[논문리뷰] Warp-as-History: Generalizable Camera-Controlled Video Generation from One Training Video
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yifan Wang, Tong He, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Warp-as-History: 카메라 시점 변환(warp) 정보를 일반적인 비디오 히스토리(history) 경로를 통해 모델에 주입하는 컨디셔닝 인터페이스입니다.
- Camera-warped Pseudo-history: 특정 카메라 궤적에 따라 재구성된 장면을 프레임 단위로 변환하여 모델이 학습한 기존 히스토리 경로에 맞게 패키징한 시각적 근거(evidence)입니다.
- LoRA (Low-rank Adaptation): 비디오 생성 모델의 전체 파라미터를 업데이트하지 않고, 사전 학습된 모델에 최소한의 파라미터를 추가하여 특정 카메라 제어 행동을 안정화하는 경량화 학습 기법입니다.
- Target-frame Positional Alignment: 워프(warp) 처리된 프레임 토큰의 위치 인코딩을 현재 디노이징(denoising) 중인 타겟 프레임의 위치 인코딩과 정렬하여 일관성을 높이는 기술입니다.
- Visible-token Selection: 가시성 마스크를 기반으로 정보가 유효하지 않은 워프 영역의 토큰을 제거함으로써, 모델이 불완전한 지식 대신 생성적 우선순위(generative prior)를 사용하여 장면을 완성하도록 유도하는 기법입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 대규모 카메라 주석 데이터셋이나 복잡한 아키텍처 수정 없이, 사전 학습된 비디오 생성 모델의 잠재적 카메라 제어 능력을 활용하는 효율적인 방법을 제안합니다. 기존의 카메라 제어 연구들은 카메라 인코더나 전용 제어 브랜치 등 추가적인 모듈을 필요로 하거나, 추론 단계에서 무거운 최적화(test-time optimization)를 요구하는 한계가 있었습니다. 저자들은 많은 비디오 생성 모델이 이미 히스토리 정보를 통해 장면의 연속성을 파악하는 능력을 보유하고 있다는 점에 주목했습니다 [Figure 2]. 이러한 사전 학습된 히스토리 경로를 카메라 제어를 위한 인터페이스로 재활용함으로써, 추가적인 아키텍처 수정 없이도 카메라 궤적을 효과적으로 따를 수 있는 프레임워크를 구축하고자 했습니다 [Figure 3].

Figure 2 — 제로샷 및 파인튜닝 모델 비교
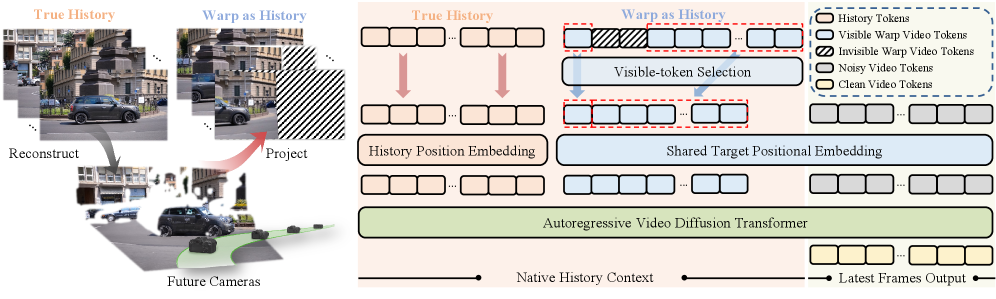
Figure 3 — 제안 모델의 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 카메라 궤적을 카메라 워프 비디오로 변환한 뒤, 이를 히스토리 경로에 주입하는 Warp-as-History 인터페이스를 핵심 방법론으로 제안합니다. 제안된 인터페이스는 타겟 프레임과의 위치 정렬(positional alignment) 및 가시성 기반의 토큰 선택(visible-token selection)을 통해 워프 데이터의 기하학적 오류를 효과적으로 처리합니다 [Figure 3]. 모델은 이 가공된 pseudo-history를 소비하며 카메라 제어 능력을 zero-shot으로 발휘하며, 단 한 편의 비디오를 이용한 경량 LoRA 파인튜닝을 통해 이러한 거동을 더욱 안정화합니다. 실험 결과, 제안 모델은 WorldScore, RE10K, DAVIS 벤치마크에서 기존의 대규모 데이터로 학습된 SOTA 모델들과 비교하여 대등하거나 우수한 카메라 추종 성능을 입증했습니다 [Table 1, Table 3]. 특히 DAVIS 데이터셋에서 기존 대비 뛰어난 FID/FVD 점수와 안정적인 시각적 품질, 그리고 독립적인 객체 이동 능력을 유지하면서도 정밀한 카메라 제어를 달성하는 정량적 우위를 보였습니다 [Table 4].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 사전 학습된 히스토리 컨디셔닝 경로가 카메라 제어를 위한 강력한 잠재적 인터페이스가 될 수 있음을 입증하며, 저비용 파인튜닝만으로 복잡한 제어 요구사항을 해결할 수 있음을 보여주었습니다. 이는 비디오 생성 모델의 활용성을 극대화함과 동시에, 막대한 학습 비용이 드는 모델 구조 설계에서 벗어나 기존 모델의 잠재력을 극대화하는 새로운 연구 방향을 제시합니다. 본 방법론은 인터랙티브 미디어, 가상 현실, 시뮬레이션 등 고도의 카메라 제어가 필요한 학계 및 산업계 전반에 걸쳐 효율적인 솔루션으로 활용될 것으로 기대됩니다.

Figure 4 — 외부 베이스라인 정성적 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OmniDirector: General Multi-Shot Camera Cloning without Cross-Paired Data
- [논문리뷰] SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer
- [논문리뷰] DynaVid: Learning to Generate Highly Dynamic Videos using Synthetic Motion Data
- [논문리뷰] WorldStereo: Bridging Camera-Guided Video Generation and Scene Reconstruction via 3D Geometric Memories
- [논문리뷰] Generated Reality: Human-centric World Simulation using Interactive Video Generation with Hand and Camera Control
Review 의 다른글
- 이전글 [논문리뷰] ViMU: Benchmarking Video Metaphorical Understanding
- 현재글 : [논문리뷰] Warp-as-History: Generalizable Camera-Controlled Video Generation from One Training Video
- 다음글 [논문리뷰] WildClawBench: A Benchmark for Real-World, Long-Horizon Agent Evaluation
댓글