, Dynamic Heads에는 프레임 간 유사도를 기반으로 한 Dynamic Similarity Pruning을 적용합니다 [Figure 4]. 주요 실험 결과, LongLive 및 Self Forcing 모델에서 Full KV Cache 설정 대비 30%의 메모리 감소와 함께 480P 기준 최대 1.50×의 속도 향상을 달성했습니다 [Table 1]. 또한, 1080P 고해상도 환경에서는 최대 2.82×의 속도 향상을 보이며 압축 효율성이 영상 해상도에 따라 더욱 극대화됨을 입증했습니다 [Figure 5].

Figure 2 — 어텐션 헤드 패턴
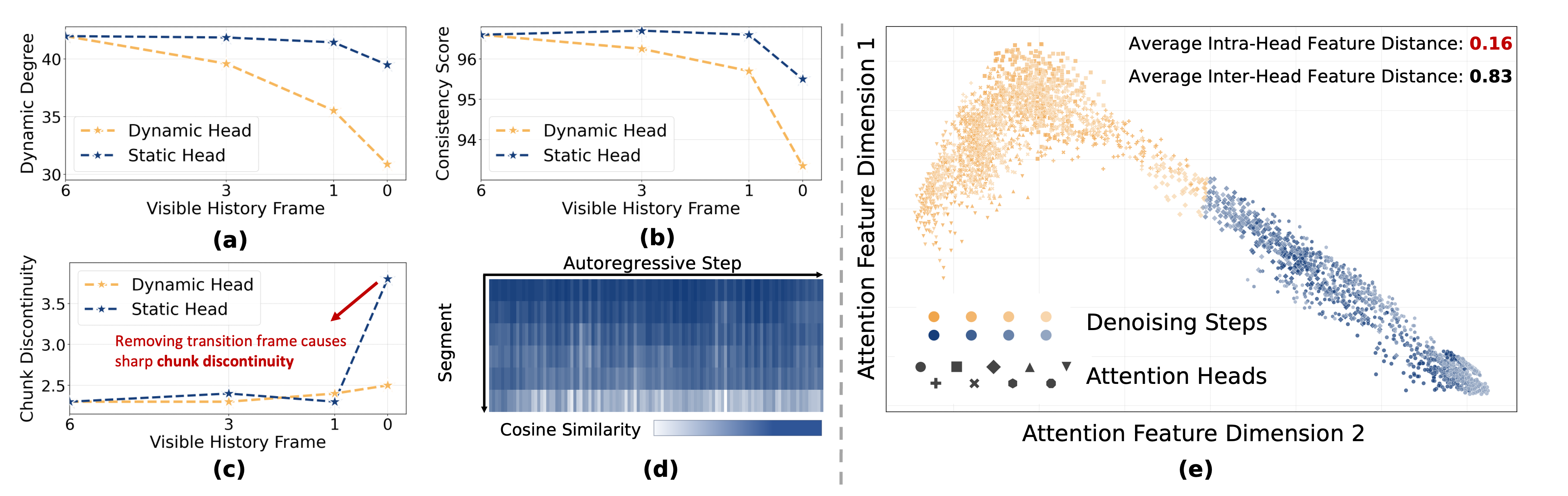
Figure 4 — 압축 전략 프로세스
4. Conclusion & Impact (결론 및 시사점)
본 논문은 AR 비디오 생성 모델에서 헤드별 기능적 특성을 규명하고, 이를 활용한 Forcing-KV를 통해 실시간성을 확보함과 동시에 비디오 품질을 보존하는 획기적인 솔루션을 제시했습니다. 이 연구는 고해상도 및 장기 비디오 생성의 scalability를 실질적으로 개선했으며, 어텐션 헤드의 구조적 이해를 바탕으로 한 지능형 캐시 관리 기법이 향후 영상 생성 모델의 배포와 최적화에 중요한 가이드라인을 제공할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] KVpop -- Key-Value Cache Compression with Predictive Online Pruning
- [논문리뷰] ReFreeKV: Towards Threshold-Free KV Cache Compression
- [논문리뷰] Nemotron-Labs-Diffusion: A Tri-Mode Language Model Unifying Autoregressive, Diffusion, and Self-Speculation Decoding
- [논문리뷰] GigaWorld-1: A Roadmap to Build World Models for Robot Policy Evaluation
- [논문리뷰] OrbitQuant: Data-Agnostic Quantization for Image and Video Diffusion Transformers
Review 의 다른글
- 이전글 [논문리뷰] EvolveMem:Self-Evolving Memory Architecture via AutoResearch for LLM Agents
- 현재글 : [논문리뷰] Forcing-KV: Hybrid KV Cache Compression for Efficient Autoregressive Video Diffusion Models
- 다음글 [논문리뷰] FrontierSmith: Synthesizing Open-Ended Coding Problems at Scale
댓글